Python之微博信息爬取
作者:互联网
源代码:https://github.com/dataabc/weiboSpider
本程序可以连续爬取一个或多个新浪微博用户的数据,并将结果信息写入文件或数据库。此处作为论文数据应用。
首先进入GitHub下载代码至本地。
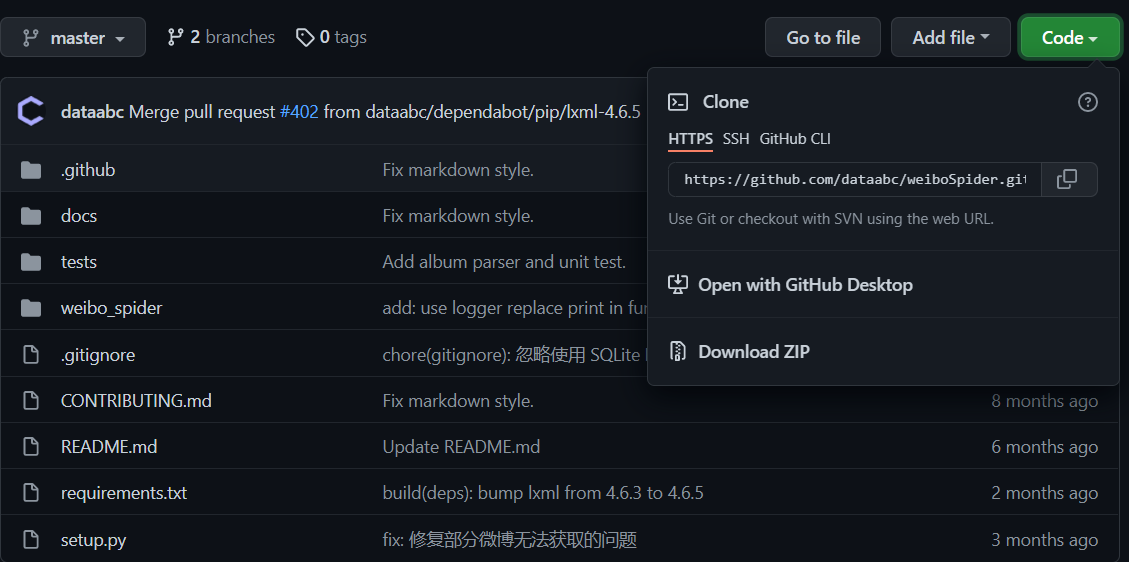
将该程序导入进PyCharm,此处的readme类似说明书,根据说明进行增删改查即可,config是需要配置的内容(根据自己需要爬取的内容)。
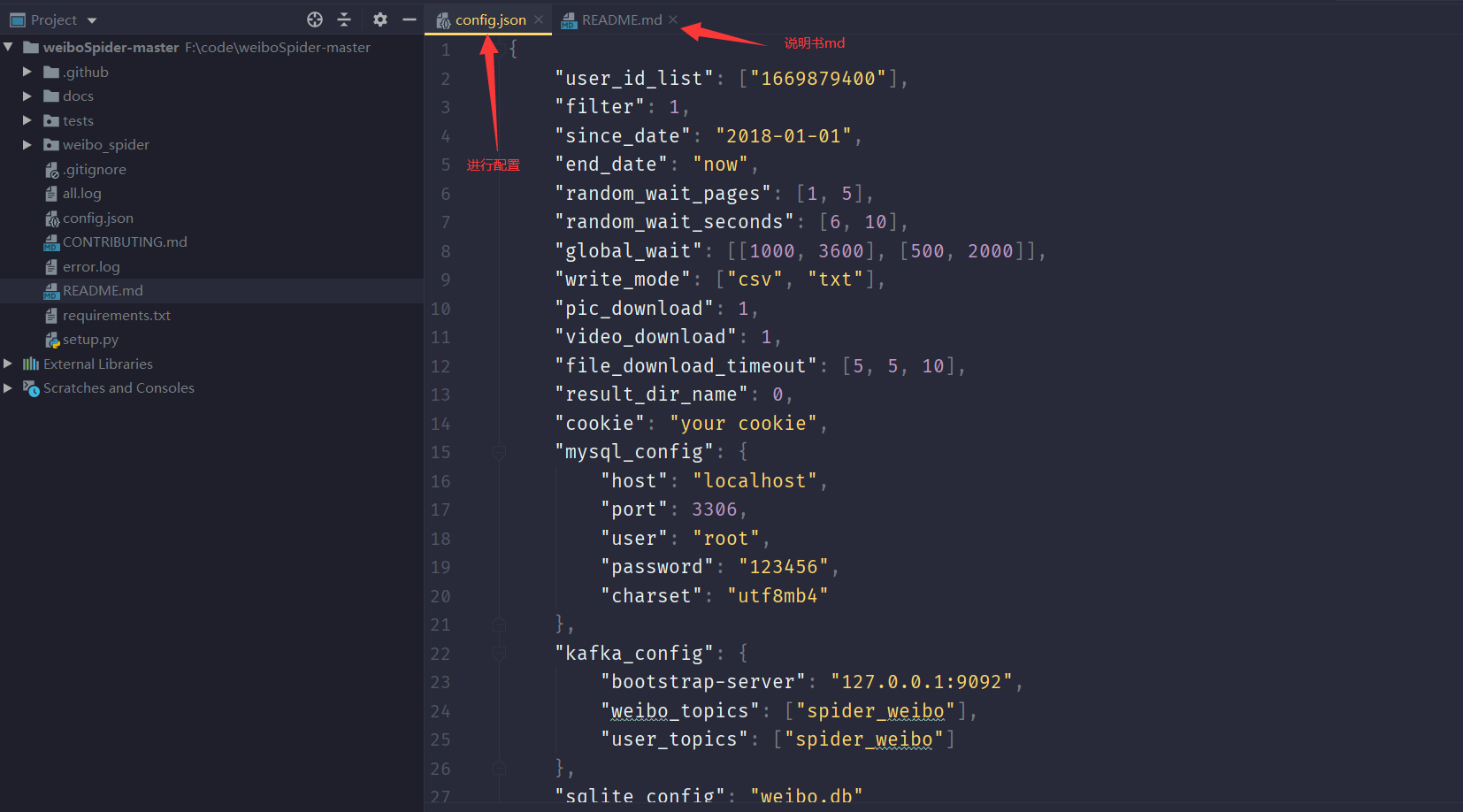
需要的配置如下:
打开cmd,进行pip install
lxml == 4.6.5
requests == 2.23.0
tqdm == 4.46.1
absl-py == 0.9.0
进行实例爬取,以爬取苏炳添的微博存储为.csv文件为例,我们需要修改config.json文件,文件内容如下:
{
"user_id_list": ["2029906001"],
"filter": 1,
"since_date": "2008-01-01",
"end_date": "now",
"random_wait_pages": [1, 5],
"random_wait_seconds": [6, 10],
"global_wait": [[1000, 3600], [500, 2000]],
"write_mode": ["csv"],
"pic_download": 1,
"video_download": 0,
"file_download_timeout": [5, 5, 10],
"result_dir_name": 0,
"cookie": "your cookie"
}
解释如下:
- user_id_list代表我要爬取的微博用户的user_id,可以是一个或多个,也可以是文件路径,微博用户苏炳添的user_id为2029906001,具体如何获取user_id见docs文件夹下userid.md文件;
- filter的值为1代表爬取全部原创微博,值为0代表爬取全部微博(原创+转发);
- since_date代表我们要爬取since_date日期之后发布的微博,因为我要爬苏炳添的2008年以后的原创微博,所以since_date设置了为2008-01-01;
- end_date代表我们要爬取end_date日期之前发布的微博,since_date配合end_date,表示我们要爬取发布日期在since_date和end_date之间的微博,包含边界,如果end_date值为"now",表示爬取发布日期从since_date到现在的微博;
- write_mode代表结果文件的保存类型,我想要把结果写入csv文件,所以它的值为["csv"],如果你想写入其他,参考原始config.json文件即可,也可参考docs文件夹下settings.md;
- pic_download值为1代表下载微博中的图片,值为0代表不下载;
- video_download值为1代表下载微博中的视频,值为0代表不下载;
- result_dir_name控制结果文件夹名,值为1代表文件夹名是用户id,值为0代表文件夹名是用户昵称;
- cookie是爬虫微博的cookie,具体如何获取cookie可以参考docs文件夹下cookie.md,获取cookie后把"your cookie"替换成真实的cookie值即可(这里隐私就不写出来,非常简单哦)。
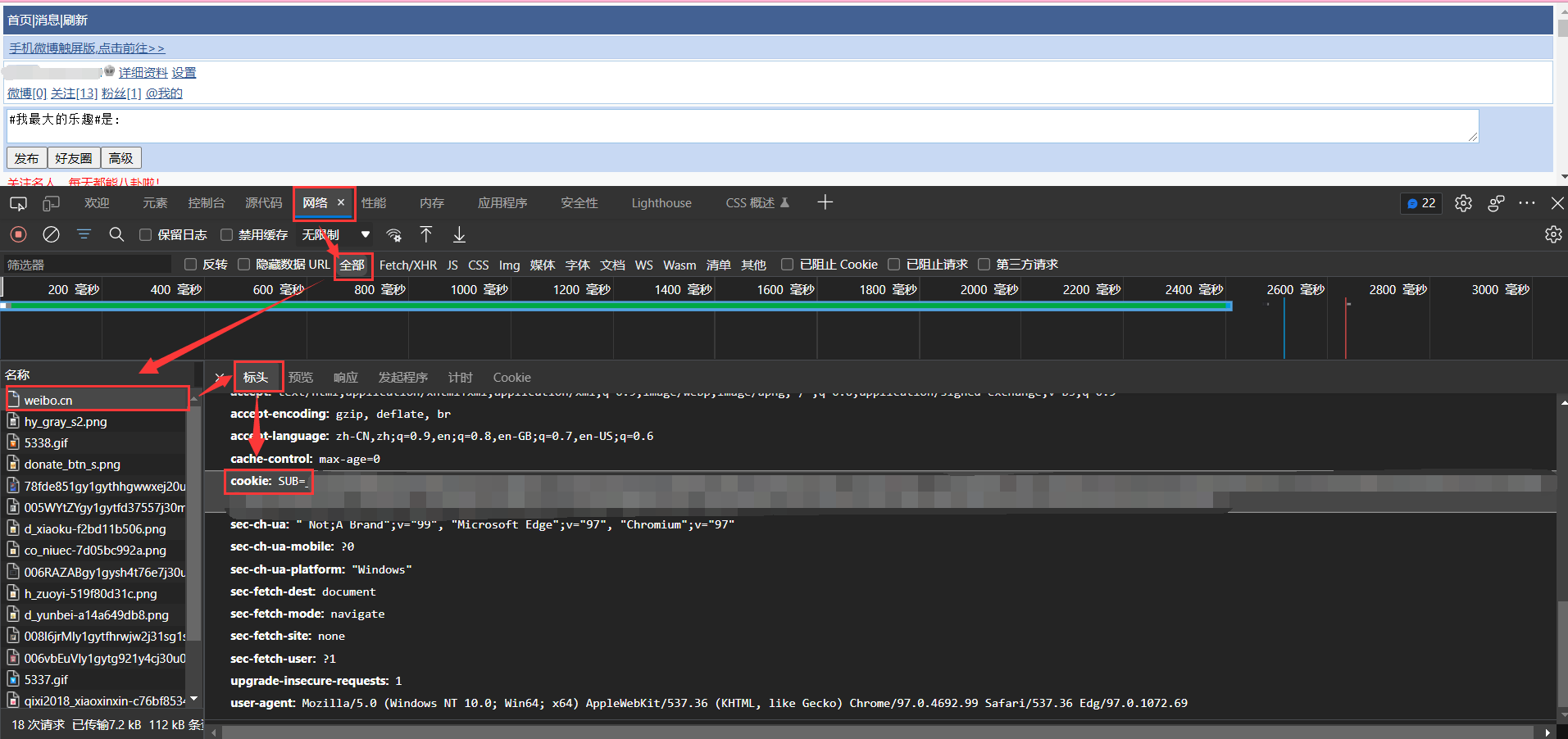
接下来进行程序运行:
首先必须在cmd将目录转移到weiboSpider-master的目录,比如进入cmd后:
f:
cd code\weiboSpider-master
接下来运行:
python -m weibo_spider
完工!!!时间可能会很长,耐心等待下载即可!效果如下:
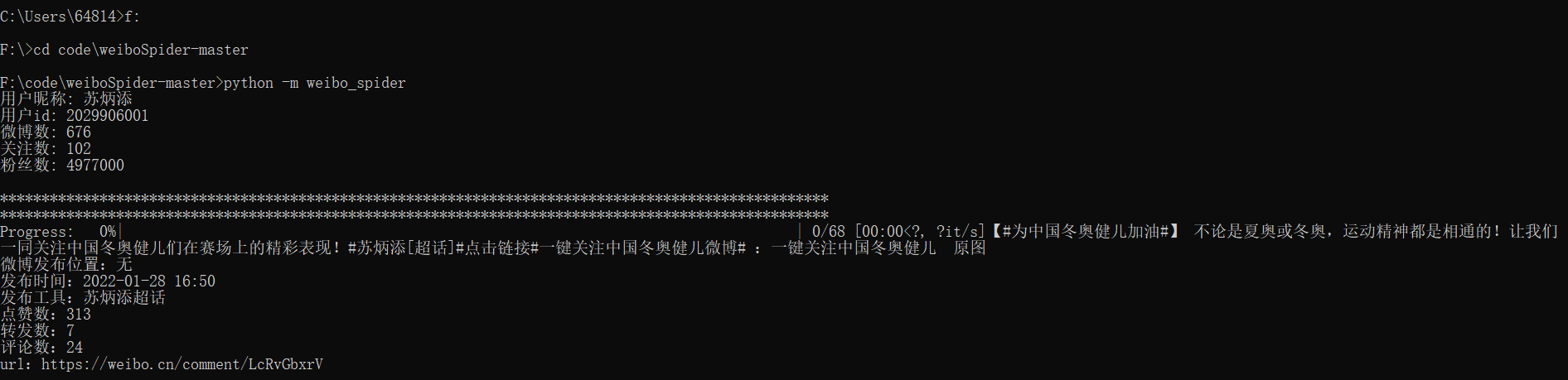

数据展示如下(苏神数据只到2015年):
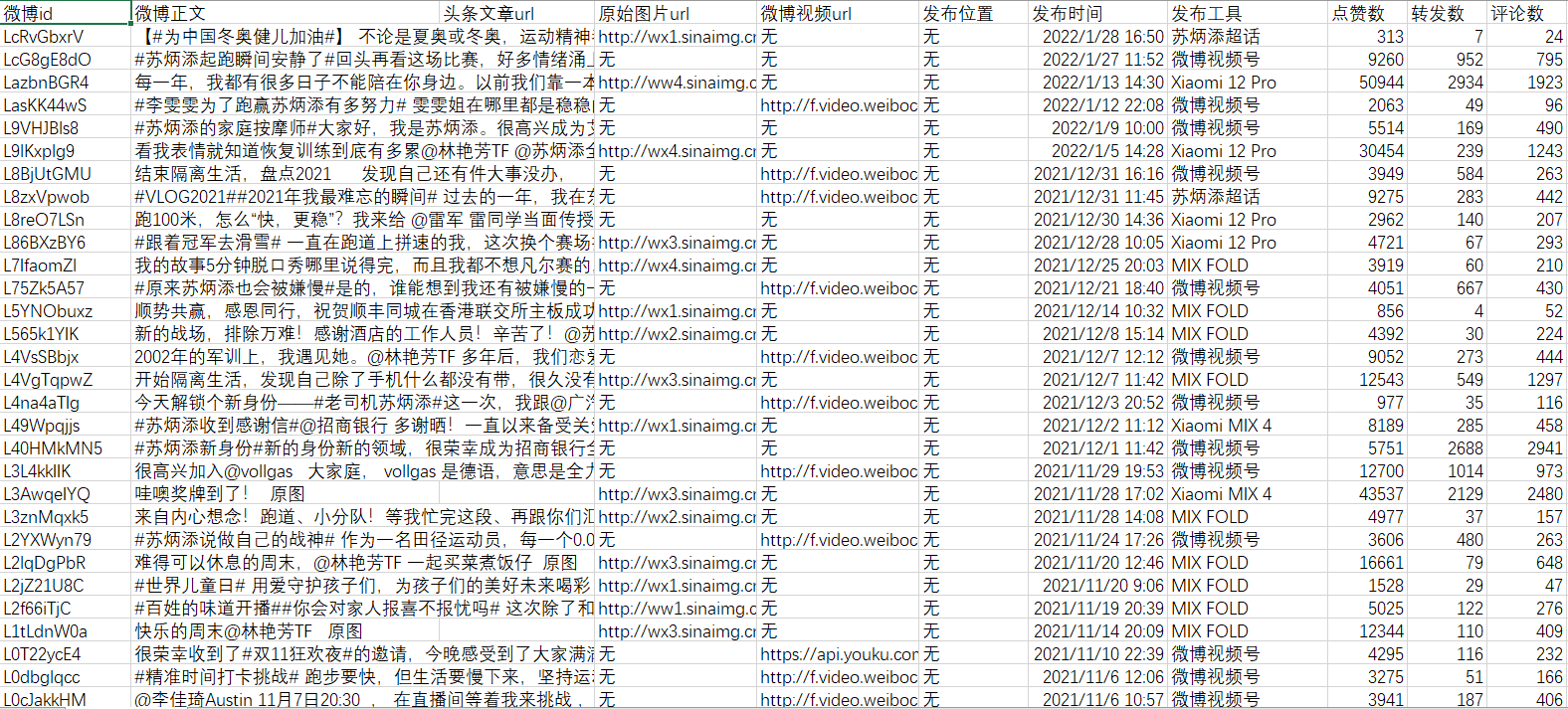
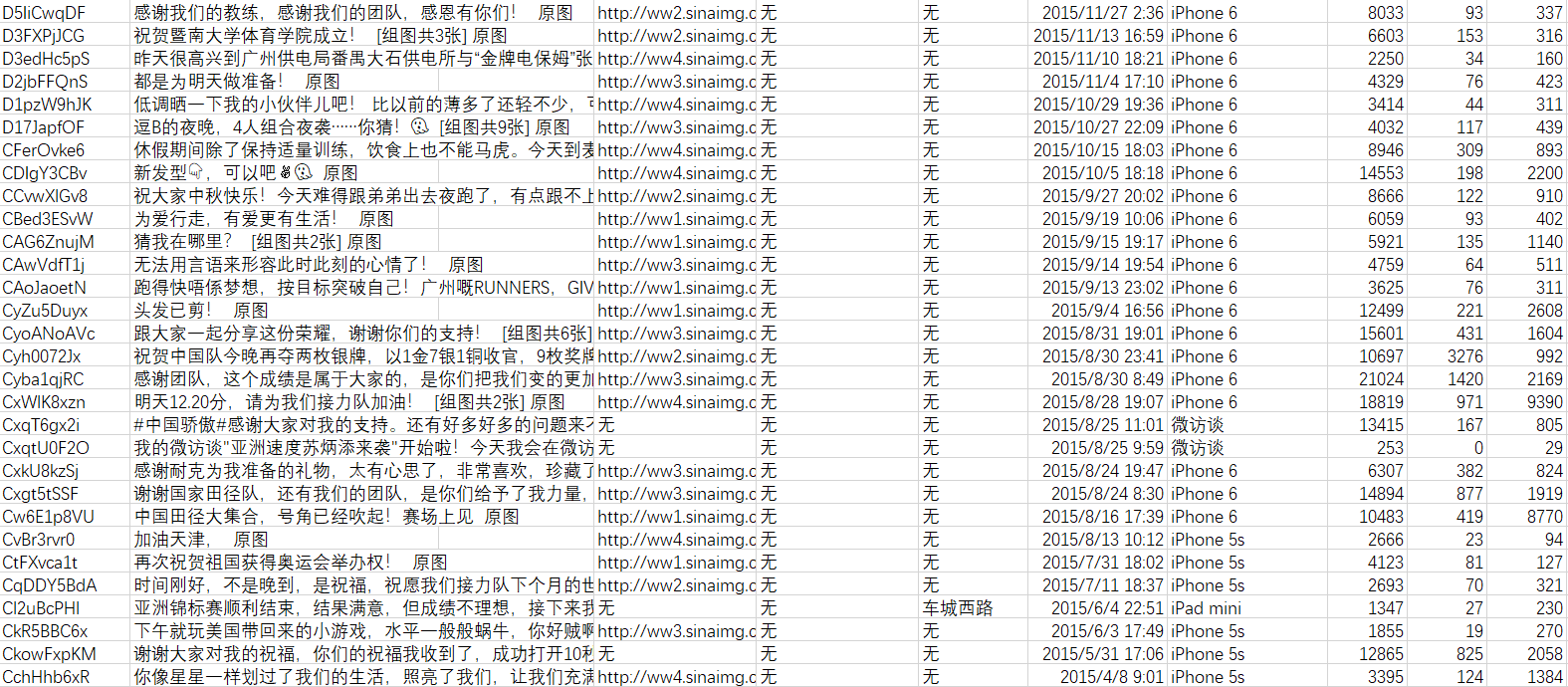
本项目提出的一些常见问题:
1、程序运行出错,错误提示中包含“ImportError: cannot import name 'config_util' from 'main'”,如何解决?
出现这种错误,说明使用者很可能是直接运行的.py文件,程序正确的运行方式是在weiboSpider目录下,运行如下命令:
python -m weibo_spider
2、程序运行出错,错误提示中包含“'NoneType' object”字样,如何解决?
这是最常见的问题之一。出错原因是爬取速度太快,被暂时限制了,限制可能包含爬虫账号限制和ip限制。一般情况下,一段时间后限制会自动解除。可通过降低爬取速度避免被限制,具体修改config.json文件中的如下代码:
"random_wait_pages": [1, 5],
"random_wait_seconds": [6, 10],
"global_wait": [[1000, 3600], [500, 2000]],
前两行的意思是每爬取1到5页,随机等待6到10秒。可以通过加快暂停频率(减小random_wait_pages内的值)或增加等待时间(加大random_wait_seconds内的值)避免被限制。最后一行的意思是获取1000页微博,一次性等待3600秒;之后获取500页微博一次性等待2000秒。默认只有两个global_wait配置([1000, 3600]和[500, 2000]),可以添加更多个,也可以自定义。当配置使用完,如默认配置在获取1500(1000+500)页微博后就用完了,之后程序会从第一个配置开始循环使用(获取第1501页到2500页等待3600秒,获取第2501页到第3000页等待2000秒,以此类推)。
3、如何获取微博评论?
因为限制,只能获取一部分评论,无法获取全部,因此暂时没有添加获取评论功能的计划。
4、有的长微博正文只能获取一部分内容,如何解决?
程序是可以获取长微博全文的。程序首先在微博列表页获取微博,如果发现长微博(正文没有显示完整,以“全文”代替部分内容的微博),会先保存这个不全的内容,然后去该长微博的详情页尝试获取全文,如果获取成功,获取的内容就是微博文本;如果获取失败,等待若干秒重新获取;如果连续尝试5次都失败,就用上面不全的内容代替。这样做的原因是避免因部分长微博获取失败而卡住。如果想尝试更多次,可以修改comment_parser.py文件get_long_weibo方法内for循环的次数。
5、如何按指定关键词获取微博?
请使用weibo-search。该程序可以连续获取一个或多个微博关键词搜索结果,并将结果写入文件(可选)、数据库(可选)等。所谓微博关键词搜索即:搜索正文中包含指定关键词的微博,可以指定搜索的时间范围。对于非常热门的关键词,一天的时间范围,可以获得1000万以上的搜索结果,N天的时间范围就可以获得1000万 X N搜索结果。对于大多数关键词,一天产生的相应微博数量应该在1000万条以下,因此可以说该程序可以获得大部分关键词的全部或近似全部的搜索结果。而且该程序可以获得搜索结果的所有信息,本程序获得的微博信息该程序都能获得。
6、如何获取微博用户关注列表中用户的user_id?
请使用weibo-follow。该程序可以利用一个user_id,获取该user_id微博用户关注人的user_id,一个user_id最多可以获得200个user_id,并写入user_id_list.txt文件。程序支持读文件,利用这200个user_id,可以获得最多200X200=40000个user_id。再利用这40000个user_id可以得到40000X200=8000000个user_id,如此反复,以此类推,可以获得大量user_id。本项目也支持读文件,将上述程序的结果文件user_id_list.txt路径赋值给本项目config.json的user_id_list参数,就可以获得这些user_id用户所发布的大量微博。
7、如何获取自己的微博?
修改page_parser.py中__init__方法,将self.url修改为:
self.url = "https://weibo.cn/%s/profile?page=%d" % (user_uri, page)
标签:Python,爬取,获取,微博,之微博,user,date,cookie,id 来源: https://www.cnblogs.com/wangzheming35/p/15853407.html