Flink系列
作者:互联网
Flink系列(持续更新ing......)
目录
Flink的入门简介
CentOS7.5搭建Flink1.6.1分布式集群
Flink开发IDEA环境搭建与测试
Flink的入门简介
一. Flink的引入
这几年大数据的飞速发展,出现了很多热门的开源社区,其中著名的有 Hadoop、Storm,以及后来的 Spark,他们都有着各自专注的应用场景。Spark 掀开了内存计算的先河,也以内存为赌注,赢得了内存计算的飞速发展。Spark 的火热或多或少的掩盖了其他分布式计算的系统身影。就像 Flink,也就在这个时候默默的发展着。
在国外一些社区,有很多人将大数据的计算引擎分成了 4 代,当然,也有很多人不会认同。我们先姑且这么认为和讨论。
首先第一代的计算引擎,无疑就是 Hadoop 承载的 MapReduce。这里大家应该都不会对 MapReduce 陌生,它将计算分为两个阶段,分别为 Map 和 Reduce。对于上层应用来说,就不得不想方设法去拆分算法,甚至于不得不在上层应用实现多个 Job 的串联,以完成一个完整的算法,例如迭代计算。
由于这样的弊端,催生了支持 DAG 框架的产生。因此,支持 DAG 的框架被划分为第二代计算引擎。如 Tez 以及更上层的 Oozie。这里我们不去细究各种 DAG 实现之间的区别,不过对于当时的 Tez 和 Oozie 来说,大多还是批处理的任务。
接下来就是以 Spark 为代表的第三代的计算引擎。第三代计算引擎的特点主要是 Job 内部的 DAG 支持(不跨越 Job),以及强调的实时计算。在这里,很多人也会认为第三代计算引擎也能够很好的运行批处理的 Job。
随着第三代计算引擎的出现,促进了上层应用快速发展,例如各种迭代计算的性能以及对流计算和 SQL 等的支持。Flink 的诞生就被归在了第四代。这应该主要表现在 Flink 对流计算的支持,以及更一步的实时性上面。当然 Flink 也可以支持 Batch 的任务,以及 DAG 的运算。
二. Flink简介
Apache Flink是一个框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算。Flink设计为在所有常见的集群环境中运行,以内存速度和任何规模执行计算。
1.无界流和有界流
任何类型的数据都是作为事件流产生的。信用卡交易,传感器测量,机器日志或网站或移动应用程序上的用户交互,所有这些数据都作为流生成。
数据可以作为无界或有界流处理。
-
无界流有一个开始但没有定义的结束。它们不会在生成时终止并提供数据。必须持续处理无界流,即必须在摄取事件后立即处理事件。无法等待所有输入数据到达,因为输入是无界的,并且在任何时间点都不会完成。处理无界数据通常要求以特定顺序(例如事件发生的顺序)摄取事件,以便能够推断结果完整性。
-
有界流具有定义的开始和结束。可以在执行任何计算之前通过摄取所有数据来处理有界流。处理有界流不需要有序摄取,因为可以始终对有界数据集进行排序。有界流的处理也称为批处理。
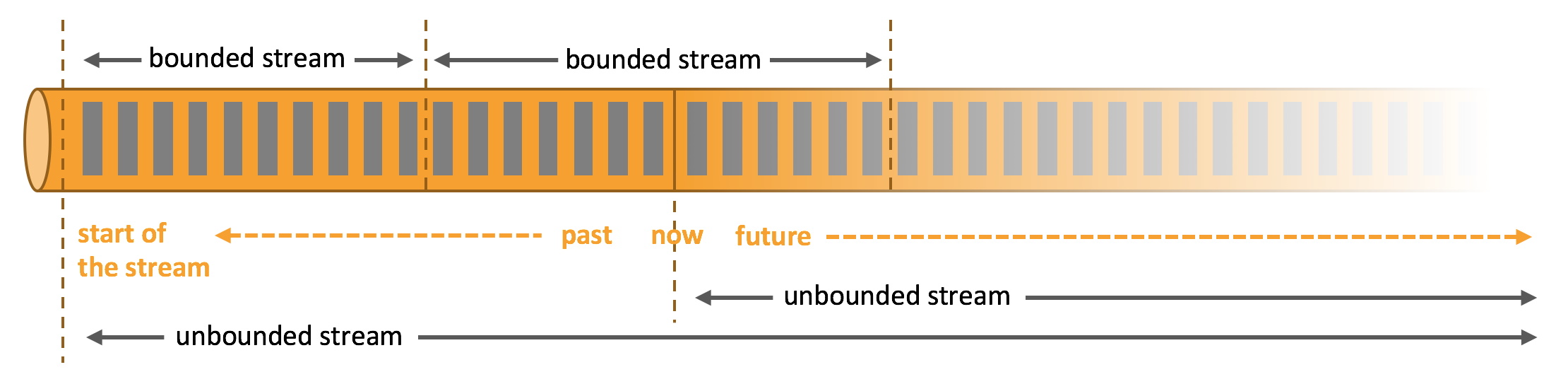
Apache Flink擅长处理无界和有界数据集。精确控制时间和状态使Flink的运行时能够在无界流上运行任何类型的应用程序。有界流由算法和数据结构内部处理,这些算法和数据结构专门针对固定大小的数据集而设计,从而产生出色的性能。
2.随处部署应用程序
Apache Flink是一个分布式系统,需要计算资源才能执行应用程序。Flink与所有常见的集群资源管理器(如Hadoop YARN,Apache Mesos和Kubernetes)集成,但也可以设置为作为独立集群运行。
Flink旨在很好地适用于之前列出的每个资源管理器。这是通过特定于资源管理器的部署模式实现的,这些模式允许Flink以其惯用的方式与每个资源管理器进行交互。
部署Flink应用程序时,Flink会根据应用程序配置的并行性自动识别所需资源,并从资源管理器请求它们。如果发生故障,Flink会通过请求新资源来替换发生故障的容器。提交或控制应用程序的所有通信都通过REST调用进行。这简化了Flink在许多环境中的集成。
3.以任何比例运行应用程序
Flink旨在以任何规模运行有状态流应用程序。应用程序可以并行化为数千个在集群中分布和同时执行的任务。因此,应用程序可以利用几乎无限量的CPU,主内存,磁盘和网络IO。而且,Flink可以轻松维护非常大的应用程序状态。其异步和增量检查点算法确保对处理延迟的影响最小,同时保证一次性状态一致性。
用户报告了在其生产环境中运行的Flink应用程序的可扩展性数字令人印象深刻,例如
- 应用程序每天处理数万亿个事件,
- 应用程序维护多个TB的状态,以及
- 应用程序在数千个内核的运行。
4.利用内存中的性能
有状态Flink应用程序针对本地状态访问进行了优化。任务状态始终保留在内存中,或者,如果状态大小超过可用内存,则保存在访问高效的磁盘上数据结构中。因此,任务通过访问本地(通常是内存中)状态来执行所有计算,从而产生非常低的处理延迟。Flink通过定期和异步检查本地状态到持久存储来保证在出现故障时的一次状态一致性。
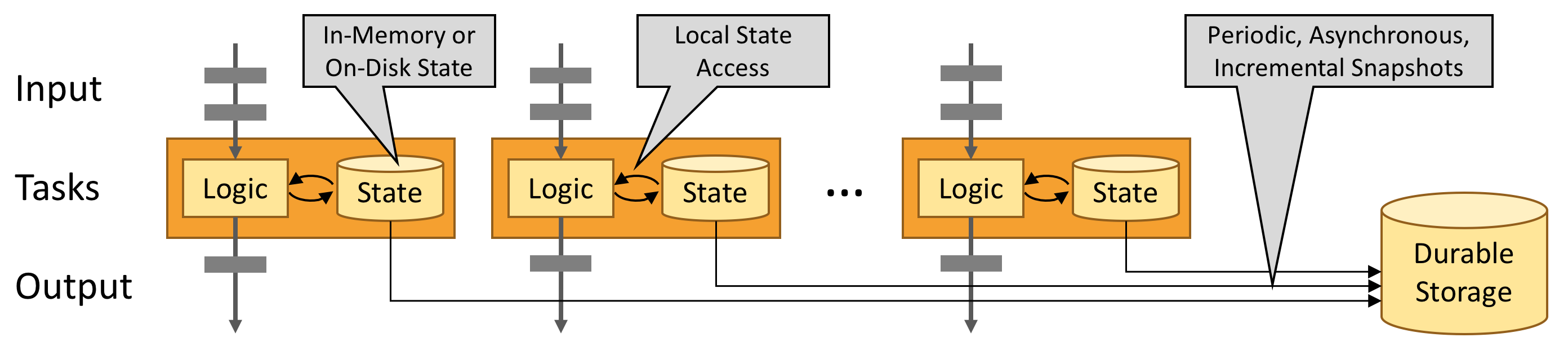
5.Flink的架构
Flink 可以支持本地的快速迭代,以及一些环形的迭代任务。并且 Flink 可以定制化内存管理。在这点,如果要对比 Flink 和 Spark 的话,Flink 并没有将内存完全交给应用层。这也是为什么 Spark 相对于 Flink,更容易出现 OOM 的原因(out of memory)。就框架本身与应用场景来说,Flink 更相似与 Storm。如果之前了解过 Storm 或者 Flume 的读者,可能会更容易理解 Flink 的架构和很多概念。下面让我们先来看下 Flink 的架构图。

我们可以了解到 Flink 几个最基础的概念,Client、JobManager 和 TaskManager。Client 用来提交任务给 JobManager,JobManager 分发任务给 TaskManager 去执行,然后 TaskManager 会心跳的汇报任务状态。看到这里,有的人应该已经有种回到 Hadoop 一代的错觉。确实,从架构图去看,JobManager 很像当年的 JobTracker,TaskManager 也很像当年的 TaskTracker。然而有一个最重要的区别就是 TaskManager 之间是是流(Stream)。其次,Hadoop 一代中,只有 Map 和 Reduce 之间的 Shuffle,而对 Flink 而言,可能是很多级,并且在 TaskManager 内部和 TaskManager 之间都会有数据传递,而不像 Hadoop,是固定的 Map 到 Reduce。
三. Flink技术特点
1. 流处理特性
支持高吞吐、低延迟、高性能的流处理
支持带有事件时间的窗口(Window)操作
支持有状态计算的Exactly-once语义
支持高度灵活的窗口(Window)操作,支持基于time、count、session,以及data-driven的窗口操作
支持具有Backpressure功能的持续流模型
支持基于轻量级分布式快照(Snapshot)实现的容错
一个运行时同时支持Batch on Streaming处理和Streaming处理
Flink在JVM内部实现了自己的内存管理
支持迭代计算
支持程序自动优化:避免特定情况下Shuffle、排序等昂贵操作,中间结果有必要进行缓存
2. API支持
对Streaming数据类应用,提供DataStream API
对批处理类应用,提供DataSet API(支持Java/Scala)
3. Libraries支持
支持机器学习(FlinkML)
支持图分析(Gelly)
支持关系数据处理(Table)
支持复杂事件处理(CEP)
4. 整合支持
支持Flink on YARN
支持HDFS
支持来自Kafka的输入数据
支持Apache HBase
支持Hadoop程序
支持Tachyon
支持ElasticSearch
支持RabbitMQ
支持Apache Storm
支持S3
支持XtreemFS
5. Flink生态圈
Flink 首先支持了 Scala 和 Java 的 API,Python 也正在测试中。Flink 通过 Gelly 支持了图操作,还有机器学习的 FlinkML。Table 是一种接口化的 SQL 支持,也就是 API 支持,而不是文本化的 SQL 解析和执行。对于完整的 Stack 我们可以参考下图。

Flink 为了更广泛的支持大数据的生态圈,其下也实现了很多 Connector 的子项目。最熟悉的,当然就是与 Hadoop HDFS 集成。其次,Flink 也宣布支持了 Tachyon、S3 以及 MapRFS。不过对于 Tachyon 以及 S3 的支持,都是通过 Hadoop HDFS 这层包装实现的,也就是说要使用 Tachyon 和 S3,就必须有 Hadoop,而且要更改 Hadoop 的配置(core-site.xml)。如果浏览 Flink 的代码目录,我们就会看到更多 Connector 项目,例如 Flume 和 Kafka。
四. Flink的编程模型
Flink提供不同级别的抽象来开发流/批处理应用程序。

CentOS7.5搭建Flink1.6.1分布式集群
一. Flink的下载
安装包下载地址:http://flink.apache.org/downloads.html ,选择对应Hadoop的Flink版本下载

[admin@node21 software]$ wget http://mirrors.tuna.tsinghua.edu.cn/apache/flink/flink-1.6.1/flink-1.6.1-bin-hadoop27-scala_2.11.tgz [admin@node21 software]$ ll -rw-rw-r-- 1 admin admin 301867081 Sep 15 15:47 flink-1.6.1-bin-hadoop27-scala_2.11.tgz
Flink 有三种部署模式,分别是 Local、Standalone Cluster 和 Yarn Cluster。
二. Local模式
对于 Local 模式来说,JobManager 和 TaskManager 会公用一个 JVM 来完成 Workload。如果要验证一个简单的应用,Local 模式是最方便的。实际应用中大多使用 Standalone 或者 Yarn Cluster,而local模式只是将安装包解压启动(./bin/start-local.sh)即可,在这里不在演示。
三. Standalone 模式
快速入门教程地址:https://ci.apache.org/projects/flink/flink-docs-release-1.6/quickstart/setup_quickstart.html
1. 软件要求
- Java 1.8.x或更高版本,
- ssh(必须运行sshd才能使用管理远程组件的Flink脚本)
集群部署规划
| 节点名称 | master | worker | zookeeper |
| node21 | master | zookeeper | |
| node22 | master | worker | zookeeper |
| node23 | worker | zookeeper |
2. 解压
[admin@node21 software]$ tar zxvf flink-1.6.1-bin-hadoop27-scala_2.11.tgz -C /opt/module/ [admin@node21 software]$ cd /opt/module/ [admin@node21 module]$ ll drwxr-xr-x 8 admin admin 125 Sep 15 04:47 flink-1.6.1
3. 修改配置文件
[admin@node21 conf]$ ls flink-conf.yaml log4j-console.properties log4j-yarn-session.properties logback.xml masters sql-client-defaults.yaml log4j-cli.properties log4j.properties logback-console.xml logback-yarn.xml slaves zoo.cfg
修改flink/conf/masters,slaves,flink-conf.yaml

[admin@node21 conf]$ sudo vi masters node21:8081 [admin@node21 conf]$ sudo vi slaves node22 node23 [admin@node21 conf]$ sudo vi flink-conf.yaml taskmanager.numberOfTaskSlots:2 jobmanager.rpc.address: node21
可选配置:
- 每个JobManager(
jobmanager.heap.mb)的可用内存量, - 每个TaskManager(
taskmanager.heap.mb)的可用内存量, - 每台机器的可用CPU数量(
taskmanager.numberOfTaskSlots), - 集群中的CPU总数(
parallelism.default)和 - 临时目录(
taskmanager.tmp.dirs)
4. 拷贝安装包到各节点
[admin@node21 module]$ scp -r flink-1.6.1/ admin@node22:`pwd` [admin@node21 module]$ scp -r flink-1.6.1/ admin@node23:`pwd`
5. 配置环境变量
配置所有节点Flink的环境变量
[admin@node21 flink-1.6.1]$ sudo vi /etc/profile export FLINK_HOME=/opt/module/flink-1.6.1 export PATH=$PATH:$FLINK_HOME/bin [admin@node21 flink-1.6.1]$ source /etc/profile
6. 启动flink
[admin@node21 flink-1.6.1]$ ./bin/start-cluster.sh Starting cluster. Starting standalonesession daemon on host node21. Starting taskexecutor daemon on host node22. Starting taskexecutor daemon on host node23.
jps查看进程



7. WebUI查看

8. Flink 的 HA
首先,我们需要知道 Flink 有两种部署的模式,分别是 Standalone 以及 Yarn Cluster 模式。对于 Standalone 来说,Flink 必须依赖于 Zookeeper 来实现 JobManager 的 HA(Zookeeper 已经成为了大部分开源框架 HA 必不可少的模块)。在 Zookeeper 的帮助下,一个 Standalone 的 Flink 集群会同时有多个活着的 JobManager,其中只有一个处于工作状态,其他处于 Standby 状态。当工作中的 JobManager 失去连接后(如宕机或 Crash),Zookeeper 会从 Standby 中选举新的 JobManager 来接管 Flink 集群。
对于 Yarn Cluaster 模式来说,Flink 就要依靠 Yarn 本身来对 JobManager 做 HA 了。其实这里完全是 Yarn 的机制。对于 Yarn Cluster 模式来说,JobManager 和 TaskManager 都是被 Yarn 启动在 Yarn 的 Container 中。此时的 JobManager,其实应该称之为 Flink Application Master。也就说它的故障恢复,就完全依靠着 Yarn 中的 ResourceManager(和 MapReduce 的 AppMaster 一样)。由于完全依赖了 Yarn,因此不同版本的 Yarn 可能会有细微的差异。这里不再做深究。
1) 修改配置文件
修改flink-conf.yaml,HA模式下,jobmanager不需要指定,在master file中配置,由zookeeper选出leader与standby。
#jobmanager.rpc.address: node21 high-availability:zookeeper #指定高可用模式(必须) high-availability.zookeeper.quorum:node21:2181,node22:2181,node23:2181 #ZooKeeper仲裁是ZooKeeper服务器的复制组,它提供分布式协调服务(必须) high-availability.storageDir:hdfs:///flink/ha/ #JobManager元数据保存在文件系统storageDir中,只有指向此状态的指针存储在ZooKeeper中(必须) high-availability.zookeeper.path.root:/flink #根ZooKeeper节点,在该节点下放置所有集群节点(推荐) high-availability.cluster-id:/flinkCluster #自定义集群(推荐) state.backend: filesystem state.checkpoints.dir: hdfs:///flink/checkpoints state.savepoints.dir: hdfs:///flink/checkpoints
修改conf/zoo.cfg
server.1=node21:2888:3888 server.2=node22:2888:3888 server.3=node23:2888:3888
修改conf/masters
node21:8081 node22:8081
修改slaves
node22 node23
同步配置文件conf到各节点
2) 启动HA
先启动zookeeper集群各节点(测试环境中也可以用Flink自带的start-zookeeper-quorum.sh),启动dfs ,再启动flink
[admin@node21 flink-1.6.1]$ start-cluster.sh

WebUI查看,这是会自动产生一个主Master,如下

3) 验证HA

手动杀死node22上的master,此时,node21上的备用master转为主mater。

4)手动将JobManager / TaskManager实例添加到群集
您可以使用bin/jobmanager.sh和bin/taskmanager.sh脚本将JobManager和TaskManager实例添加到正在运行的集群中。
添加JobManager
bin/jobmanager.sh ((start|start-foreground) [host] [webui-port])|stop|stop-all
添加TaskManager
bin/taskmanager.sh start|start-foreground|stop|stop-all
[admin@node22 flink-1.6.1]$ jobmanager.sh start node22
新添加的为从master。
9. 运行测试任务
[admin@node21 flink-1.6.1]$ flink run -m node21:8081 ./examples/batch/WordCount.jar --input /opt/wcinput/wc.txt --output /opt/wcoutput/ [admin@node21 flink-1.6.1]$ flink run -m node21:8081 ./examples/batch/WordCount.jar --input hdfs:///user/admin/input/wc.txt --output hdfs:///user/admin/output2

四. Yarn Cluster模式
1. 引入
在一个企业中,为了最大化的利用集群资源,一般都会在一个集群中同时运行多种类型的 Workload。因此 Flink 也支持在 Yarn 上面运行。首先,让我们通过下图了解下 Yarn 和 Flink 的关系。

在图中可以看出,Flink 与 Yarn 的关系与 MapReduce 和 Yarn 的关系是一样的。Flink 通过 Yarn 的接口实现了自己的 App Master。当在 Yarn 中部署了 Flink,Yarn 就会用自己的 Container 来启动 Flink 的 JobManager(也就是 App Master)和 TaskManager。
启动新的Flink YARN会话时,客户端首先检查所请求的资源(容器和内存)是否可用。之后,它将包含Flink和配置的jar上传到HDFS(步骤1)。
客户端的下一步是请求(步骤2)YARN容器以启动ApplicationMaster(步骤3)。由于客户端将配置和jar文件注册为容器的资源,因此在该特定机器上运行的YARN的NodeManager将负责准备容器(例如,下载文件)。完成后,将启动ApplicationMaster(AM)。
该JobManager和AM在同一容器中运行。一旦它们成功启动,AM就知道JobManager(它自己的主机)的地址。它正在为TaskManagers生成一个新的Flink配置文件(以便它们可以连接到JobManager)。该文件也上传到HDFS。此外,AM容器还提供Flink的Web界面。YARN代码分配的所有端口都是临时端口。这允许用户并行执行多个Flink YARN会话。
之后,AM开始为Flink的TaskManagers分配容器,这将从HDFS下载jar文件和修改后的配置。完成这些步骤后,即可建立Flink并准备接受作业。
2. 修改环境变量
export HADOOP_CONF_DIR= /opt/module/hadoop-2.7.6/etc/hadoop
3. 部署启动
[admin@node21 flink-1.6.1]$ yarn-session.sh -d -s 2 -tm 800 -n 2-n : TaskManager的数量,相当于executor的数量 -s : 每个JobManager的core的数量,executor-cores。建议将slot的数量设置每台机器的处理器数量 -tm : 每个TaskManager的内存大小,executor-memory -jm : JobManager的内存大小,driver-memory
上面的命令的意思是,同时向Yarn申请3个container,其中 2 个 Container 启动 TaskManager(-n 2),每个 TaskManager 拥有两个 Task Slot(-s 2),并且向每个 TaskManager 的 Container 申请 800M 的内存,以及一个ApplicationMaster(Job Manager)。

Flink部署到Yarn Cluster后,会显示Job Manager的连接细节信息。
Flink on Yarn会覆盖下面几个参数,如果不希望改变配置文件中的参数,可以动态的通过-D选项指定,如 -Dfs.overwrite-files=true -Dtaskmanager.network.numberOfBuffers=16368
jobmanager.rpc.address:因为JobManager会经常分配到不同的机器上
taskmanager.tmp.dirs:使用Yarn提供的tmp目录
parallelism.default:如果有指定slot个数的情况下
yarn-session.sh会挂起进程,所以可以通过在终端使用CTRL+C或输入stop停止yarn-session。
如果不希望Flink Yarn client长期运行,Flink提供了一种detached YARN session,启动时候加上参数-d或—detached
在上面的命令成功后,我们就可以在 Yarn Application 页面看到 Flink 的纪录。如下图。

如果在虚拟机中测试,可能会遇到错误。这里需要注意内存的大小,Flink 向 Yarn 会申请多个 Container,但是 Yarn 的配置可能限制了 Container 所能申请的内存大小,甚至 Yarn 本身所管理的内存就很小。这样很可能无法正常启动 TaskManager,尤其当指定多个 TaskManager 的时候。因此,在启动 Flink 之后,需要去 Flink 的页面中检查下 Flink 的状态。这里可以从 RM 的页面中,直接跳转(点击 Tracking UI)。这时候 Flink 的页面如图

yarn-session.sh启动命令参数如下:
[admin@node21 flink-1.6.1]$ yarn-session.sh --help
Usage:
Required
-n,--container <arg> Number of YARN container to allocate (=Number of Task Managers)
Optional
-D <property=value> use value for given property
-d,--detached If present, runs the job in detached mode
-h,--help Help for the Yarn session CLI.
-id,--applicationId <arg> Attach to running YARN session
-j,--jar <arg> Path to Flink jar file
-jm,--jobManagerMemory <arg> Memory for JobManager Container with optional unit (default: MB)
-m,--jobmanager <arg> Address of the JobManager (master) to which to connect. Use this flag to connect to a different JobManager than the one specified i
n the configuration. -n,--container <arg> Number of YARN container to allocate (=Number of Task Managers)
-nl,--nodeLabel <arg> Specify YARN node label for the YARN application
-nm,--name <arg> Set a custom name for the application on YARN
-q,--query Display available YARN resources (memory, cores)
-qu,--queue <arg> Specify YARN queue.
-s,--slots <arg> Number of slots per TaskManager
-st,--streaming Start Flink in streaming mode
-t,--ship <arg> Ship files in the specified directory (t for transfer)
-tm,--taskManagerMemory <arg> Memory per TaskManager Container with optional unit (default: MB)
-yd,--yarndetached If present, runs the job in detached mode (deprecated; use non-YARN specific option instead)
-z,--zookeeperNamespace <arg> Namespace to create the Zookeeper sub-paths for high availability mode
4. 提交任务
之后,我们可以通过这种方式提交我们的任务
[admin@node21 flink-1.6.1]$ ./bin/flink run -m yarn-cluster -yn 2 ./examples/batch/WordCount.jar --input /opt/wcinput/wc.txt --output /opt/wcoutput/
以上命令在参数前加上y前缀,-yn表示TaskManager个数。
在这个模式下,同样可以使用-m yarn-cluster提交一个"运行后即焚"的detached yarn(-yd)作业到yarn cluster。
5. 停止yarn cluster
yarn application -kill application_1539058959130_0001
6. Yarn模式的HA
应用最大尝试次数(yarn-site.xml),您必须配置为尝试应用的最大数量的设置yarn-site.xml,当前YARN版本的默认值为2(表示允许单个JobManager失败)。
<property> <name>yarn.resourcemanager.am.max-attempts</name> <value>4</value> <description>The maximum number of application master execution attempts</description> </property>
申请尝试(flink-conf.yaml),您还必须配置最大尝试次数conf/flink-conf.yaml: yarn.application-attempts:10
示例:高度可用的YARN会话
-
配置HA模式和zookeeper法定人数在
conf/flink-conf.yaml:high-availability: zookeeper high-availability.zookeeper.quorum: node21:2181,node22:2181,node23:2181 high-availability.storageDir: hdfs:///flink/recovery high-availability.zookeeper.path.root: /flink yarn.application-attempts: 10
-
配置ZooKeeper的服务器中
conf/zoo.cfg(目前它只是可以运行每台机器的单一的ZooKeeper服务器):server.1=node21:2888:3888 server.2=node22:2888:3888 server.3=node23:2888:3888
-
启动ZooKeeper仲裁:
$ bin / start-zookeeper-quorum.sh
-
启动HA群集:
$ bin / yarn-session.sh -n 2
五.错误异常
1.身份认证失败
[root@node21 flink-1.6.1]# flink run examples/streaming/SocketWindowWordCount.jar --port 9000
Starting execution of program
------------------------------------------------------------
The program finished with the following exception:
org.apache.flink.client.program.ProgramInvocationException: Job failed. (JobID: b7a99ac5db242290413dbebe32ba52b0)
at org.apache.flink.client.program.rest.RestClusterClient.submitJob(RestClusterClient.java:267)
at org.apache.flink.client.program.ClusterClient.run(ClusterClient.java:486)
at org.apache.flink.streaming.api.environment.StreamContextEnvironment.execute(StreamContextEnvironment.java:66)
at org.apache.flink.streaming.examples.socket.SocketWindowWordCount.main(SocketWindowWordCount.java:92)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.flink.client.program.PackagedProgram.callMainMethod(PackagedProgram.java:529)
at org.apache.flink.client.program.PackagedProgram.invokeInteractiveModeForExecution(PackagedProgram.java:421)
at org.apache.flink.client.program.ClusterClient.run(ClusterClient.java:426)
at org.apache.flink.client.cli.CliFrontend.executeProgram(CliFrontend.java:804)
at org.apache.flink.client.cli.CliFrontend.runProgram(CliFrontend.java:280)
at org.apache.flink.client.cli.CliFrontend.run(CliFrontend.java:215)
at org.apache.flink.client.cli.CliFrontend.parseParameters(CliFrontend.java:1044)
at org.apache.flink.client.cli.CliFrontend.lambda$main$11(CliFrontend.java:1120)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1754)
at org.apache.flink.runtime.security.HadoopSecurityContext.runSecured(HadoopSecurityContext.java:41)
at org.apache.flink.client.cli.CliFrontend.main(CliFrontend.java:1120)
Caused by: java.net.ConnectException: Connection refused (Connection refused)
at java.net.PlainSocketImpl.socketConnect(Native Method)
at java.net.AbstractPlainSocketImpl.doConnect(AbstractPlainSocketImpl.java:350)
at java.net.AbstractPlainSocketImpl.connectToAddress(AbstractPlainSocketImpl.java:206)
at java.net.AbstractPlainSocketImpl.connect(AbstractPlainSocketImpl.java:188)
at java.net.SocksSocketImpl.connect(SocksSocketImpl.java:392)
at java.net.Socket.connect(Socket.java:589)
at org.apache.flink.streaming.api.functions.source.SocketTextStreamFunction.run(SocketTextStreamFunction.java:96)
at org.apache.flink.streaming.api.operators.StreamSource.run(StreamSource.java:87)
at org.apache.flink.streaming.api.operators.StreamSource.run(StreamSource.java:56)
at org.apache.flink.streaming.runtime.tasks.SourceStreamTask.run(SourceStreamTask.java:99)
at org.apache.flink.streaming.runtime.tasks.StreamTask.invoke(StreamTask.java:300)
at org.apache.flink.runtime.taskmanager.Task.run(Task.java:711)
at java.lang.Thread.run(Thread.java:748)
通过查看日志,发现有如下报错
2018-10-20 02:32:19,668 ERROR org.apache.flink.shaded.curator.org.apache.curator.ConnectionState - Authentication failed
解决法案:添加定时任务认证kerberos
Flink开发IDEA环境搭建与测试
一.IDEA开发环境
1.pom文件设置
<properties>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<encoding>UTF-8</encoding>
<scala.version>2.11.12</scala.version>
<scala.binary.version>2.11</scala.binary.version>
<hadoop.version>2.7.6</hadoop.version>
<flink.version>1.6.1</flink.version>
</properties>
<dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-scala_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka-0.10_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.38</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.22</version>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/main/scala</sourceDirectory>
<testSourceDirectory>src/test/scala</testSourceDirectory>
<plugins>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.0</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
<configuration>
<args>
<!-- <arg>-make:transitive</arg> -->
<arg>-dependencyfile</arg>
<arg>${project.build.directory}/.scala_dependencies</arg>
</args>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.18.1</version>
<configuration>
<useFile>false</useFile>
<disableXmlReport>true</disableXmlReport>
<includes>
<include>**/*Test.*</include>
<include>**/*Suite.*</include>
</includes>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.0.0</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<transformers>
<transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>org.apache.spark.WordCount</mainClass>
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
2.flink开发流程
Flink具有特殊类DataSet并DataStream在程序中表示数据。您可以将它们视为可以包含重复项的不可变数据集合。在DataSet数据有限的情况下,对于一个DataStream元素的数量可以是无界的。
这些集合在某些关键方面与常规Java集合不同。首先,它们是不可变的,这意味着一旦创建它们就无法添加或删除元素。你也不能简单地检查里面的元素。
集合最初通过在弗林克程序添加源创建和新的集合从这些通过将它们使用API方法如衍生map,filter等等。
Flink程序看起来像是转换数据集合的常规程序。每个程序包含相同的基本部分:
1.获取execution environment,
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
2.加载/创建初始化数据
DataStream<String> text = env.readTextFile("file:///path/to/file");
3.指定此数据的转换
val mapped = input.map { x => x.toInt }
4.指定放置计算结果的位置
writeAsText(String path)
print()
5.触发程序执行
在local模式下执行程序
execute()
将程序达成jar运行在线上
./bin/flink run \
-m node21:8081 \
./examples/batch/WordCount.jar \
--input hdfs:///user/admin/input/wc.txt \
--output hdfs:///user/admin/output2 \
二. Wordcount案例
1.Scala代码
package com.xyg.streaming
import org.apache.flink.api.java.utils.ParameterTool
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.streaming.api.windowing.time.Time
/**
* Author: Mr.Deng
* Date: 2018/10/15
* Desc:
*/
object SocketWindowWordCountScala {
def main(args: Array[String]) : Unit = {
// 定义一个数据类型保存单词出现的次数
case class WordWithCount(word: String, count: Long)
// port 表示需要连接的端口
val port: Int = try {
ParameterTool.fromArgs(args).getInt("port")
} catch {
case e: Exception => {
System.err.println("No port specified. Please run 'SocketWindowWordCount --port <port>'")
return
}
}
// 获取运行环境
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
// 连接此socket获取输入数据
val text = env.socketTextStream("node21", port, '\n')
//需要加上这一行隐式转换 否则在调用flatmap方法的时候会报错
import org.apache.flink.api.scala._
// 解析数据, 分组, 窗口化, 并且聚合求SUM
val windowCounts = text
.flatMap { w => w.split("\\s") }
.map { w => WordWithCount(w, 1) }
.keyBy("word")
.timeWindow(Time.seconds(5), Time.seconds(1))
.sum("count")
// 打印输出并设置使用一个并行度
windowCounts.print().setParallelism(1)
env.execute("Socket Window WordCount")
}
}
2.Java代码
package com.xyg.streaming;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.util.Collector;
/**
* Author: Mr.Deng
* Date: 2018/10/15
* Desc: 使用flink对指定窗口内的数据进行实时统计,最终把结果打印出来
* 先在node21机器上执行nc -l 9000
*/
public class StreamingWindowWordCountJava {
public static void main(String[] args) throws Exception {
//定义socket的端口号
int port;
try{
ParameterTool parameterTool = ParameterTool.fromArgs(args);
port = parameterTool.getInt("port");
}catch (Exception e){
System.err.println("没有指定port参数,使用默认值9000");
port = 9000;
}
//获取运行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//连接socket获取输入的数据
DataStreamSource<String> text = env.socketTextStream("node21", port, "\n");
//计算数据
DataStream<WordWithCount> windowCount = text.flatMap(new FlatMapFunction<String, WordWithCount>() {
public void flatMap(String value, Collector<WordWithCount> out) throws Exception {
String[] splits = value.split("\\s");
for (String word:splits) {
out.collect(new WordWithCount(word,1L));
}
}
})//打平操作,把每行的单词转为<word,count>类型的数据
//针对相同的word数据进行分组
.keyBy("word")
//指定计算数据的窗口大小和滑动窗口大小
.timeWindow(Time.seconds(2),Time.seconds(1))
.sum("count");
//把数据打印到控制台,使用一个并行度
windowCount.print().setParallelism(1);
//注意:因为flink是懒加载的,所以必须调用execute方法,上面的代码才会执行
env.execute("streaming word count");
}
/**
* 主要为了存储单词以及单词出现的次数
*/
public static class WordWithCount{
public String word;
public long count;
public WordWithCount(){}
public WordWithCount(String word, long count) {
this.word = word;
this.count = count;
}
@Override
public String toString() {
return "WordWithCount{" +
"word='" + word + '\'' +
", count=" + count +
'}';
}
}
}
3.运行测试
首先,使用nc命令启动一个本地监听,命令是:
[admin@node21 ~]$ nc -l 9000
通过netstat命令观察9000端口。 netstat -anlp | grep 9000,启动监听如果报错:-bash: nc: command not found,请先安装nc,在线安装命令:yum -y install nc。
然后,IDEA上运行flink官方案例程序
node21上输入

IDEA控制台输出如下

4.集群测试
这里单机测试官方案例
[admin@node21 flink-1.6.1]$ pwd /opt/flink-1.6.1 [admin@node21 flink-1.6.1]$ ./bin/start-cluster.sh Starting cluster. Starting standalonesession daemon on host node21. Starting taskexecutor daemon on host node21. [admin@node21 flink-1.6.1]$ jps 2100 StandaloneSessionClusterEntrypoint 2518 TaskManagerRunner 2584 Jps [admin@node21 flink-1.6.1]$ ./bin/flink run examples/streaming/SocketWindowWordCount.jar --port 9000
程序连接到套接字并等待输入。您可以检查Web界面以验证作业是否按预期运行:


单词在5秒的时间窗口(处理时间,翻滚窗口)中计算并打印到stdout。监视TaskManager的输出文件并写入一些文本nc(输入在点击后逐行发送到Flink):


三. 使用IDEA开发离线程序
Dataset是flink的常用程序,数据集通过source进行初始化,例如读取文件或者序列化集合,然后通过transformation(filtering、mapping、joining、grouping)将数据集转成,然后通过sink进行存储,既可以写入hdfs这种分布式文件系统,也可以打印控制台,flink可以有很多种运行方式,如local、flink集群、yarn等.
1. scala程序
package com.xyg.batch
import org.apache.flink.api.scala.ExecutionEnvironment
import org.apache.flink.api.scala._
/**
* Author: Mr.Deng
* Date: 2018/10/19
* Desc:
*/
object WordCountScala{
def main(args: Array[String]) {
//初始化环境
val env = ExecutionEnvironment.getExecutionEnvironment
//从字符串中加载数据
val text = env.fromElements(
"Who's there?",
"I think I hear them. Stand, ho! Who's there?")
//分割字符串、汇总tuple、按照key进行分组、统计分组后word个数
val counts = text.flatMap { _.toLowerCase.split("\\W+") filter { _.nonEmpty } }
.map { (_, 1) }
.groupBy(0)
.sum(1)
//打印
counts.print()
}
}
2. java程序
package com.xyg.batch;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.DataSet;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;
/**
* Author: Mr.Deng
* Date: 2018/10/19
* Desc:
*/
public class WordCountJava {
public static void main(String[] args) throws Exception {
//构建环境
final ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
//通过字符串构建数据集
DataSet<String> text = env.fromElements(
"Who's there?",
"I think I hear them. Stand, ho! Who's there?");
//分割字符串、按照key进行分组、统计相同的key个数
DataSet<Tuple2<String, Integer>> wordCounts = text
.flatMap(new LineSplitter())
.groupBy(0)
.sum(1);
//打印
wordCounts.print();
}
//分割字符串的方法
public static class LineSplitter implements FlatMapFunction<String, Tuple2<String, Integer>> {
@Override
public void flatMap(String line, Collector<Tuple2<String, Integer>> out) {
for (String word : line.split(" ")) {
out.collect(new Tuple2<String, Integer>(word, 1));
}
}
}
}
3.运行

标签:Flink,系列,java,flink,node21,apache,org 来源: https://www.cnblogs.com/lucky-cat233/p/14245271.html