go 字符串
作者:互联网
一个字符串是一个不可改变的字节序列,字符串通常是用来包含人类可读的文本数据。和数组不同的是,字符串的元素不可修改,是一个只读的字节数组。每个字符串的长度虽然也是固定的,但是字符串的长度并不是字符串类型的一部分。由于Go语言的源代码要求是UTF8编码,导致Go源代码中出现的字符串面值常量一般也是UTF8编码的。源代码中的文本字符串通常被解释为采用UTF8编码的Unicode码点(rune)序列。因为字节序列对应的是只读的字节序列,因此字符串可以包含任意的数据,包括byte值0。我们也可以用字符串表示GBK等非UTF8编码的数据,不过这种时候将字符串看作是一个只读的二进制数组更准确,因为for range等语法并不能支持非UTF8编码的字符串的遍历。
Go语言字符串的底层结构在reflect.StringHeader中定义:
type StringHeader struct {
Data uintptr
Len int
}
字符串结构由两个信息组成:第一个是字符串指向的底层字节数组,第二个是字符串的字节的长度。字符串其实是一个结构体,因此字符串的赋值操作也就是reflect.StringHeader结构体的复制过程,并不会涉及底层字节数组的复制。在前面数组一节提到的[2]string字符串数组对应的底层结构和[2]reflect.StringHeader对应的底层结构是一样的,可以将字符串数组看作一个结构体数组。
我们可以看看字符串“Hello, world”本身对应的内存结构:
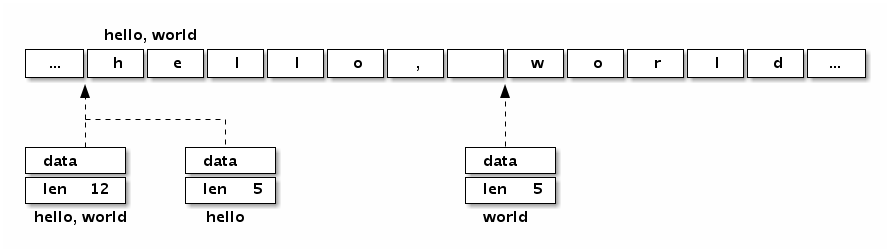
图 1-8 字符串布局
分析可以发现,“Hello, world”字符串底层数据和以下数组是完全一致的:
var data = [...]byte{
'h', 'e', 'l', 'l', 'o', ',', ' ', 'w', 'o', 'r', 'l', 'd',
}
字符串虽然不是切片,但是支持切片操作,不同位置的切片底层也访问的同一块内存数据(因为字符串是只读的,相同的字符串面值常量通常是对应同一个字符串常量):
s := "hello, world"
hello := s[:5]
world := s[7:]
s1 := "hello, world"[:5]
s2 := "hello, world"[7:]
字符串和数组类似,内置的len函数返回字符串的长度。也可以通过reflect.StringHeader结构访问字符串的长度(这里只是为了演示字符串的结构,并不是推荐的做法):
fmt.Println("len(s):", (*reflect.StringHeader)(unsafe.Pointer(&s)).Len) // 12
fmt.Println("len(s1):", (*reflect.StringHeader)(unsafe.Pointer(&s1)).Len) // 5
fmt.Println("len(s2):", (*reflect.StringHeader)(unsafe.Pointer(&s2)).Len) // 5
根据Go语言规范,Go语言的源文件都是采用UTF8编码。因此,Go源文件中出现的字符串面值常量一般也是UTF8编码的(对于转义字符,则没有这个限制)。提到Go字符串时,我们一般都会假设字符串对应的是一个合法的UTF8编码的字符序列。可以用内置的print调试函数或fmt.Print函数直接打印,也可以用for range循环直接遍历UTF8解码后的Unicode码点值。
下面的“Hello, 世界”字符串中包含了中文字符,可以通过打印转型为字节类型来查看字符底层对应的数据:
fmt.Printf("%#v\n", []byte("Hello, 世界"))
输出的结果是:
[]byte{0x48, 0x65, 0x6c, 0x6c, 0x6f, 0x2c, 0x20, 0xe4, 0xb8, 0x96, 0xe7, \
0x95, 0x8c}
分析可以发现0xe4, 0xb8, 0x96对应中文“世”,0xe7, 0x95, 0x8c对应中文“界”。我们也可以在字符串面值中直指定UTF8编码后的值(源文件中全部是ASCII码,可以避免出现多字节的字符)。
fmt.Println("\xe4\xb8\x96") // 打印: 世
fmt.Println("\xe7\x95\x8c") // 打印: 界
下图展示了“Hello, 世界”字符串的内存结构布局:

图 1-9 字符串布局
Go语言的字符串中可以存放任意的二进制字节序列,而且即使是UTF8字符序列也可能会遇到坏的编码。如果遇到一个错误的UTF8编码输入,将生成一个特别的Unicode字符‘\uFFFD’,这个字符在不同的软件中的显示效果可能不太一样,在印刷中这个符号通常是一个黑色六角形或钻石形状,里面包含一个白色的问号‘�’。
下面的字符串中,我们故意损坏了第一字符的第二和第三字节,因此第一字符将会打印为“�”,第二和第三字节则被忽略,后面的“abc”依然可以正常解码打印(错误编码不会向后扩散是UTF8编码的优秀特性之一)。
fmt.Println("\xe4\x00\x00\xe7\x95\x8cabc") // �界abc
不过在for range迭代这个含有损坏的UTF8字符串时,第一字符的第二和第三字节依然会被单独迭代到,不过此时迭代的值是损坏后的0:
for i, c := range "\xe4\x00\x00\xe7\x95\x8cabc" {
fmt.Println(i, c)
}
// 0 65533 // \uFFFD, 对应 �
// 1 0 // 空字符
// 2 0 // 空字符
// 3 30028 // 界
// 6 97 // a
// 7 98 // b
// 8 99 // c
如果不想解码UTF8字符串,想直接遍历原始的字节码,可以将字符串强制转为[]byte字节序列后再行遍历(这里的转换一般不会产生运行时开销):
for i, c := range []byte("世界abc") {
fmt.Println(i, c)
}
或者是采用传统的下标方式遍历字符串的字节数组:
const s = "\xe4\x00\x00\xe7\x95\x8cabc"
for i := 0; i < len(s); i++ {
fmt.Printf("%d %x\n", i, s[i])
}
Go语言除了for range语法对UTF8字符串提供了特殊支持外,还对字符串和[]rune类型的相互转换提供了特殊的支持。
fmt.Printf("%#v\n", []rune("世界")) // []int32{19990, 30028}
fmt.Printf("%#v\n", string([]rune{'世', '界'})) // 世界
从上面代码的输出结果来看,我们可以发现[]rune其实是[]int32类型,这里的rune只是int32类型的别名,并不是重新定义的类型。rune用于表示每个Unicode码点,目前只使用了21个bit位。
字符串相关的强制类型转换主要涉及到[]byte和[]rune两种类型。每个转换都可能隐含重新分配内存的代价,最坏的情况下它们的运算时间复杂度都是O(n)。不过字符串和[]rune的转换要更为特殊一些,因为一般这种强制类型转换要求两个类型的底层内存结构要尽量一致,显然它们底层对应的[]byte和[]int32类型是完全不同的内部布局,因此这种转换可能隐含重新分配内存的操作。
下面分别用伪代码简单模拟Go语言对字符串内置的一些操作,这样对每个操作的处理的时间复杂度和空间复杂度都会有较明确的认识。
for range对字符串的迭代模拟实现
func forOnString(s string, forBody func(i int, r rune)) {
for i := 0; len(s) > 0; {
r, size := utf8.DecodeRuneInString(s)
forBody(i, r)
s = s[size:]
i += size
}
}
for range迭代字符串时,每次解码一个Unicode字符,然后进入for循环体,遇到崩坏的编码并不会导致迭代停止。
[]byte(s)转换模拟实现
func str2bytes(s string) []byte {
p := make([]byte, len(s))
for i := 0; i < len(s); i++ {
c := s[i]
p[i] = c
}
return p
}
模拟实现中新创建了一个切片,然后将字符串的数组逐一复制到了切片中,这是为了保证字符串只读的语义。当然,在将字符串转为[]byte时,如果转换后的变量并没有被修改的情形,编译器可能会直接返回原始的字符串对应的底层数据。
string(bytes)转换模拟实现
func bytes2str(s []byte) (p string) {
data := make([]byte, len(s))
for i, c := range s {
data[i] = c
}
hdr := (*reflect.StringHeader)(unsafe.Pointer(&p))
hdr.Data = uintptr(unsafe.Pointer(&data[0]))
hdr.Len = len(s)
return p
}
因为Go语言的字符串是只读的,无法直接同构构造底层字节数组生成字符串。在模拟实现中通过unsafe包获取了字符串的底层数据结构,然后将切片的数据逐一复制到了字符串中,这同样是为了保证字符串只读的语义不会受切片的影响。如果转换后的字符串在生命周期中原始的[]byte的变量并不会发生变化,编译器可能会直接基于[]byte底层的数据构建字符串。
[]rune(s)转换模拟实现
func str2runes(s string) []rune{
var p []int32
for len(s)>0 {
r,size:=utf8.DecodeRuneInString(s)
p=append(p,int32(r))
s=s[size:]
}
return []rune(p)
}
因为底层内存结构的差异,字符串到[]rune的转换必然会导致重新分配[]rune内存空间,然后依次解码并复制对应的Unicode码点值。这种强制转换并不存在前面提到的字符串和字节切片转化时的优化情况。
string(runes)转换模拟实现
func runes2string(s []int32) string {
var p []byte
buf := make([]byte, 3)
for _, r := range s {
n := utf8.EncodeRune(buf, r)
p = append(p, buf[:n]...)
}
return string(p)
}
同样因为底层内存结构的差异,[]rune到字符串的转换也必然会导致重新构造字符串。这种强制转换并不存在前面提到的优化情况。
标签:字节,UTF8,fmt,字符串,rune,go,byte 来源: https://www.cnblogs.com/ithubb/p/14185028.html