机器学习基础--一些基本的概念
作者:互联网
前言
开始重新巩固一下机器学习的内容,先从基本的一些概念和定义开始。
本文介绍的内容如下所示:
- 机器学习的基本定义
- 局部最优和全局最优
- 机器学习、深度学习、数据挖掘、大数据之间的关系
- 为什么要使用机器学习
1. 机器学习的基本定义
机器学习算法是一种能够从数据中学习的算法。那么这里的学习的定义是什么呢?这里有一个简单的定义:
对于某类任务 T 和性能度量 P,一个计算机程序通过经验 E 改进后,在任务 T 上由性能度量 P 衡量的性能有所提升,这称为学习。
举例来说这个定义,比如对于图像分类这个任务,一般的性能度量 P 就是分类的准确率,而经验 E 其实就是图片数据集,当我们采用的算法,比如 CNN,在给定的训练集上训练后,然后在测试集上的准确率有所提升,这就是学习了。
这里的任务 T、经验 E 和性能 P 其实指代的内容非常的多,这里简单的介绍一下。
首先,对于任务 T,在机器学习领域里,可以是这些方向的任务:
-
分类:在该任务中计算机程序需要判断输入数据是属于给的 k 类中的哪一类,最常见的就是人脸识别,也是图像分类的一个子方向,另外还有语音识别、文本识别等;
-
回归:在该任务中需要对给定的输入预测数值,比如预测房价或者证券未来的价格等;
-
转录:将一些相对非结构化表示的数据,转录为离散的文本形式。比如 OCR(光学字符识别)、语音识别等;
-
机器翻译:将一种语言的序列转化为另一种语言。比如英语翻译为中文;
-
异常检测:查找不正常或者非典型的个体;
-
去噪
-
等等
对于性能度量 P,在不同的任务中会采用不同的性能指标,比如:
- 准确率和错误率
- 召回率、精准率、F1
- ROC 和 AUC
- 均方误差(MSE)、均方根误差(RMSE)
- 交并比 IoU
而经验 E,一般就是指数据集了,不同的任务对数据集的要求也不一样,比如图片分类一般就是图片和图片的标签,但目标检测、图像分割,需要的除了图片、标签,有的还需要图片中物体的标注框或者坐标信息等。
2. 局部最优和全局最优
优化问题一般分为局部最优和全局最优。其中,
- 局部最优,就是在函数值空间的一个有限区域内寻找最小值;而全局最优,是在函数值空间整个区域寻找最小值问题。
- 函数局部最小点是它的函数值小于或等于附近点的点,但是有可能大于较远距离的点。
- 全局最小点是那种它的函数值小于或等于所有的可行点。
2.1 如何区分局部最小点和鞍点
参考知乎回答:
通常一阶导数为 0 的点称为稳定点,可以分为三类:
- 局部最小点
- 局部最大点
- 鞍点
鞍点如下所示:
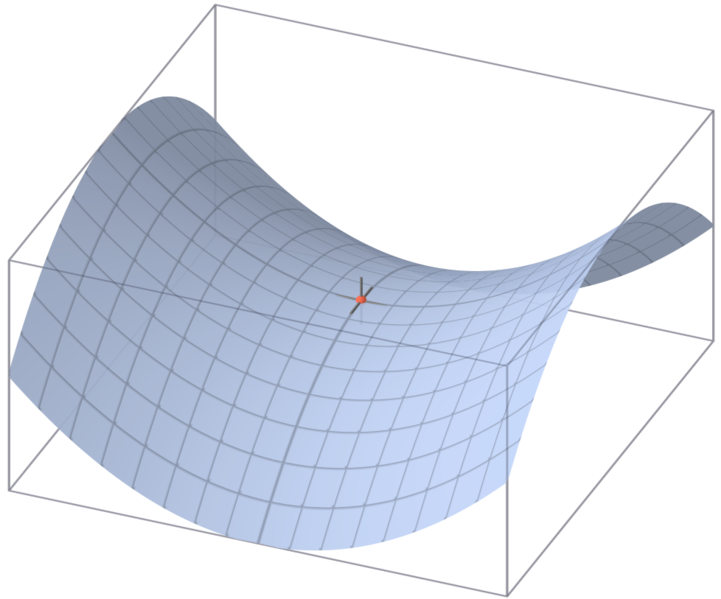
一般区分鞍点和局部最优的方法是使用神经网络 loss surface 的 Hessian 矩阵,通过计算 Hessian 矩阵的特征值,进行判断:
- 当 Hessian 矩阵的特征值有正有负的时候,神经网络的一阶导数为 0 的点是鞍点;
- 当 Hessian 矩阵的特征值是非负的时候,神经网络的一阶导数为 0 的点是局部极小值点;
- 当 Hessian 矩阵最小特征值小于零,则为严格鞍点(包含了局部最大)
根据文章:Geometry of Neural Network Loss Surfaces via Random Matrix Theory,可以看到神经网络的 Hessian 矩阵的特征值分布如下:
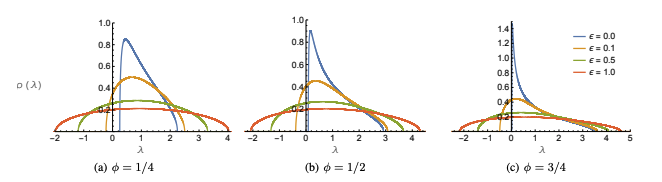
其中 $\phi$ 表示参数数目和数据量之比,其值越大表示数量相对较少,$\lambda$ 是特征值,$\epsilon$ 表示 loss 值,所以从上图可以得到:
- 当 loss 很大的时候,特征值有正有负,表明鞍点是困扰优化的主要原因;
- 当 loss 很小的时候,特征值慢慢都是非负数,也就是说这个时候基本是局部最小点。
另外一种判断是否是鞍点的方法:若某个一阶导数为0的点在至少一个方向上的二阶导数小于0,那它就是鞍点。
最优点和鞍点的区别在于其在各个维度是否都是最低点。
只要某个一阶导数为0的点在某个维度上是最高点而不是最低点,那它就是鞍点。而区分最高点和最低点当然就是用二阶导数,斜率从负变正的过程当然就是“下凸”,即斜率的导数大于0,即二阶导数大于0。反之则为“上凹”,二阶导数小于0。
2.2 如何避免陷入局部最小值或者鞍点
实际上,我们并不需要害怕陷入局部最小值,原因有这几个:
-
第一个,很直观的解释来自于上面特征值的分布信息:当loss很小的时候,我们才会遇到局部最小值问题,也就是说这时候的loss已经足够小,我们对这时候的loss已经足够满意了,不太需要花更大力气去找全局最优值。
-
第二个,在一定假设条件下,很多研究表明深度学习中局部最小值很接近于全局最小值。
另外,根据https://www.zhihu.com/question/68109802的回答:
实际上我们可能并没有找到过”局部最优“,更别说全局最优了;
”局部最优是神经网络优化的主要难点“,这其实是来自于一维优化问题的直观想象,单变量的情况下,优化问题最直观的困难就是有很多局部极值。但在多变量的情况下,就不一定能找到局部最优了;
而对于鞍点,逃离鞍点的做法有这几种:
- 利用严格鞍点负特征值对应的方向,采用矩阵向量乘积的形式找到下降方向;
- 利用扰动梯度方法逃离鞍点,在梯度的模小于某个数的时候,在梯度上加个动量。
3. 机器学习、深度学习、数据挖掘、大数据之间的关系
首先来看这四者简单的定义:
- 大数据通常被定义为“超出常用软件工具捕获,管理和处理能力”的数据集,一般是在数据量、数据速度和数据类别三个维度上都大的问题。
- 机器学习关心的问题是如何构建计算机程序使用经验自动改进。
- 数据挖掘是从数据中提取模式的特定算法的应用,在数据挖掘中,重点在于算法的应用,而不是算法本身。
- 深度学习是机器学习的一个子类,一般特指学习层数较高的网络结构,这个结构通常会结合线性和非线性的关系。
关于这四个的关系,可以如下图所示:
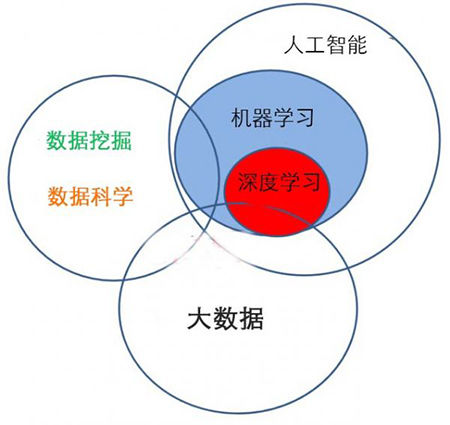
机器学习和数据挖掘之间的关系如下:
数据挖掘是一个过程,在此过程中机器学习算法被用作提取数据集中的潜在有价值模式的工具。
大数据与深度学习关系总结如下:
(1)深度学习是一种模拟大脑的行为。可以从所学习对象的机制以及行为等等很多相关联的方面进行学习,模仿类型行为以及思维。
(2)深度学习对于大数据的发展有帮助。深度学习对于大数据技术开发的每一个阶段均有帮助,不管是数据的分析还是挖掘还是建模,只有深度学习,这些工作才会有可能一一得到实现。
(3)深度学习转变了解决问题的思维。很多时候发现问题到解决问题,走一步看一步不是一个主要的解决问题的方式了,在深度学习的基础上,要求我们从开始到最后都要基于一个目标,为了需要优化的那个最终目标去进行处理数据以及将数据放入到数据应用平台上去,这就是端到端(End to End)。
(4)大数据的深度学习需要一个框架。在大数据方面的深度学习都是从基础的角度出发的,深度学习需要一个框架或者一个系统。总而言之,将你的大数据通过深度分析变为现实,这就是深度学习和大数据的最直接关系。
机器学习和深度学习的关系:
- 深度学习是机器学习的一个子类,是机器学习的一类算法,相比传统的机器学习方法,深度学习有这几个特点:
- 对硬件要求更高。经常需要 GPU 才能快速完成任务,单纯用 CPU 执行任务,那耗时是非常的惊人;
- 对数据量要求更高。传统的机器学习一般可能只需要几百上千的数据量,但是对于深度学习的任务,至少也需要上万甚至几百万数据量,否则很容易过拟合;
- 具有更强的特征提取能力。深度学习可以从数据中学习到不同等级的特征,从低级的边缘特征,到高级的语义特征,这也是越来越多的机器学习方向都采用深度学习算法来解决问题的一个原因,性能更加强;
- 可解释性差。因为抽象层次较高,所以深度学习也经常被称为是一个黑匣子。
- 机器学习的核心是数学,是用一个数学模型,然后输入数据来调节数学模型的参数,从而让数学模型可以解决特定的某类问题。简单说就是希望训练得到一个可以解决特定问题的数学函数。
4. 为什么要使用机器学习
原因如下:
- 需要进行大量手工调整或需要拥有长串规则才能解决的问题:机器学习算法通常可以简化代码、提高性能。
- 问题复杂,传统方法难以解决:最好的机器学习方法可以找到解决方案。
- 环境有波动:机器学习算法可以适应新数据。
- 洞察复杂问题和大量数据
一些机器学习的应用例子:
- 数据挖掘
- 一些无法通过手动编程来编写的应用:如自然语言处理,计算机视觉
- 一些自助式的程序:如推荐系统
- 理解人类是如何学习的
参考
- 《深度学习》
- 深度学习 500 问--https://github.com/scutan90/DeepLearning-500-questions
- 《hands-on-ml-with-sklearn-and-tf》
- https://www.zhihu.com/question/68109802
- https://www.zhihu.com/question/358632429/answer/919562000
- https://www.zhihu.com/question/68109802/answer/263503269
欢迎关注我的公众号--AI算法笔记,查看更多的算法、论文笔记。

标签:机器,--,数据,局部,学习,概念,深度,鞍点 来源: https://www.cnblogs.com/cai-study-ai-cv/p/13907049.html