NTU Machine Learning 2020 hw3 CNN的做法
作者:互联网
利用VGGnet来完成Image Classification,在Kaggle勉强过了Strong Baseline。。。
首先感谢一下NTU的李宏毅老师分享这么好的课程,还把作业也给分享了出来
作业3的slide
首先来看看给出的能过Simple Baseline的network架构:
class Classifier(nn.Module):
def __init__(self):
super(Classifier, self).__init__()
# torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding)
# torch.nn.MaxPool2d(kernel_size, stride, padding)
# input 維度 [3, 128, 128]
self.cnn = nn.Sequential(
nn.Conv2d(3, 64, 3, 1, 1), # [64, 128, 128]
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(2, 2, 0), # [64, 64, 64]
nn.Conv2d(64, 128, 3, 1, 1), # [128, 64, 64]
nn.BatchNorm2d(128),
nn.ReLU(),
nn.MaxPool2d(2, 2, 0), # [128, 32, 32]
nn.Conv2d(128, 256, 3, 1, 1), # [256, 32, 32]
nn.BatchNorm2d(256),
nn.ReLU(),
nn.MaxPool2d(2, 2, 0), # [256, 16, 16]
nn.Conv2d(256, 512, 3, 1, 1), # [512, 16, 16]
nn.BatchNorm2d(512),
nn.ReLU(),
nn.MaxPool2d(2, 2, 0), # [512, 8, 8]
nn.Conv2d(512, 512, 3, 1, 1), # [512, 8, 8]
nn.BatchNorm2d(512),
nn.ReLU(),
nn.MaxPool2d(2, 2, 0), # [512, 4, 4]
)
self.fc = nn.Sequential(
nn.Linear(512*4*4, 1024),
nn.ReLU(),
nn.Linear(1024, 512),
nn.ReLU(),
nn.Linear(512, 11)
)
def forward(self, x):
out = self.cnn(x)
out = out.view(out.size()[0], -1)
return self.fc(out)
在做作业的时候去看了好几篇paper,可以看出这是一个很典型的AlexNet[1],然后我们顺着CNN发展的历史到处看看。。。后面几个主要的模型就是VGGNet[2],ResNet[3],然后拿着这些model一个个试就好了。。。
但是中间也是有许多坑的。。。就拿我最后实现的VGGnet来说,原始的VGGnet是拿来做1000类的image classification的,这需要我们去修改VGGnet最后linear单元的structure。
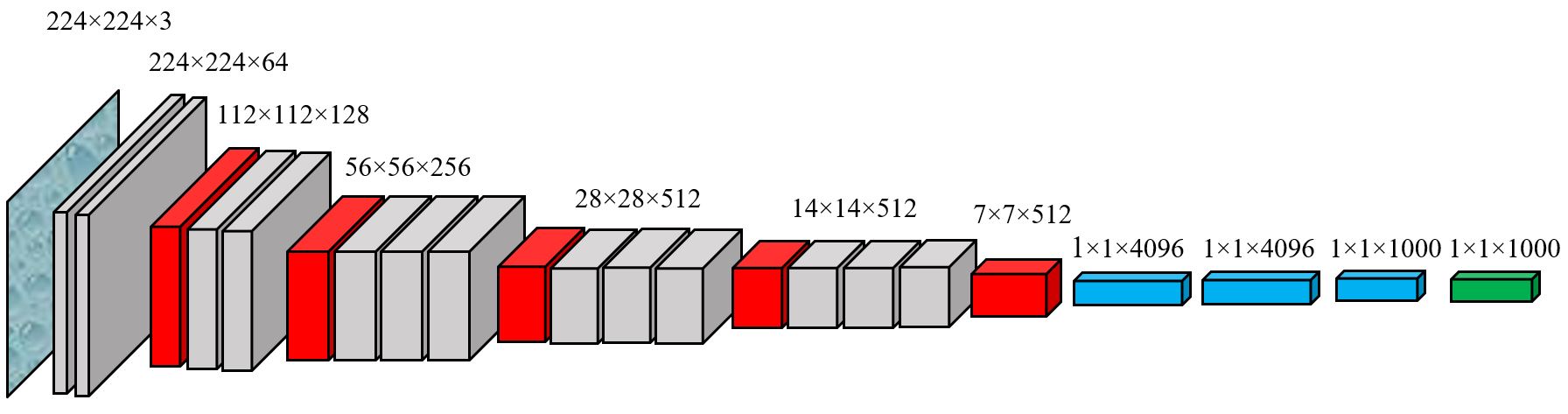
然后我们就得一层层去算我们image产生的tensor的大小,比如经过我们设置的stride = 1,padding = 1的\(3\times 3\)的kernel所在的卷积层是会改变channel的大小,但是其他维度是不会改变的,而经过\(2\times 2\)的max pooling层channel不变,但是其他维度上的大小全部会减半,我们的image是\(3\times 128\times128\)的,经过了四次max pooling、最大channel为512的卷积层后大小为\(512\times 4 \times 4\),所以我们最后的linear部分需要把\(512 \times 4 \times 4\)的vector映射成大小为11的vector(图片有11类)。然后pytorch官方是有写好的VGGnet可以直接用的。。。但是我不知道怎么改最后linear的部分,所以找到了源码改了一下。。。
还有就是我的整个model都是跑在Google Colab上的,毕竟CNN这种model没有cuda加速那估计是得train好几个小时。。。但是在Colab上用GPU加速需要注意一下有时候会提示Cuda run out of memory的问题,一下是总结出的几种可能存在的问题:
-
Case 1: 根据Pytorch官方的文档,爆显存可能是存了很多用不到的但是会有autograd数据的变量,所以可以用python的del语句释放这些变量
-
Case 2: 可能就是你的model需要的显存过多了,超过了Colab提供的上限,可以调小batch size试试
如果还是不行的话,可以用一下指令强行释放显存(注意在Colab中运行shell命令前面要加!:
fuser -v /dev/nvidia0 ## 在输出中看pid kill -9 [pid]最后我train出来的model的准确率在81%左右,刚好过了Strong baseline。。。至于kaggle上那些更高accuracy的大佬们估计用了更先进的model比如Resnet之类的。。。但是这VGGnet-16 train一次要40min。。。我就不想往下试了。。。就这样吧。。。
我的代码:https://colab.research.google.com/drive/15H6hvbuxhSIdw-ehrQ-EN1oUgdKQRXb5?usp=sharing
Krizhevsky, A., Sutskever, I., & Hinton, G. E. (n.d.). ImageNet Classification with Deep Convolutional Neural Networks. ↩︎
Simonyan, K., & Zisserman, A. (2015). VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE-SCALE IMAGE RECOGNITION. ↩︎
He, K., Zhang, X., Ren, S., & Sun, J. (2016). Deep residual learning for image recognition. Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 2016-Decem, 770–778. ↩︎
标签:nn,NTU,times,Machine,2020,128,64,512,out 来源: https://www.cnblogs.com/init0xyz/p/14477022.html