【Python】完美采集某宝数据,到底A和B哪个是YYDS?(附完整源代码和视频教程)
作者:互联网
目录
前言
准备
分析(x0)
分析(x1)
分析(x2)
分析(x3)
分析(x4)
总结
我有话说
前言
大家好,我叫善念。不说漂亮话,直接开始今天要采集的目标:某宝数据
今天要采用的方式是selenium自动化工具。
简单说下selenium的原理——利用网页元素控制浏览器。
准备
安装selenium模块:
pip install selenium
我采用的是利用selenium控制Chrome浏览器,所以咱们需要下载一个selenium与Chrome的桥梁——Chromedriver插件
下载地址
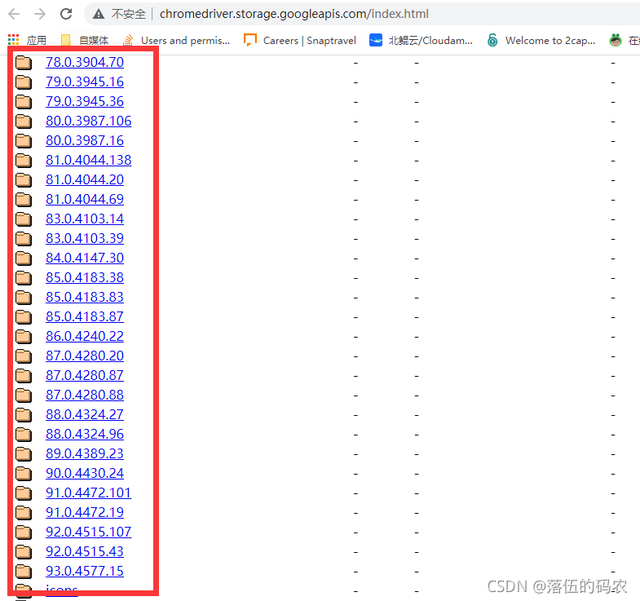
下载与你当前谷歌浏览器版本最相近的Chromedriver
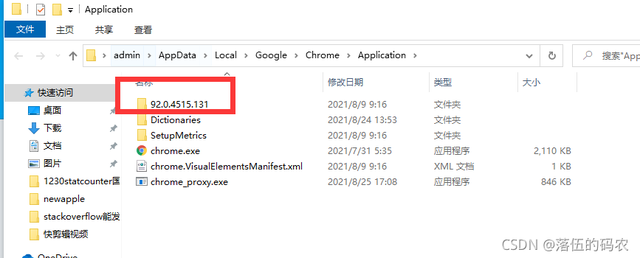
那么像我的话,下载
即可。
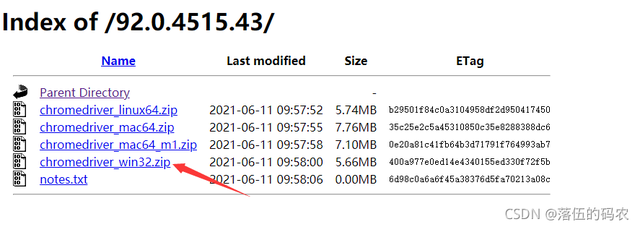
Windows系统需下载32位,其它的自己看着办。点进去下载win32即可。
那么如何让Python与selenium连接起来呢,这里咱们需要配置一个环境变量,就是把Python与selenium处于同一个目录:

到此为止,咱们的环境就搭建好了。
分析(x0)
登录篇
谈谈selenium与requests的区别:
selenium:操控网页元素,模拟人去控制浏览器,放弃与底层协议的交互,控制于客户端表面(速度慢)
requests:模拟客户端向服务器发送协议请求,处于底层协议的交互。(速度快)
既然是模拟人去控制浏览器就好说了,想要采集某个网站第一步是做什么?
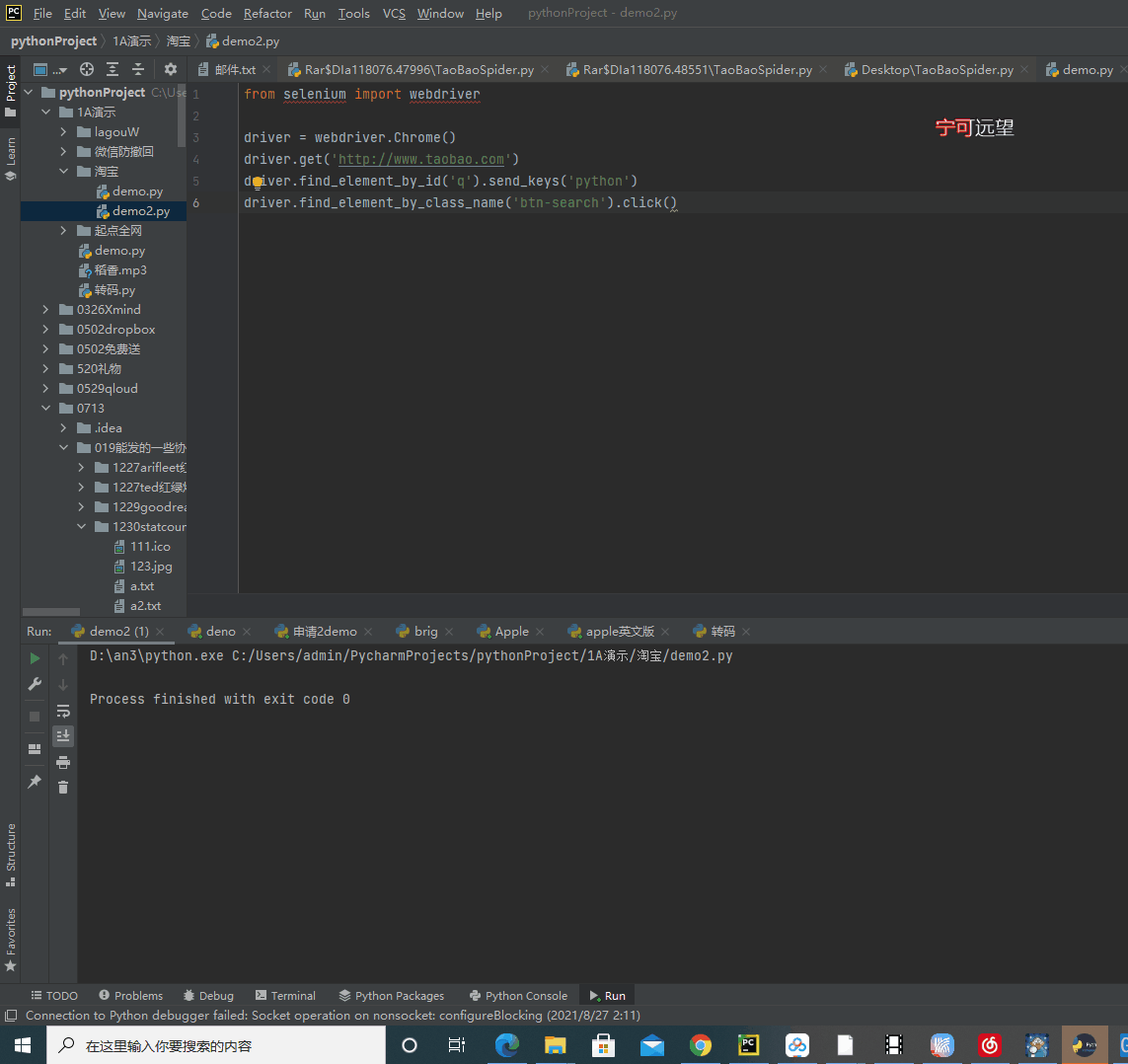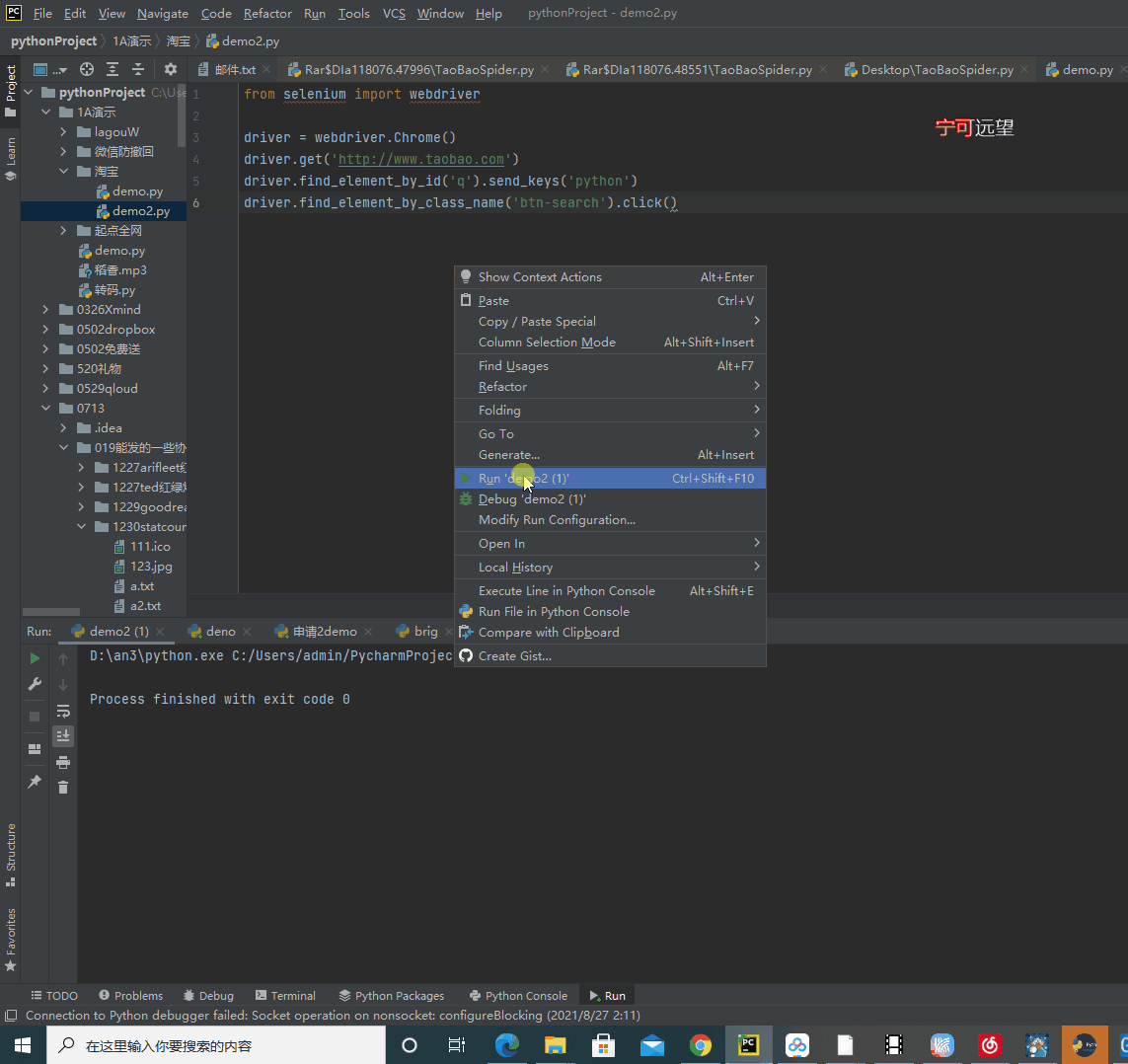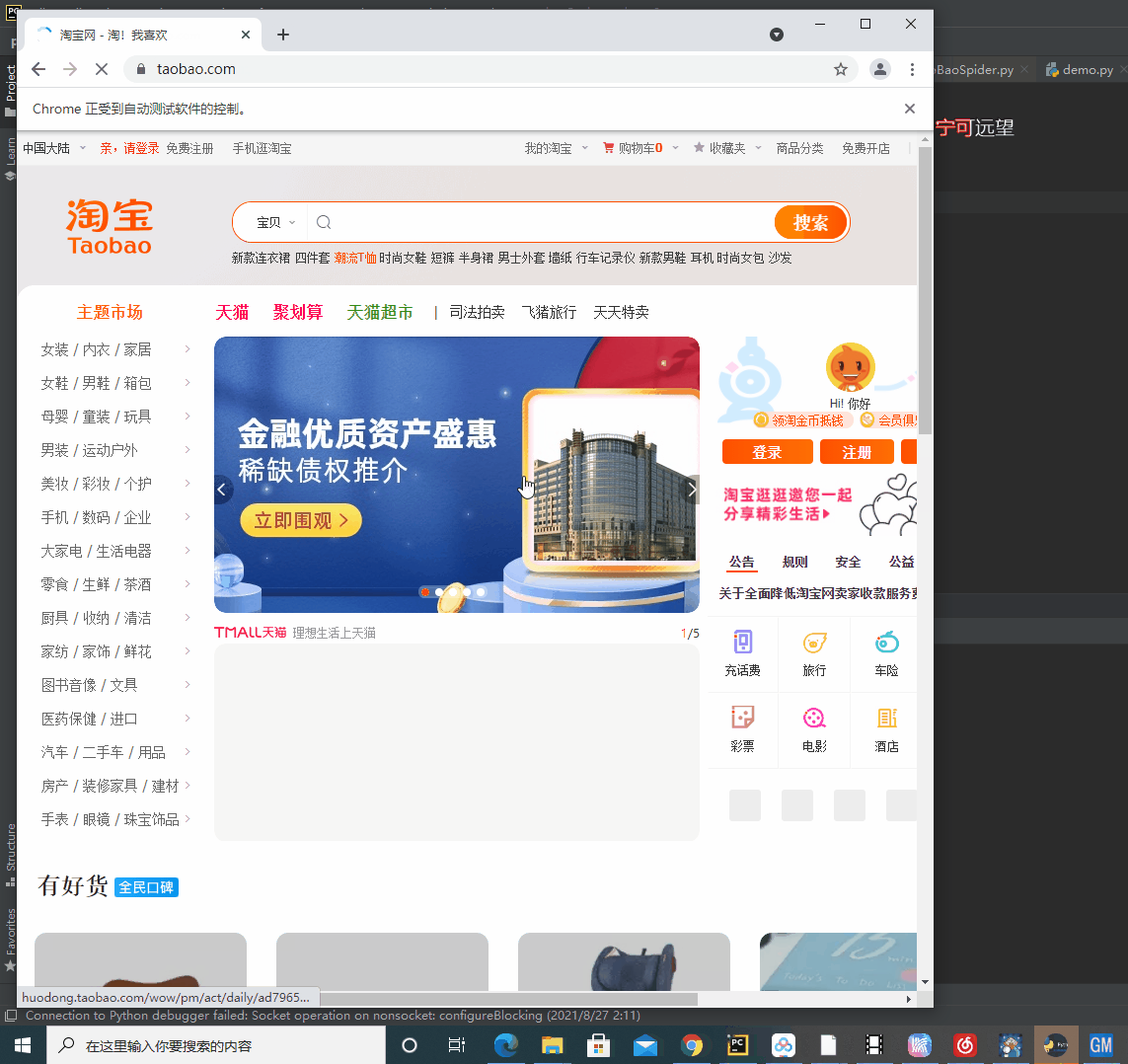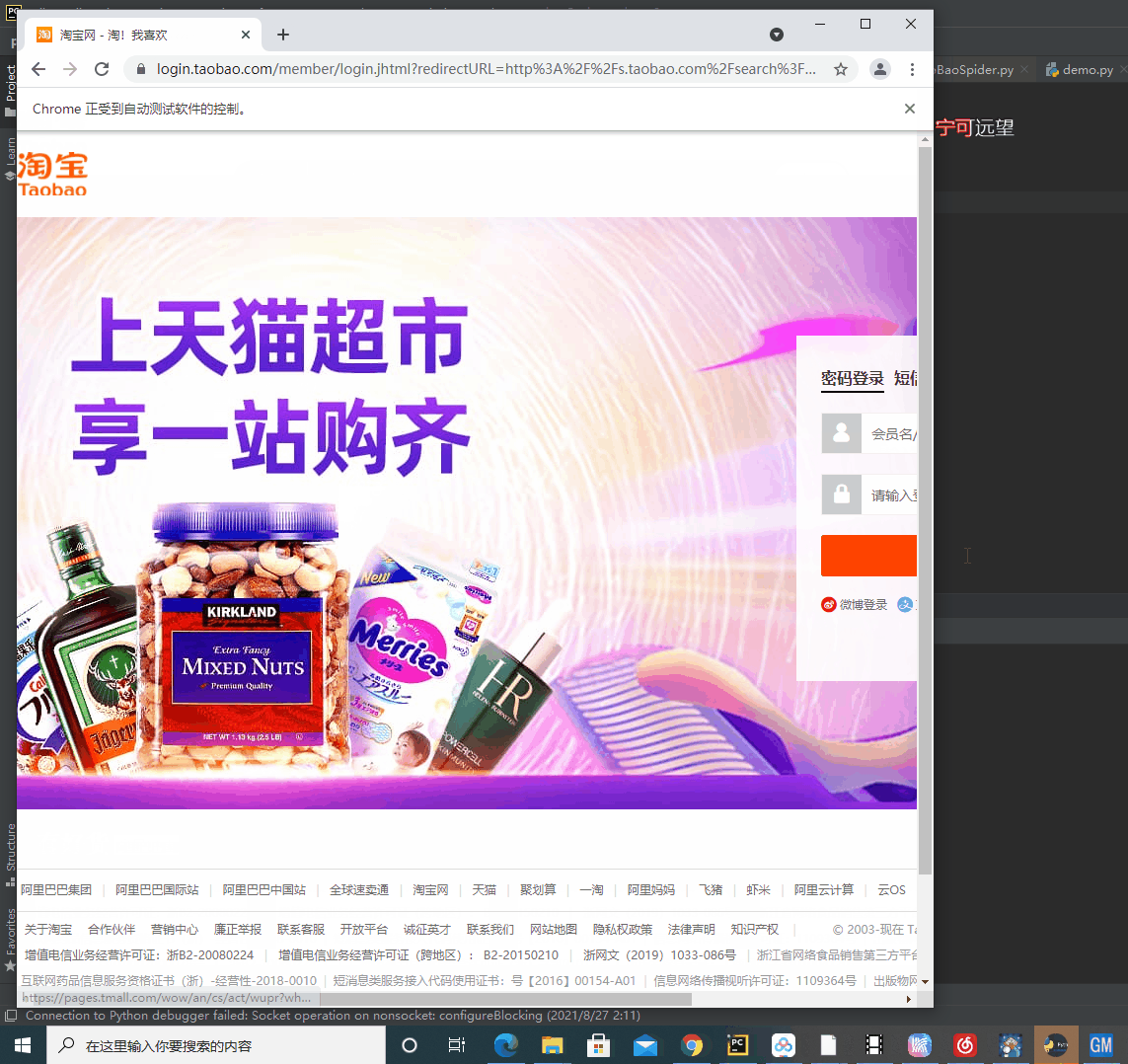
实例化一款需要被控制的浏览器,然后打开该网址:
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('http://www.taobao.com')

然后在输入框中输入咱们需要查找的商品,再点击搜索即可。
咱们今天重点利用到的为xpath网页元素定位法,通过xpath语法去定位元素的位置,因为程序不是人,人可以肉眼知道哪里是输入框,哪里是按钮。而程序需要咱们去告诉它,给它制定位置。
# 输入Python
driver.find_element_by_id('q').send_keys('python')
# 点击搜索
driver.find_element_by_class_name('btn-search').click()
定位的方法很多,我这里两句代码用到的是为id定位和类名定位。
最后在停留在登录界面:
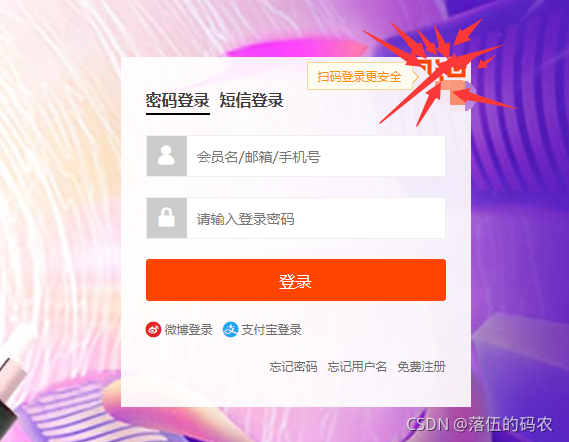
咱们采用扫码登录。
既然是这样子做的话,势必会需要一个时间供给你去登录,有人会采用延迟的方式,但是我不建议这样做。
因为延迟的时间不一定就能保证你刚好可以登录完,多了时间少了时间对咱们都不友好。少了时间还没登录上,程序就跑到别的地方去了报错了。多了时间你也懒得等。
所以在此之前咱们程序加上一行
input('扫码完成后请按Enter键')
这样子做的话,咱们可以人为的控制时间。最终登录完成。
分析(x1)
数据的提取
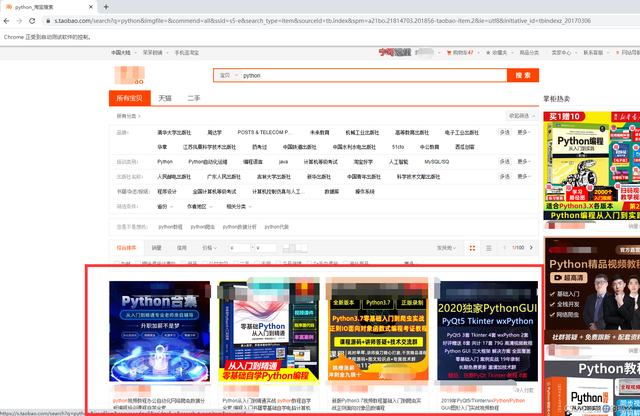
登录上去后可以看到很多的商品信息,咱们要采集的就是......都采集下来吧,什么图片、销量、地址、标题啥的
前面咱们提到了通过元素进行输入框自动输入、按钮点击。那么现在要做的就是通过元素定位去采集咱们想要的数据。
分析(x2)
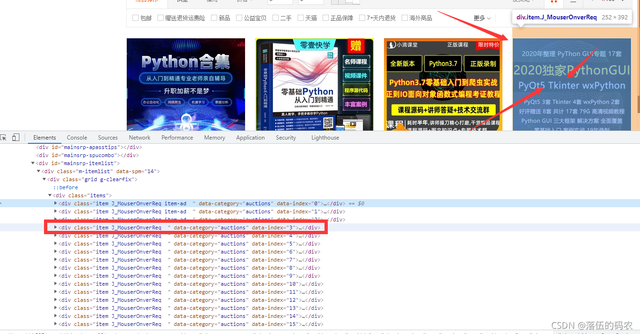
通过元素分析我们可以发现,这里的每一个DIV标签都保存了一个商品的信息,而前面三个class属性略有不同。应该是他们自费的一个广告商品吧,排名指定的那种。
简单分析了一下可以看到第三个商品的图片地址在img标签的src中:
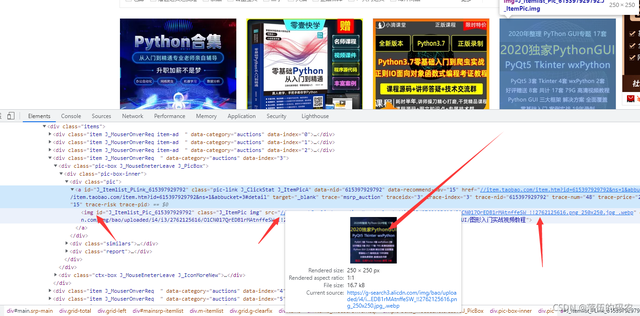
然后第47个商品的信息却不完善:
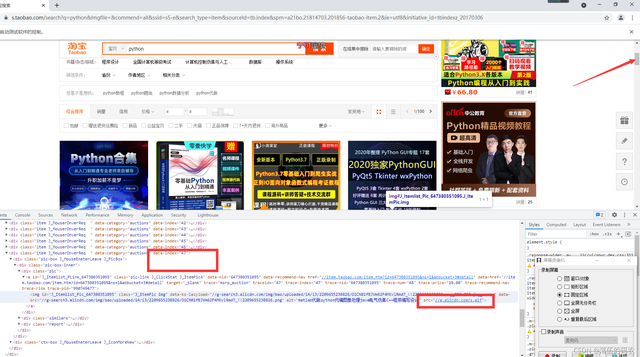
可以很清楚地发现这个商品的src的图片链接是不正常的,是没有图片的。
这个是为什么呢?还记得我前面文章(某音视频采集)讲到过的动态加载、瀑布流吗?当我们的滑动条往下滑的时候下面的数据才会加载出来,像瀑布一样地流出来。
所以如果我们想要采集到所有的商品图片,那么咱们就需要把这个下滑条往下面拉动 ,如何利用selenium控制这个下滑条往下面拉动呢?
for x in range(1, 11, 2):
time.sleep(0.5)
j = x/10
js = 'document.documentElement.scrollTop = document.documentElement.scrollHeight * %f' % j
driver.execute_script(js)
每停顿0.5S的时间,拉动下滑条的十分之三的位置。
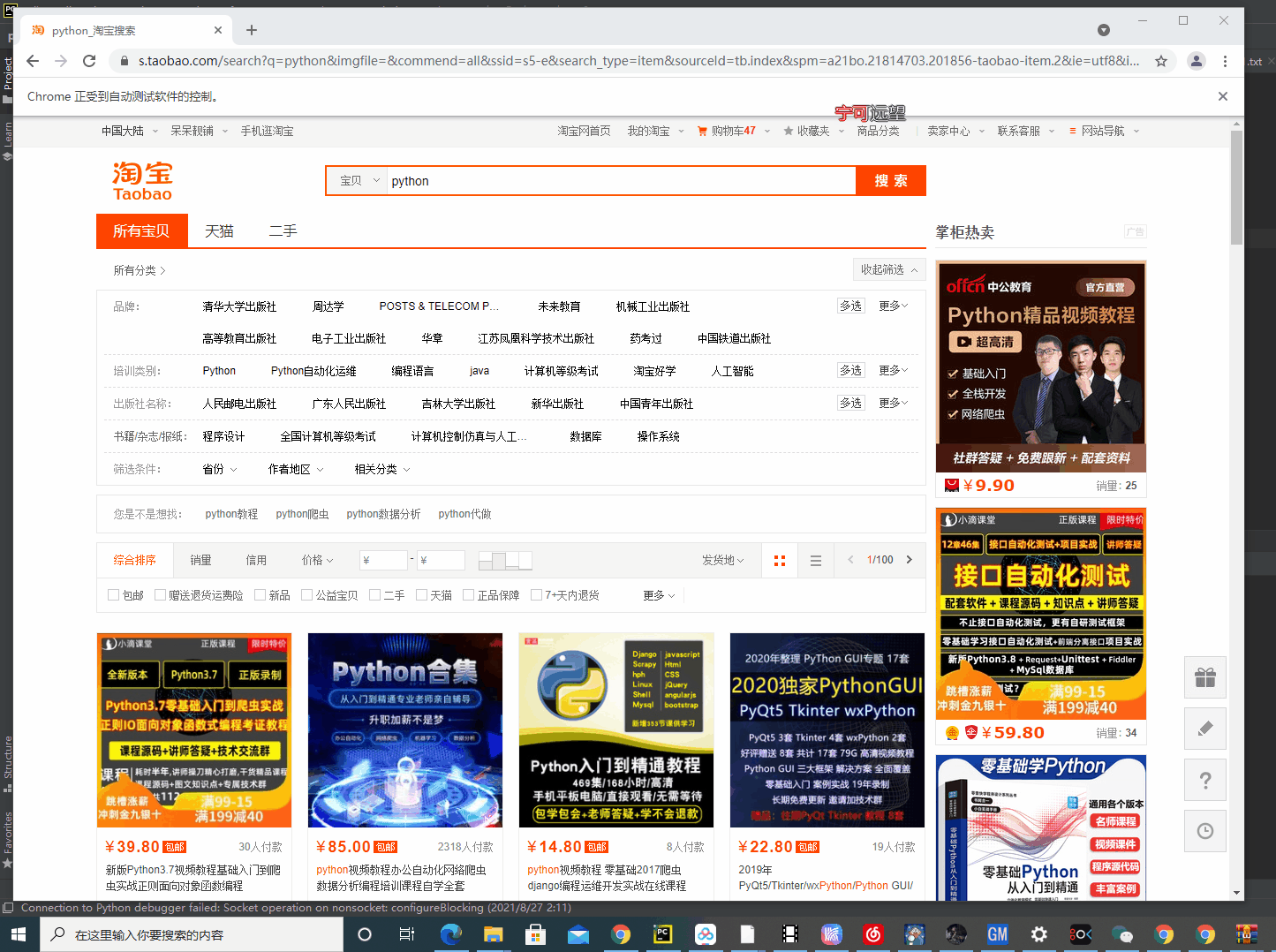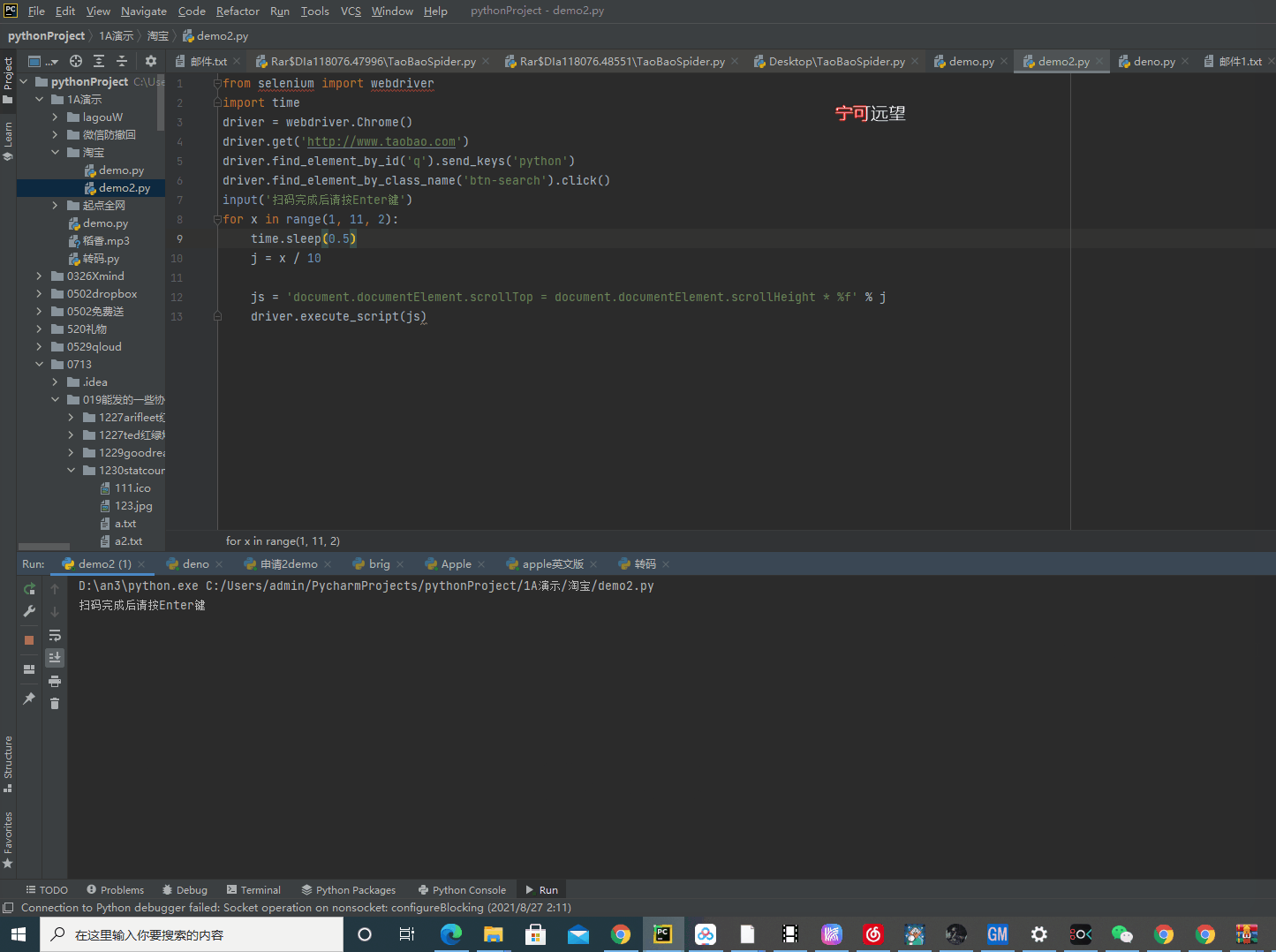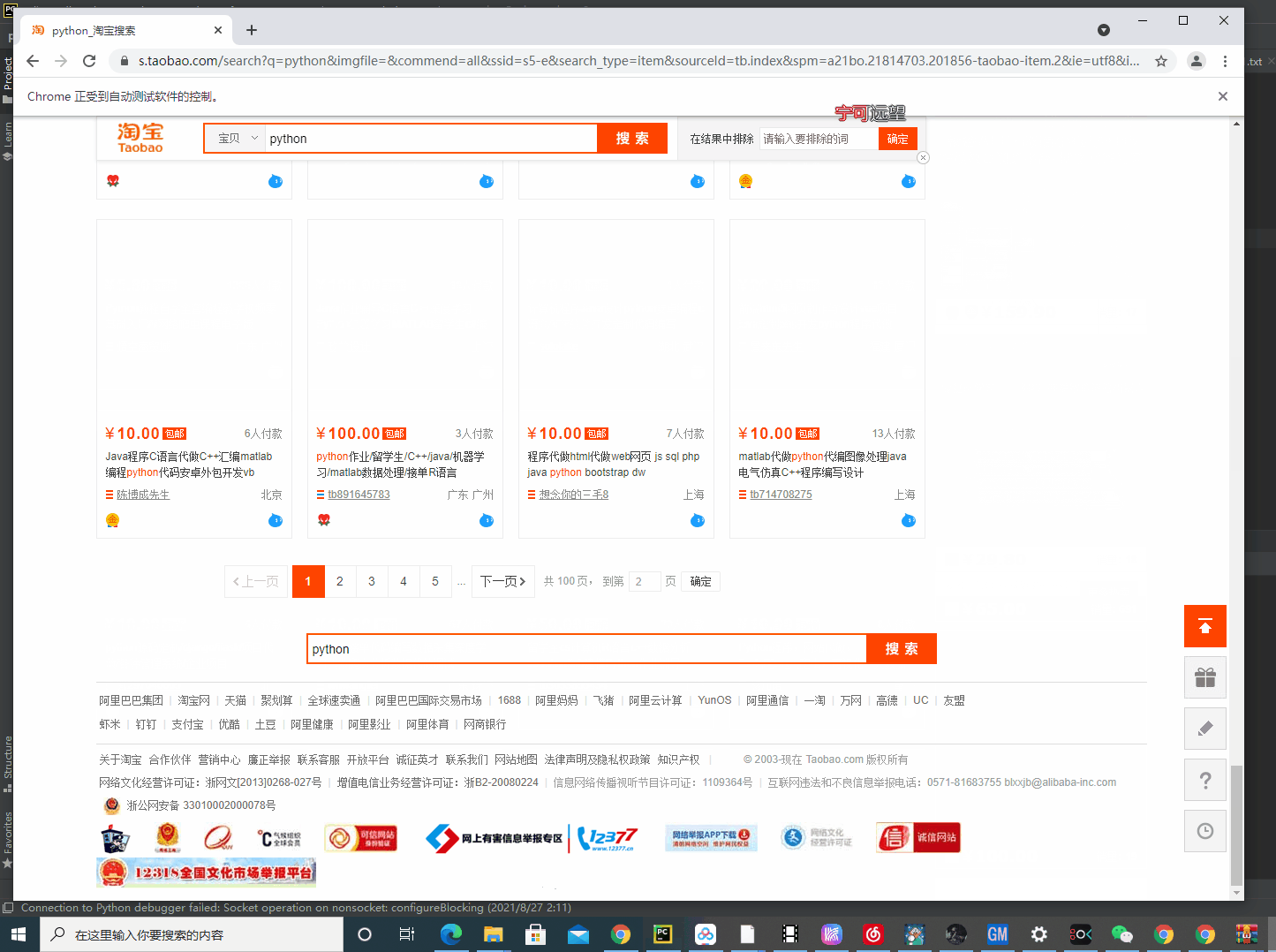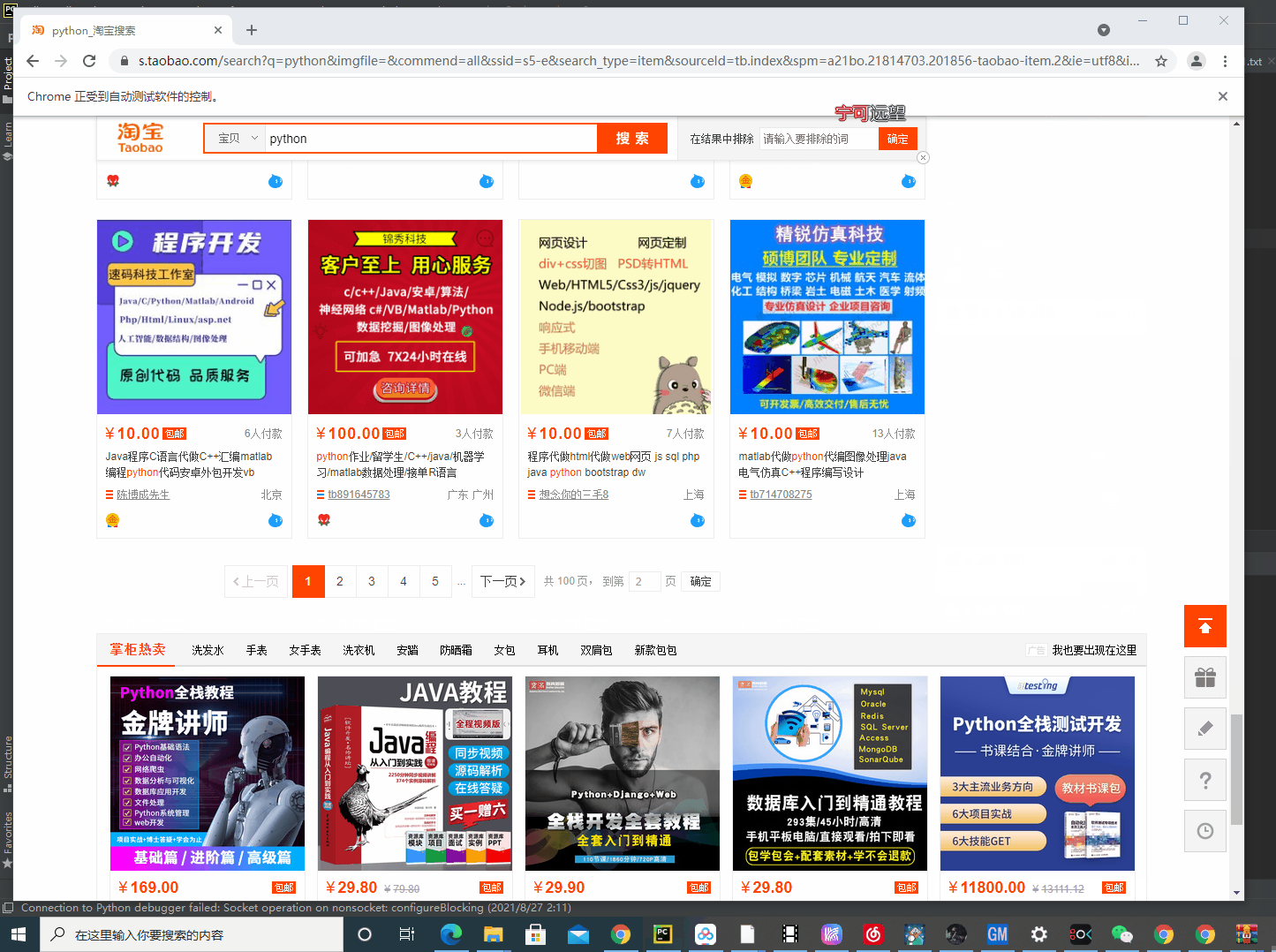
登录成功后按一下enter键,代码就会跳到下拉滑块的位置,执行下拉。
分析(x3)
数据都加载出来了后,咱们只管采集就好啦。采集的规则利用的是xpath定位法,这里我不做过多讲解。看我代码然后自己分析一下。
lis = driver.find_elements_by_xpath('//div[@class="items"]/div[@class="item J_MouserOnverReq "]')
for li in lis:
info = li.find_element_by_xpath('.//div[@class="row row-2 title"]').text
price = li.find_element_by_xpath('.//a[@class="J_ClickStat"]').get_attribute('trace-price') + '元'
deal = li.find_element_by_xpath('.//div[@class="deal-cnt"]').text
image = li.find_element_by_xpath('.//div[@class="pic"]/a/img').get_attribute('src')
name = li.find_element_by_xpath('.//div[@class="shop"]/a/span[2]').text
position = li.find_element_by_xpath('.//div[@class="row row-3 g-clearfix"]/div[@class="location"]').text
print(info + '|' + price + '|' + deal + '|' + name + '|' + image + '|' + position)
效果:
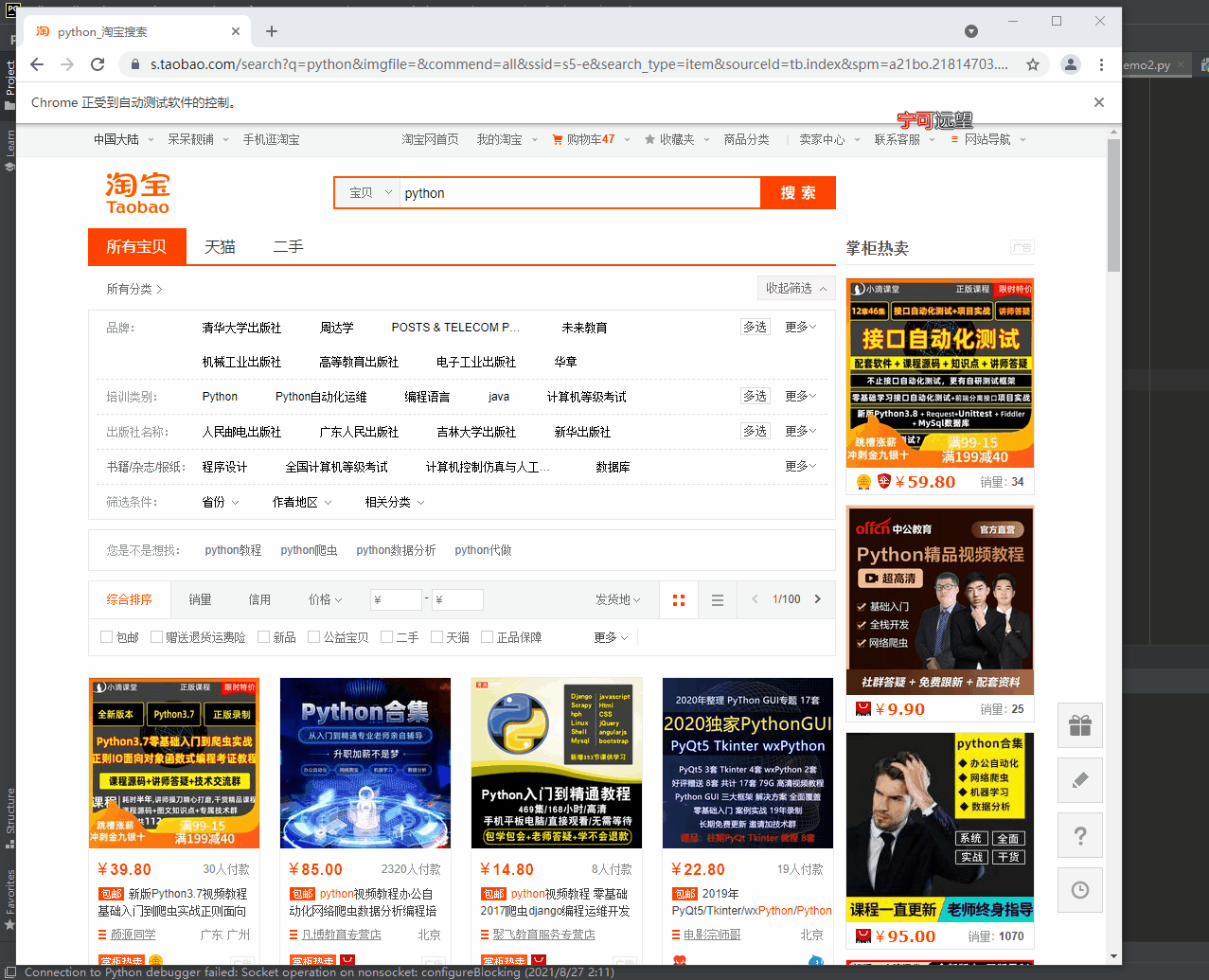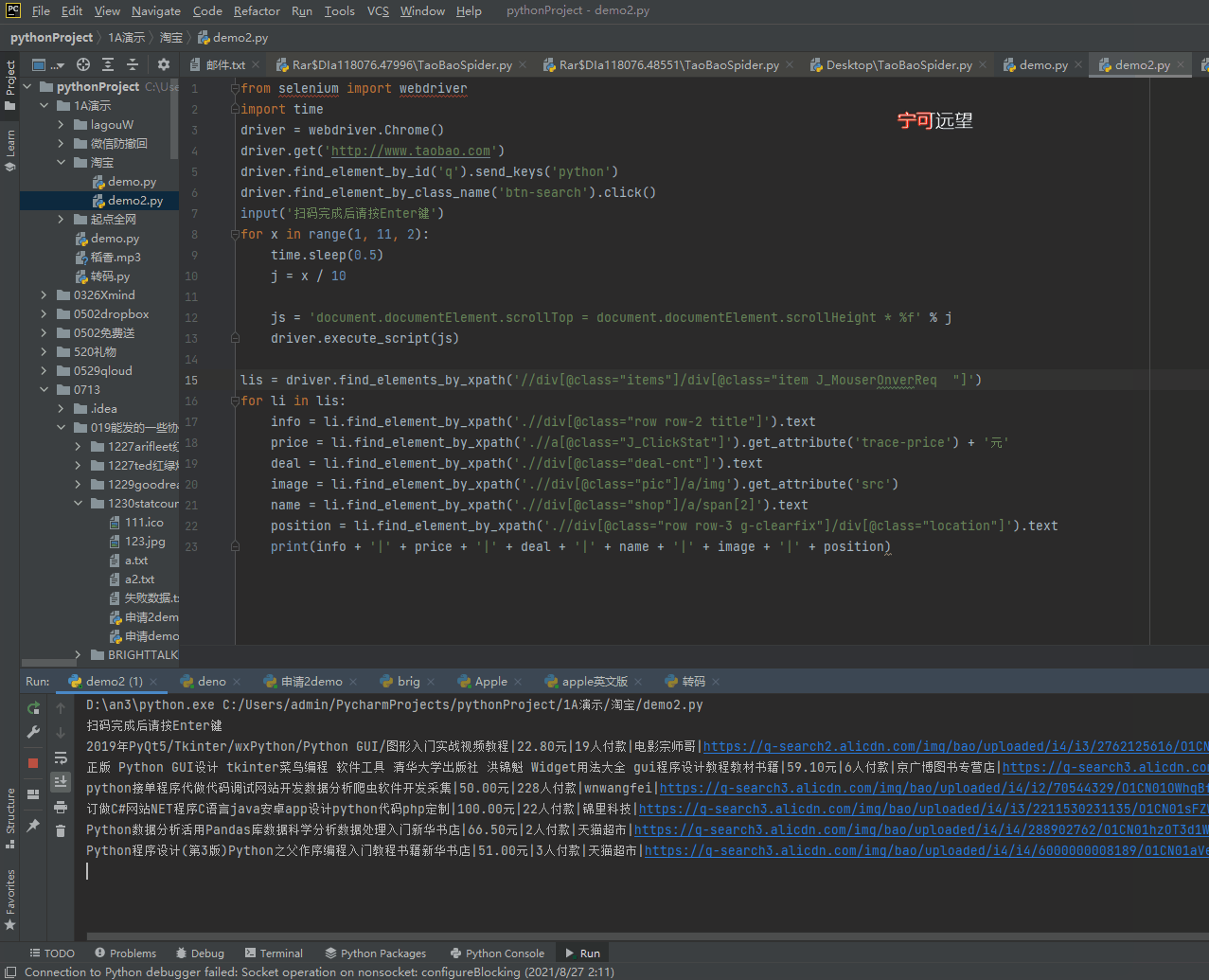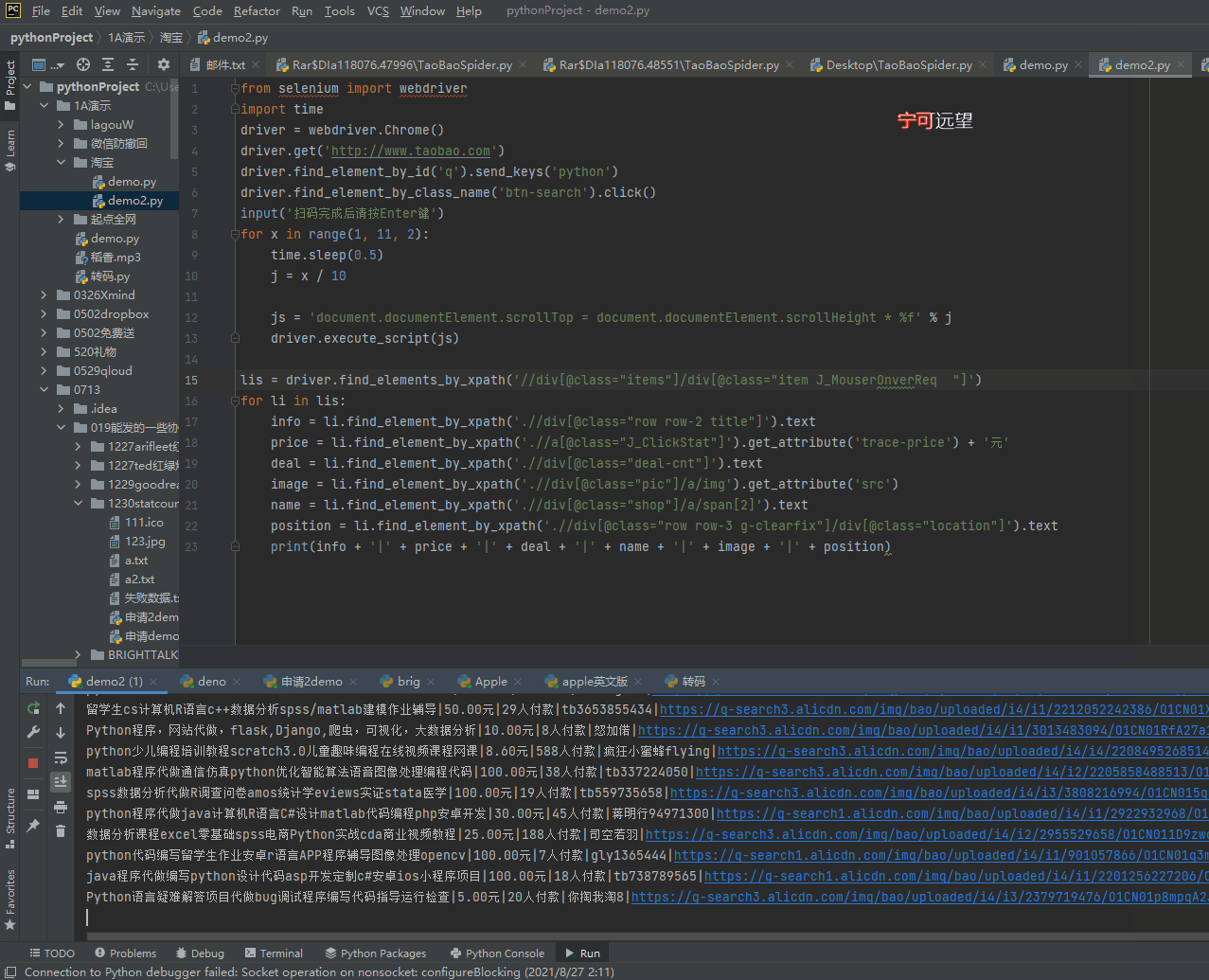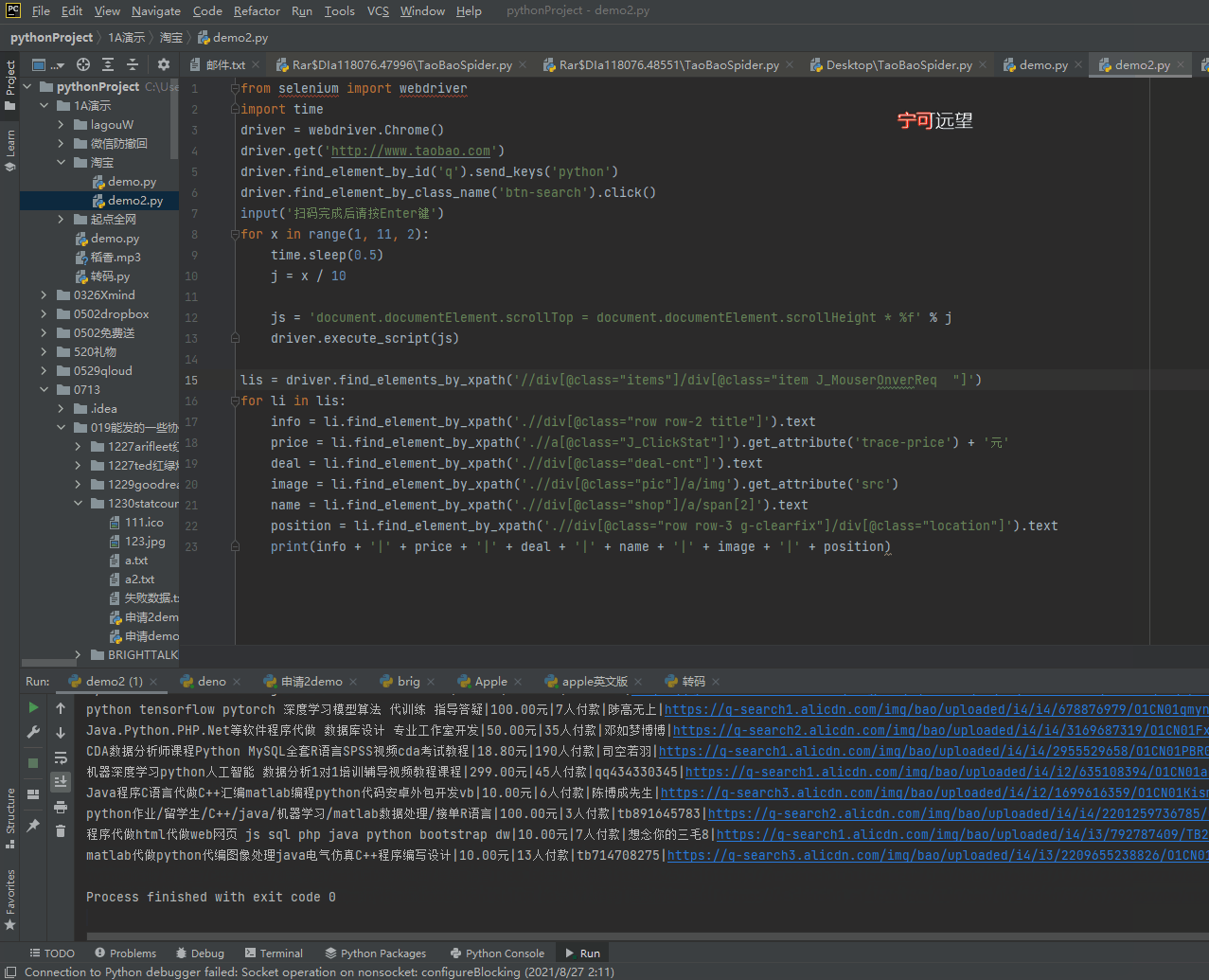
到此为止咱们第一页的商品数据已经采集下来了,那么如何采集所有页码的数据呢?
分析(x4)
在采集所有页码数据之前咱们先需要考虑的是什么?是这个商品总共有多少页吧?也许这个商品三十页,另一个商品100页,对不对?
而这个商品总页码在哪里看?
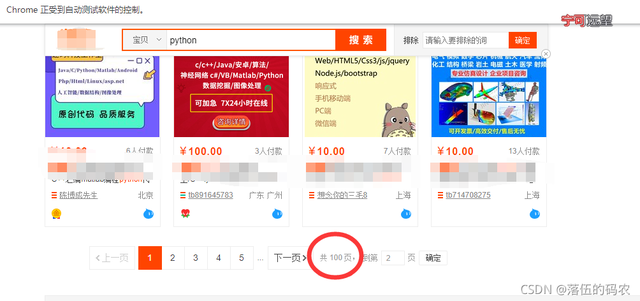
在哪里看咱们知道了,那么什么时候去采集到这个页码数呢?是不是当我们登录了之后就可以看到这个页码数了呀?那么咱们登录之后先把页码数采集下来!
token = driver.find_element_by_xpath('//*[@id="mainsrp-pager"]/div/div/div/div[1]')
token = token.text
token = int(re.compile('(\d+)').search(token).group(1))
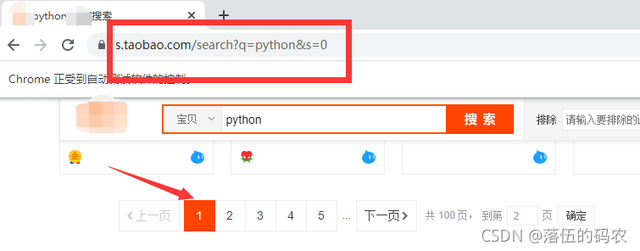
最后就剩下如何进入下一页了,我经常提到的,看网页的url是否会发生什么变化。

url中一堆混乱看不懂?看我以前文章经常给你提到的参数冗余,看不懂先删掉,看下第二页的url:
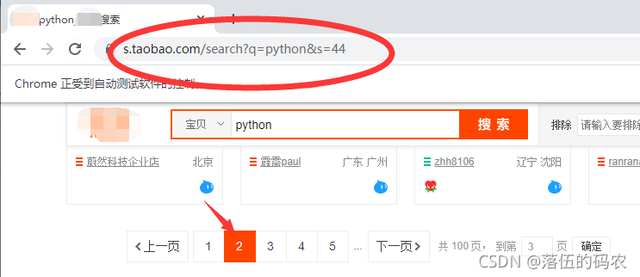
再看第一页:
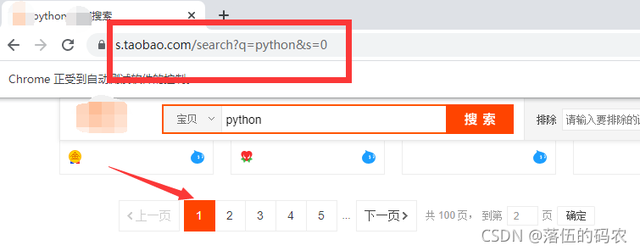
就s这个步长发生了变化吧,0-44就是说翻一页步长为44吧,构造下url:
for i in range(token-1):
url = https://s.taobao.com/search?q={}&s={}'.format('python', 44 * num)
总结
不要觉得莫名其妙就写总结了,事实上是咱们已经把整个过程分析完了。
思路:进入网站——登录——采集到页码数——下拉滑块条——采集数据——翻页——下拉滑块条——采集数据——翻页......
我有话说
—— 爱一路艰辛,一路仁至义尽。
文章的话是现写的,每篇文章我都会说的很细致,所以花费的时间比较久,一般都是两个小时以上。每一个赞与评论收藏都是我每天更新的动力。
原创不易,再次谢谢大家的支持。
① 2000多本Python电子书(主流和经典的书籍应该都有了)
② Python标准库资料(最全中文版)
③ 项目源码(四五十个有趣且经典的练手项目及源码)
④ Python基础入门、爬虫、web开发、大数据分析方面的视频(适合小白学习)
⑤ Python学习路线图(告别不入流的学习)
``` 当然在学习Python的道路上肯定会困难,没有好的学习资料,怎么去学习呢? 学习Python中有不明白推荐加入交流Q群号:928946953 群里有志同道合的小伙伴,互帮互助, 群里有不错的视频学习教程和PDF! 还有大牛解答! ```

标签:xpath,YYDS,Python,selenium,find,采集,div,源代码,class 来源: https://www.cnblogs.com/pythonQqun200160592/p/15209889.html