【翻译】Apache Flink 1.12.0 Release Announcement
作者:互联网
本文来自官网: https://flink.apache.org/news/2020/12/10/release-1.12.0.html
2020年12月10日Marta Paes(@morsapaes)和Aljoscha Krettek(@aljoscha)
Apache Flink社区很高兴地宣布 Flink 1.12.0 发布了!近 300 个 contributors 在1000个 threads 上工作,对可用性进行了重大改进,并提供了简化(并统一)整个API堆栈的Flink处理的新功能。
发布要点
-
社区增加了对 DataStream API 中有效批处理执行的支持。这是实现批处理和流处理的真正统一运行时的下一个重要里程碑。
-
基于 Kubernetes 的高可用性(HA)作为高可用性生产设置的ZooKeeper的替代产品而实现。
-
Kafka SQL 连接器已扩展为可以在 upsert 模式下工作,并且能够处理 SQL DDL 中的连接器元数据。现在,临时表联接也可以用 SQL 完全表示,而不再依赖于 Table API。
-
为支持在 PyFlink 的数据流中的 API 扩展了它的使用更复杂的情况,需要在 state 和 time 的细粒度控制,现在可以在 Kubernetes 上本地部署 PyFlink 任务。
这篇博客文章描述了所有主要的新功能和改进,需要注意的重要更改以及预期的发展。
- 新功能和改进
- DataStream API 中的批处理执行模式
- 新的 Data Sink API(测试版)
- Kubernetes 高可用性(HA)服务
- 其他改进
- Table API / SQL:SQL连接器中的元数据处理
- Table API / SQL:Upsert Kafka连接器
- Table API / SQL:在SQL中支持临时表联接
- Table API / SQL的其他改进
- PyFlink:Python DataStream API
- PyFlink的其他改进
- 重要变化
- Release Notes
- 贡献者名单
Apache Flink 1.12.0发行公告
2020年12月10日Marta Paes(@morsapaes)和Aljoscha Krettek(@aljoscha)
Apache Flink社区很高兴宣布Flink 1.12.0的发布!近300个贡献者在1000个线程上进行了工作,以显着提高可用性以及新功能,这些功能简化了(并统一了)整个API堆栈的Flink处理。
发布要点
-
社区增加了对DataStream API中有效批处理执行的支持。这是实现批处理和流处理的真正统一运行时的下一个重要里程碑。
-
基于Kubernetes的高可用性(HA)被实现为ZooKeeper的替代产品,以实现高可用性的生产设置。
-
Kafka SQL连接器已扩展为可以在upsert模式下工作,并且能够处理SQL DDL中的连接器元数据。现在,临时表联接也可以用SQL完全表示,而不再依赖于Table API。
-
为支持在PyFlink的数据流中的API扩展了它的使用更复杂的情况,需要在国家和时间的细粒度控制,而且它现在可以在本地部署PyFlink工作Kubernetes。
这篇博客文章描述了所有主要的新功能和改进,需要注意的重要更改以及预期的发展。
现在,可以在Flink网站的更新的“下载”页面上找到二进制发布包和源码包,并且可以在 PyPI 上获得最新的 PyFlink 发布包。请仔细阅读 release notes,并查看完整的发行变更日志和更新文档以获取更多详细信息。
我们鼓励您下载这个发行版,并通过Flink邮件列表或JIRA与社区分享您的反馈。
新功能和改进
DataStream API 中的批处理执行模式
Flink 的核心 API 在项目的整个生命周期中都得到了有机开发,并且最初在设计时就考虑了特定的用例。尽管Table API / SQL已经具有统一的算子,但使用较低级别的抽象仍然需要您在批处理(DataSet API)和流式(DataStream API)的两个语义上不同的API之间进行选择。由于批处理是无限制流的子集,因此将它们合并到单个API中有一些明显的优势:
-
可重用性:在同一 API 下进行有效的批处理和流处理将使您可以轻松地在两种执行模式之间切换,而无需重写任何代码。因此,可以轻松地重用作业来处理实时和历史数据。
-
操作简便性:提供统一的API将意味着使用同一组连接器,维护单个代码库并能够轻松实现混合执行管道,例如用于回填之类的用例。
考虑到这些优点,社区已朝着统一DataStream API迈出了第一步:支持高效的批处理执行(FLIP-134)。从长远来看,这意味着 DataSet API 将被 DataStream API 和 Table API / SQL(FLIP-131)弃用和包含。对于统一工作的概述,请参阅这次最近的 Flink Forward 大会。
批处理流
您已经可以使用DataStream API来处理有界的流(例如文件),其限制是运行时不“知道”作业是有界的。为了优化有界输入的 runtime ,新 BATCH 模式执行使用基于排序的 shuffles (具有纯内存的聚合)和改进的调度策略(请参见流水线区域调度)。结果,BATCH DataStream API 中的模式执行已经非常接近 Flink 1.12 中DataSet API 的性能。有关性能基准的更多详细信息,请查看原始提案(FLIP-140)。

在 Flink 1.12 中,默认执行模式为 STREAMING。要配置作业以 BATCH 模式运行,您可以在提交作业时设置配置:
bin/flink run -Dexecution.runtime-mode=BATCH examples/streaming/WordCount.jar
,或以编程方式执行:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setRuntimeMode(RuntimeMode.BATCH);
注意:尽管尚未弃用 DataSet API,但我们建议用户优先使用具有 BATCH 执行模式的 DataStream API 来执行新的批处理作业,并考虑迁移现有的 DataSet 作业。
新的 Data Sink API(Beta)
在以前的版本中,已经确保 Data Source 连接器可以同时在两种执行模式下工作,因此在Flink 1.12中,社区专注于实现统一的 Data Sink API(FLIP-143)。新的抽象引入了 write/commit protocol 和一个更加模块化的接口,其中各个组件透明地暴露给框架。
一个 Data Sink 实现必须提供 what 和 How:SinkWriter 写入哪些需要提交的数据和输出(即 committables ); 以及封装了如何处理提交表的Committer和GlobalCommitter。该框架负责 when 和 where:在什么时间和在 which 机器或程序提交。
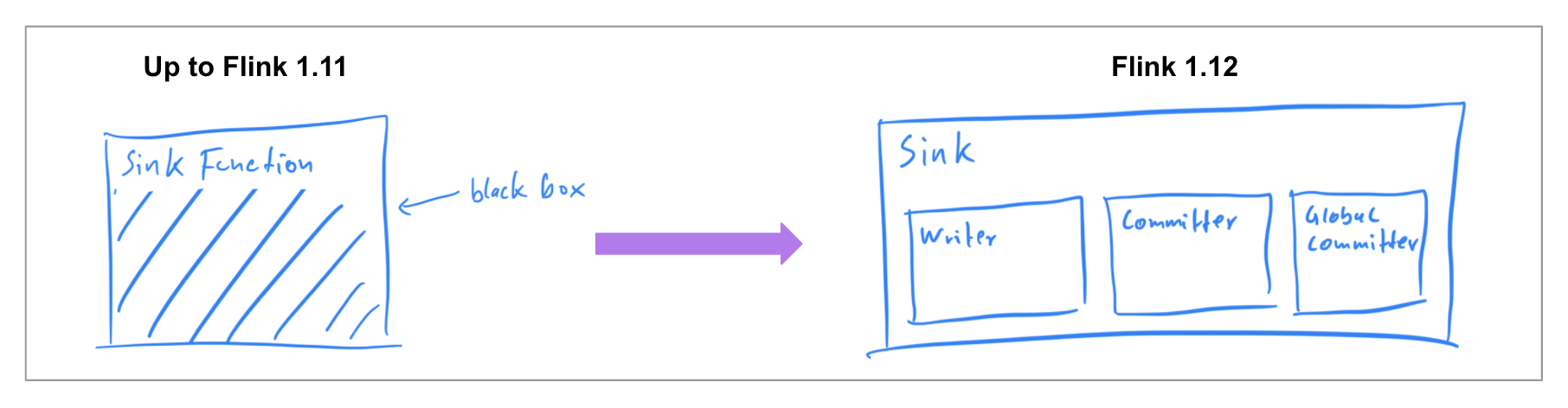
这种更加模块化的抽象允许为 BATCH 和 STREAMING 模式执行不同的 runtime 实现,这些 runtime 实现了预期的目的,但是仅使用一个统一的 data sink 实现。在Flink 1.12中,FileSink 连接器是 StreamingFileSink(FLINK-19758)的统一替代品。其余的连接器将在未来的版本中移植到新接口。
Kubernetes高可用性(HA)服务
Kubernetes 提供了Flink可以用于 JobManager 故障转移的内置功能,而不是依赖 ZooKeeper。为了启用 “ ZooKeeperless” HA 设置,社区在 Flink 1.12(FLIP-144)中实现了 Kubernetes HA 服务。该服务与 ZooKeeper 实现基于相同的基本接口构建,并使用 Kubernetes 的 ConfigMap 对象处理从 JobManager 故障中恢复所需的所有元数据。有关如何配置高可用性 Kubernetes 集群的更多详细信息和示例,请参阅文档。
注意:这并不意味着将删除 ZooKeeper 依赖,而只是在 Kubernetes 上为 Flink 用户提供了替代方法。
其他改进
将现有的 connector 迁移到新的 Data Source API先前版本引入了新的 Data Source API(FLIP-27),允许实现既可以作为有界(批处理)源也可以作为无界(流式)源使用的 connector。在 Flink 1.12 中,社区开始从 FileSystem 连接器(FLINK-19161)开始将现有 source 连接器移植到新接口。
注意:统一的 source 实现将是完全独立的连接器,与旧版本不兼容。
Pipelined Region 调度(FLIP-119)
Flink 的调度程序在很大程度上是分别为批处理和流处理工作负载而设计的。此版本引入了统一的调度策略,该策略可识别 blocking 的数据交换,以将执行图分解为 Pipelined Region。这样,仅当有数据可以执行工作时才调度每个区域,并且仅在所有必需的资源都可用时才部署它。以及独立重启失败的区域。特别是对于批处理作业,新策略可提高资源利用率,并消除死锁。
支持 Sort-Merge Shuffles(FLIP-148)
为了提高大规模批处理作业的稳定性,性能和资源利用率,社区引入了 sort-merge shuffle,以替代 Flink 已经使用的原始 shuffle 实现。这种方法可以显着减少 shuffle 时间,并使用更少的文件句柄和文件写入缓冲区(这对于大规模作业是有问题的)。后续版本(FLINK-19614)中将实现进一步的优化。
注意:此功能是实验性的,默认情况下未启用。要启用 sort-merge shuffle,您可以在 TaskManager 网络配置选项中配置合理的最小并行度阈值。
对Flink WebUI(FLIP-75)的改进
作为对 Flink WebUI 的一系列改进的延续,该社区致力于在 WebUI(FLIP-104)上公开 JobManager 的内存相关指标和配置参数。TaskManager 的指标页面也已更新,以反映对 Flink 1.10(FLIP-102)中引入的 TaskManager 内存模型的更改,并为托管内存,网络内存和元空间添加了新的指标。
Table API / SQL:SQL 连接器中的元数据处理
某些 Source(和 Format)将其他字段公开为元数据,这些字段对于用户与记录数据一起处理是很有价值的。一个常见的例子是 kafka,你可能要如 访问 offset,partition 或 topic 的信息,读/写记录 key 或使用嵌入的元数据的 timestamp 基于时间的操作。在新版本中,Flink SQL支持元数据列以读取和写入表每一行的特定于连接器和格式的字段(FLIP-107)。这些列在CREATE TABLE语句中使用METADATA(保留)关键字声明。
CREATE TABLE kafka_table ( id BIGINT, name STRING, event_time TIMESTAMP(3) METADATA FROM 'timestamp', -- access Kafka 'timestamp' metadata headers MAP<STRING, BYTES> METADATA -- access Kafka 'headers' metadata ) WITH ( 'connector' = 'kafka', 'topic' = 'test-topic', 'format' = 'avro' );
在 Flink 1.12 中,公开了 Kafka 和 Kinesis 连接器的元数据,并且已经计划在 FileSystem 连接器上支持(FLINK-19903)。由于 Kafka 记录的结构更为复杂,因此还专门为 Kafka 连接器实现了新属性,以控制如何处理键/值对。有关 Flink SQL 中元数据支持的完整概述,请查看每个连接器的文档以及原始提案中的用例。
Table API / SQL:Upsert Kafka 连接器
对于某些用例,例如 interpreting compacted topics 或写出(更新)汇总结果,有必要将 Kafka 记录键作为真正的主键来处理,以确定可以插入,删除或更新的内容。为了实现这一点,社区创建了一个专用的 upsert 连接器(upsert-kafka),用于扩展基本实现以在upsert 模式(FLIP-149)中工作。
新的 upsert-kafka 连接器可用于 Source 和 Sink ,并提供与现有 Kafka 连接器相同的基本功能和持久性保证,因为它下重用了大部分代码。要使用 upsert-kafka connector,您必须在创建表时定义一个主键约束,并为键(key.format)和值(value.format)指定(反序列化)格式。
Table API / SQL:在SQL中支持 Temporal Table Joins
现在,您无需创建临时表函数来在某个特定时间点查询表,而只需使用标准 SQL 子句 FOR SYSTEM_TIME AS OF(SQL:2011)来表示临时表联接。此外,现在支持对具有时间属性和主键的任何类型的表进行时态联接,而不仅仅是 append-only table。这可以解锁一组新的用例,例如直接针对 Kafka compacted 的主题或数据库变更日志(例如,来自Debezium)执行临时联接。
-- Table backed by a Kafka topic
CREATE TABLE orders (
order_id STRING,
currency STRING,
amount INT,
order_time TIMESTAMP(3),
WATERMARK FOR order_time AS order_time - INTERVAL '30' SECOND
) WITH (
'connector' = 'kafka',
...
);
-- Table backed by a Kafka compacted topic
CREATE TABLE latest_rates (
currency STRING,
currency_rate DECIMAL(38, 10),
currency_time TIMESTAMP(3),
WATERMARK FOR currency_time AS currency_time - INTERVAL '5' SECOND,
PRIMARY KEY (currency) NOT ENFORCED
) WITH (
'connector' = 'upsert-kafka',
...
);
-- Event-time temporal table join
SELECT
o.order_id,
o.order_time,
o.amount * r.currency_rate AS amount,
r.currency
FROM orders AS o, latest_rates FOR SYSTEM_TIME AS OF o.order_time r
ON o.currency = r.currency;
前面的示例还显示了如何在 temporal table joins 的上下文中利用新的 upsert-kafka 连接器。
Hive Tables in Temporal Table Joins
您还可以通过自动读取最新的表分区作为 temporal table(FLINK-19644)或整个表作为在执行时跟踪最新版本的有界流来对 Hive 表执行 temporal table join。有关在临时表联接中使用Hive表的示例,请参考文档。
Table API / SQL的其他改进
Kinesis Flink SQL 连接器(FLINK-18858)
从 Flink 1.12开始,Table API / SQL 本身也支持将 Amazon Kinesis Data Streams(KDS)作为 source/sink 。新的 Kinesis SQL 连接器随附对增强的扇出(EFO)和 sink 分区的支持。有关支持的功能,配置选项和公开的元数据的完整概述,请查看更新的文档。
FileSystem / Hive 连接器中的 streaming sink 压缩(FLINK-19345)
当写为大文件时,许多批量格式(例如Parquet)是最有效的。当启用频繁 checkpoint 时,这是一个挑战,因为创建的小文件太多(需要在检查点上滚动)。在 Flink 1.12中,fink sink 支持文件压缩,从而允许作业保留较小的 checkpoint 间隔,而不会生成大量文件。要启用文件压缩,您可以按照文档中的说明设置 FileSystem 连接器的属性 auto-compaction=true。
Kafka 连接器中的水印下推(FLINK-20041)
为了确保从 Kafka 消费时的正确性,通常最好在每个分区的基础上生成水印,因为分区中的乱序通常比所有分区中的乱序性要低。Flink 现在将下推水印策略,以从 Kafka 内部发出分区的水印。source 的输出水印将由其读取的分区上的最小水印确定,从而产生更好(即更接近实时)的水印。通过水印下推功能,您还可以配置分区的空闲状态检测,以防止空闲分区阻止整个应用程序的事件时间进度。
新支持的格式
| Format | Description | Supported Connectors |
|---|---|---|
| Avro Schema Registry | 读写 Confluent Schema Registry KafkaAvroSerializer 序列化的数据。 | Kafka, Upsert Kafka |
| Debezium Avro | 读取和写入使用Confluent Schema Registry KafkaAvroSerializer序列化的Debezium记录。 | Kafka |
| Maxwell (CDC) | 读写 Maxwell JSON 记录. |
Kafka FileSystem |
| Raw | 读写 raw (byte-based) 值做为一列值. |
Kafka, Upsert Kafka Kinesis FileSystem |
用于联接优化的多输入运算符(FLINK-19621)
为了消除不必要的序列化和数据溢出并提高批处理和流表API / SQL作业的性能,default planner 现在利用最新版本(FLIP-92)中引入的 N-ary stream operator 来实现运算符的“链接”通过前边缘连接。
Table API UDAF的类型推断(FLIP-65)
此版本结束了 Flink 1.9 中针对 Table API 的新数据类型系统上的工作,并向该新类型系统公开了聚合函数(UDAF)。从 Flink 1.12 开始,UDAF 的行为类似于标量和表函数,并支持所有数据类型。
PyFlink:Python DataStream API
为了扩展 PyFlink 的可用性,此版本引入了 Python DataStream API(FLIP-130)的第一个版本,该版本支持无状态操作(例如Map,FlatMap,Filter,KeyBy)。
from pyflink.common.typeinfo import Types
from pyflink.datastream import MapFunction, StreamExecutionEnvironment
class MyMapFunction(MapFunction):
def map(self, value):
return value + 1
env = StreamExecutionEnvironment.get_execution_environment()
data_stream = env.from_collection([1, 2, 3, 4, 5], type_info=Types.INT())
mapped_stream = data_stream.map(MyMapFunction(), output_type=Types.INT())
mapped_stream.print()
env.execute("datastream job")
PyFlink 的其他改进
Kubernetes 上的 PyFlink作业(FLINK-17480)
除了独立部署和 YARN 部署之外,PyFlink 作业现在还可以本地部署在 Kubernetes 上。该部署文档都有详细的关于如何启动一个指令会话或应用 Kubernetes 集群。
用户定义的汇总函数(UDAF)
在 Flink 1.12中,您可以在 PyFlink(FLIP-139)中定义和注册 UDAF 。与不处理状态并且一次只处理一行的普通 UDF 相比,UDAF 是有状态的,可用于计算多个输入行上的自定义聚合。要从矢量化中受益,您还可以使用Pandas UDAF(FLIP-137)(最快10倍)。
注意:常规UDAF仅在 group aggregations and in streaming mode 下受支持。对于批处理模式或窗口聚合,请使用Pandas UDAF。
重要变化
-
[ FLINK-19319 ]默认流时间特征已更改为
EventTime,因此您不再需要调用StreamExecutionEnvironment.setStreamTimeCharacteristic()以启用事件时间支持。 -
[ FLINK-19278 ] Flink现在依赖于 Scala Macros 2.1.1,因此不再支持<2.11.11的Scala版本。
-
[ FLINK-19152 ]此版本中已删除了 Kafka 0.10.x 和 0.11.x 连接器。如果您仍在使用这些版本,请参阅文档以了解如何升级到通用 Kafka 连接器。
-
[ FLINK-18795 ] HBase 连接器已升级到最新的稳定版本(2.2.3)。
-
[ FLINK-17877 ] PyFlink 现在支持Python 3.8。
-
[ FLINK-18738 ]为了与 FLIP-53 保持一致,托管内存现在也是 Python worker 的默认设置。配置
python.fn-execution.buffer.memory.size和python.fn-execution.framework.memory.size已被删除,将不再生效。
发行说明
如果您打算将安装程序升级到Flink 1.12(注:官网写的是 1.11, 写错了),请仔细查看发行说明,以获取详细的更改和新功能列表。此版本与使用@Public批注进行批注的API的1.x早期版本兼容。
贡献者名单
Apache Flink社区要感谢使该版本成为可能的300位贡献者中的每一位
(重复太多,跳过)
标签:Announcement,1.12,Flink,Kafka,API,连接器,SQL,Table 来源: https://www.cnblogs.com/Springmoon-venn/p/14136153.html