【论文笔记系列】- Understanding and Simplifying One-Shot Architecture Search
作者:互联网
search space设计
文章认为好的search space需要满足以下条件:
- search space需要足够large和expressive,这样才能探索更丰富多样的候选网络架构
- one-shot模型在验证集上的准确率必须与stand-alone模型的准确率高度相关。也就是说相比于其他候选模型,A模型在验证集上准确率高,那么对A模型retrain的之后,它在测试集上的准确率也要是最高,或者是靠前的。
- 在资源有限的情况下,one-shot模型不能太大
One-shot模型训练
- 互相适应的鲁棒性(Robustness of co-adaptation):如果只是简单地直接训练整个one-shot模型,那么模型内各部分是高度耦合的,即使移除一些不重要的部分,也可能使得模型预测准确率大打折扣。所以文章引入path dropout策略来提高训练稳定性。具体做法就是最开始啥都不drop,而后每个batch都随机drop,而且drop的概率也线性增加。drop的概率计算公式为\(r^{1/k}\),\(r\)是一个超参数,\(k\)表示操作数量。
- 训练模型的稳定性(Stabilizing Model Training.):
- 虽然Relu-BN-Conv效果也差不多,实验使用更常用的BN-Relu-Conv顺序。另外我们知道在评估阶段我们会从one-shot模型里选择一个子模型来评估,也就是说我们会剔除一些操作,但是模型里的BN操作的统计量只是基于one-shot模型计算得到的,所以在评估阶段BN的统计量每个batch都要重新计算。
- 另外在训练one-shot模型的时候,对于一个batch里的数据,我们dropout的操作都是一样的。换句话说这批数据都是在同一个子模型下训练的。文章称这种方式也会导致训练不稳定,所以他们将一个大小为1024的batch数据进一步划分成多个子batch,称作ghost batch。比如1024批数据可以划分成32个大小为32的ghost batch,然后每个ghost batch应用不同的path dropout操作(即对应不同的子模型)。
- 避免过度正则化:在训练模型时,我们经常会用L2正则化。但是在这里只是对选择的子模型做正则化。不然一些没有被选择过的操作也被正则化的话就过分了啊~~
实验结果
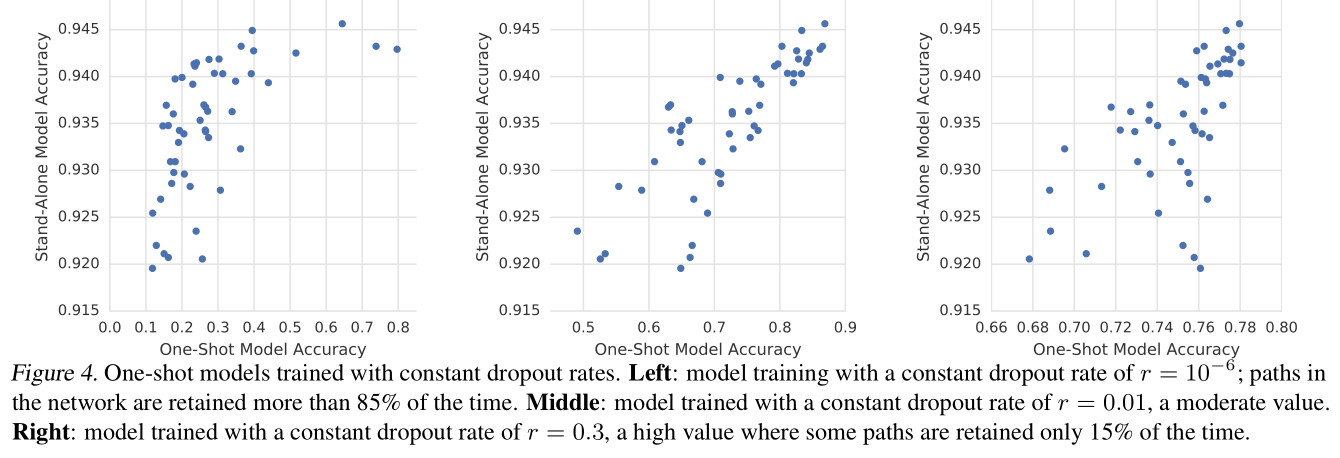
下面只介绍一个比较有意思的实验结果,即 Dropout rate对结果的影响:
结果如下图示:
- 设置的概率值太小的话(最左),可以看到one-shot模型的整体准确率都不高,但是retrain之后的stand-alone模型性能好像都还可以。但是这样one-shot的准确率并不能很好的反映最后模型的性能。
- 设置的概率值太高的话(最右),虽然one-shot模型的准确率提高了,但是可以看到准确率的范围分布在了0.6~0.8之间,也就是说概率值过大使得模型可能把更多机会给到了一些表现可能
理解one-shot模型
由上图我们可以看到(以最左图为例),one-shot模型的准确率从0.1~0.8, 而stand-alone(即retrain之后的子模型)的准确率范围却只是0.92~0.945。为什么one-shot模型之间的准确率差别会更大呢?
文章对此给出了一个猜想:one-shot模型会学习哪一个操作对模型更加有用,而且最终的准确率也是依赖于这些操作的。换句话说:
- 在移除一些不太重要的操作时,可能会使one-shot模型准确率有所降低,但是最后对stand-alone模型性能的预测影响不大。
- 而如果把一些最重要的操作移除之后,不仅对one-shot模型影响很大,对最后的
我理解是这个意思
| 状态 | one-shot 模型准确率 | stand-alone模型准确率 |
|---|---|---|
| 移除操作之前 | 80% | 92% |
| 移除不太重要的操作 | 78% | 91% |
| 移除重要的操作 | 56% | 90% |
为了验证这一猜想,文章做了如下实验:
首先将几乎保留了所有操作的(dropout概率是\(r=10^-8\))模型叫做reference architectures,注意这里用的是复数,也就是说这个reference architectures有很多种,即有的是移除了不太重要的操作后的结构,有的时移除了非常重要的操作候的结构,那么不同结构的准确率应该是不一样的。不过在没有retrain的情况下,什么操作都没有移除的one-shot模型(All on)应该是最好的(或者是表现靠前的,这里我们认为是最好的)。
注意这里的移除某些操作后得到的模型还是One-shot模型,而不是采样后的模型。采样后的模型是指从这个完整的one-shot中按照某种策略得到的模型。文中把这种模型叫做candidate architectures。
我们以分类任务为例,假设reference architectures对某个样本的预测输出是\((p_1,p_2,...,p_n)\),其中\(n\)表示类别数量;而candidate architectures的输出为\((q_1,q_2,...,q_n)\)。注意candidate architecture的输出应该是没有retrain的结果。
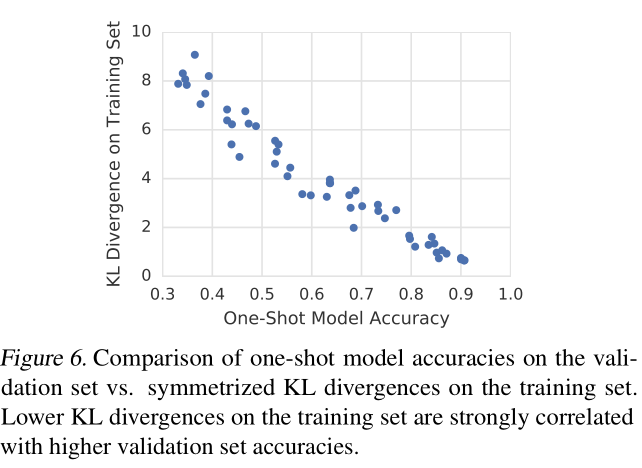
所以如果上面的猜想是正确的,那么表现最好的candidate architecture的预测应该要和所有操作都保留的one-shot模型的预测结果要十分接近。文中使用对称散度来判断相似性,散度公式为\(D_{\mathrm{KL}}(p \| q)=\sum_{i=1}^{n} p_{i} \log \frac{p_{i}}{q_{i}}\),那么对称散度就是\(D_{\mathrm{KL}}(p \| q)+D_{\mathrm{KL}}(q \| p)\)。对称散度结果是在64个随机样本上得到的平均值,散度值越接近于0,表示二者输出越相近。
最后的结果如图示,可以看到在训练集上散度值低的模型(即预测值和保留大多数操作的完整模型很接近),在验证集上的准确率也相对高一些。
原论文各种名词用的很混乱,一下是one-hot,一下是reference architecture,看得很迷幻,结合了好几个博文归纳总结的此文,有问题欢迎评论区指出。
参考:
标签:Search,shot,模型,移除,batch,Understanding,准确率,操作,Shot 来源: https://www.cnblogs.com/marsggbo/p/13195496.html