Peach原理简介与实战:以Fuzz Web API为例(转载)
作者:互联网
本文所有内容来自:
https://www.freebuf.com/sectool/219584.htm
复制此文仅为后续实战
0×0 此文目的
Fuzz即模糊测试,是一种使用大量的随机数据测试系统安全的方法,Peach就是一种这样的工具。网上零零星星有些介绍Peach的文章,也有少部分使用Peach测试某种文件的教程(其实就是直接翻译官方文档),并没有针对实际协议的真正测试。初学者,往往无从下手,本文从实战出发,穿插讲解Peach套件的一些语法和原理,让你真正从0开始一段奇妙的模糊测试之旅!
0×1 Peach简介
Peach是一个遵守MIT开源许可证的模糊测试框架,首个版本发布于2004年,使用python编写,第二版于2007年发布,被收购后,最新的第三版使用C#重写了整个框架,而且分为社区版和付费版。付费版本拥有更好的扩展功能,便于管理的Web界面,更加智能的建模机制,上手更容易。但是,鉴于广大同胞囊中羞涩,本次当然重点讲解社区版(免费版)。
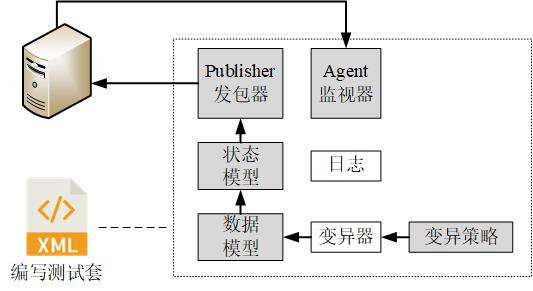
Peach Fuzz其实是一种黑盒测试方法,通过发送大量的随机数据到被测试系统,再结合监视器,检测系统的运行状态,来发现被测试系统或进程中,可能存在的安全问题。英文好的同学,可自行点击Peach官网传送门。
0×2 Peach安装
安装其实很简单,对于本次的测试来说,不需要一些花里胡哨的操作(比如,.NET,debug tools),对于Win10来说,更是如此。官方安装指南——看看就好,不必当真。
所以,只需要一步,在官网上下载peach-3.1.124-win-x86-release或者x64社区版本即可;任性的同学也可以下载Linux/Mac的版本。下载之后,解压。为了方便后续的测试,最好将peach的目录,加入到系统的环境变量。

0×3 结合Burpsuite对Web API进行fuzz测试
终于到了实战环节,这也是本文的另一个重点内容。这部分从0开始,一步步带你领略Peach的神奇魅力,更高级的功能,需要我们以后共同探索。
0×31 使用Burpsuite抓取需要fuzz的Web接口数据
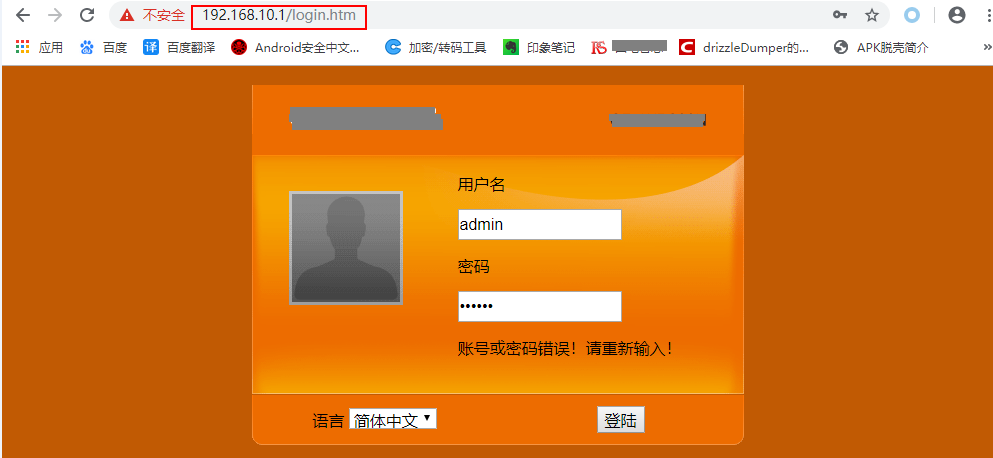
设置代理,对目标接口进行抓包,这一步我相信大伙都会,不会的同学请自行移步Burpsuite抓包教程,我在这里就不重复造轮子了。
需要fuzz的API接口
抓取数据包
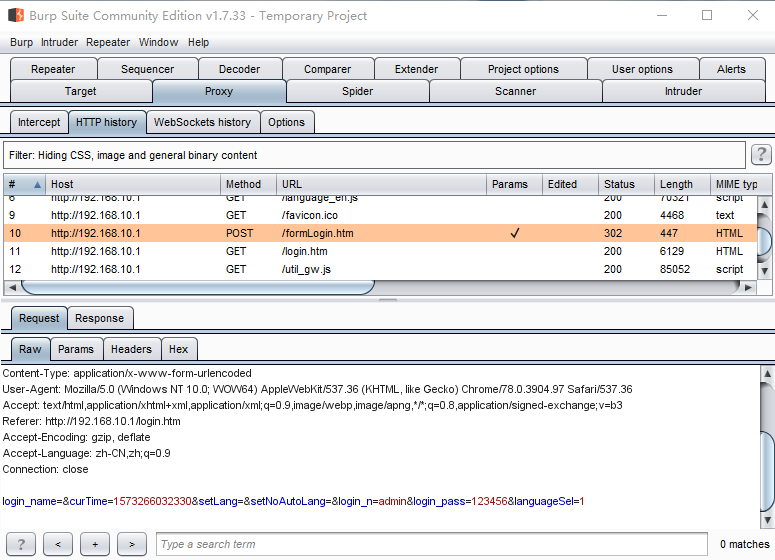
我们的目的是要将抓取的数据包,转换成数据模型,在此之前,需要先保存该数据包为.bin文件。
全选:Ctrl + A
复制:Ctrl + C
创建文件login.bin,并将数据包拷贝过来并保存:Ctrl + V

将文件保存在E:\MyPeachPit\这里只是指定一个文件夹,方便后面把所有的配置文件都放在一个目录中。你们可随意创建一个目录。
0×32 创建数据模型
创建一个文件,命名为 1-my_data.xml(命名请随意),同样放在E:\MyPeachPit\。首先是根标签,也就是描述文件,你也可以在属性中加入文件的整体注释信息。
<?xml version="1.0" encoding="utf-8"?>
<Peach xmlns="http://peachfuzzer.com/2012/Peach" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://peachfuzzer.com/2012/Peach ../peach.xsd">
<DataModel name="my_data_model">
</DataModel>
</Peach>
在<Peach>标签中,创建数据模型<DataModel>,属性name可以随便起个名字,但是后面会用到。数据模型其实就是我们需要的fuzz对象。按照上一节抓取的数据包,一步步来编写这个数据模型,这是定制化fuzz的核心步骤。
数据包的第一行:POST /formLogin.htm HTTP/1.1。请注意这里的空格,编写数据模型一定要一一对应。

第一行对应的数据模型如下

每个标签都可以起一个名字,为空也是可以的。value是实际的值,token字段用于分隔,表明这是一段用于分隔其他字符的标签。mutable,顾名思义,就是这段标签能否用来变异,也就是说,你到底想不想改变这段数据。HTTP报文头部后面几行数据以此类推,相信大家都会编写了。
温馨提示1:HTTP头部报文和请求体报文之间,存在一个空行,在数据模型的编写中,也是要注意的。
接下来是比较重要的HTTP请求体的内容,对应的数据模型了。常见的请求体主要有两种:XML和JSON。比如说,如果请求体是这样
{"key1":"admin", "key2":"pw123"}
那么对应的数据模型应该是

这里有几点注意下:双引号的转移字符是 " 剩下的内容以此内推。同样的,标签可以起名字,也可以为空,但是不能全为 name=“”但是像上图那样会有问题,会提示键重复。请删除 name=“”。
温馨提示2:普通字符和特殊字符最好分开写,不然很容易出错。比如
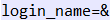
最好编写成

温馨提示3:编写数据模型文件很容易出错,最好写一段就配合0×33节的步骤,对数据模型文件进行校验。
0×33 验证数据模型与抓取的数据包bin文件
数据模型文件编写的过程本身就是一项比较繁琐的工作,编写好的文件,也极有可能出错,PeachValidator.exe 应运而生。在编写好数据模型之后,我们需要使用Peach解压后,自带的该工具,验证编写好的数据模型,与抓取的数据包bin文件内容是否一致。
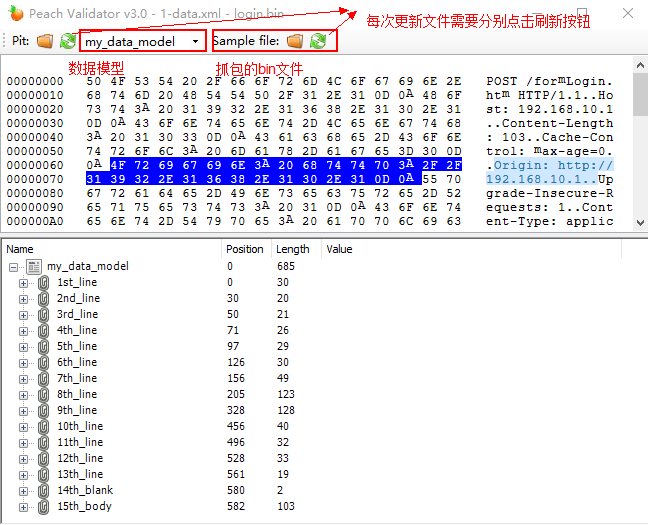
如上图所示,点击完刷新按钮之后,如果没有报错,说明数据模型文件编写正确,否则,需要根据错误提示,进行修改。

本节所示的两幅图,即PeachValidator.exe 与 notepad++ 配合工作,使得调试数据模型较为方便。
经历过数据模型的定制后,有没有觉得很麻烦?没办法,Peach后期的自动化依赖于前期的定制,所以数据模型的编写正确与否,至关重要。根据不同的API,数据模型一旦编写好之后,后续的步骤大同小异,可以套用。
0×34 创建配置模型
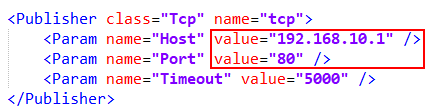
配置模型,顾名思义,是一些全局的配置信息,例如IP地址、端口之类的。你定义好了数据包,总得定义发送目标把。文件命名为2-my.xml.config(命名依然请随意)。
<?xml version="1.0" encoding="utf-8"?>
<PitDefines>
<All>
<IPv4 key="TargetAddress"
value="192.168.10.1" />
<Range key="TargetPort"
value="80"
min="0"
max="65535" />
<Range key="Timeout"
value="5000"
min="0"
max="999999" />
<!--
还可以定义一些配置信息,具体可参考官方手册
!-->
</All>
</PitDefines>
</Peach>
0×35 创建状态模型
状态文件,主要包括input和output两个动作。编写状态模型文件如下,并命名为3-my_state.xml

input:从Publisher即发包器中接收或者读取输入
output:通过Publisher发送或写output操作
未知数据保持在一个“Blob”元素(二进制大对象或者字节数组)中
0×36 创建综合测试模型
综合测试模型文件,定义了一些关键要素,例如发包器、监控器以及测试策略等。相当于把所有文件综合成一个文件。实际上,针对一些简单的API,也可以把所有文件直接写在一个文件中。
Publishers是Peach的I/O连接,它是实现输出、输入和调用等操作之间的管道。对于文件fuzzer来说,将使用一个称之为文件的Publisher,它允许我们对一个文件进行写操作。编写综合测试模型文件如下,命名为4-my_integrate.xml
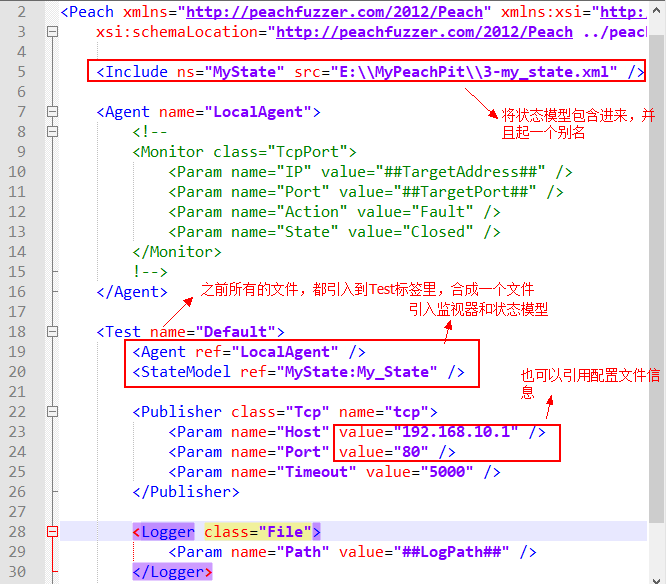
Test元素被用于配置一个指定的fuzzing测试,这个配置通过一个Publisher和其他选项(比如including/excluding等被变异的元素、Agents、fuzzing策略)组合成一个StateModel。多个test元素是支持的,在Peach命令行使用中,只需简单提供test元素的名字即可。
至此,所有的xml文件编写告一段落,那么怎么测试这些xml文件是否编写正确呢?请看下节。
0×37 验证测试套
输入以下命令,即可验证编写的所有文件是否符合Peach的标准。请注意参数 -1 是数字1,而不是字母l。
peach E:\MyPeachPit\4-my_integrate.xml -l --debug
第一次运行时,肯定会报错,需要根据错误提示,不断修正我们刚刚编写的测试套xml文件。
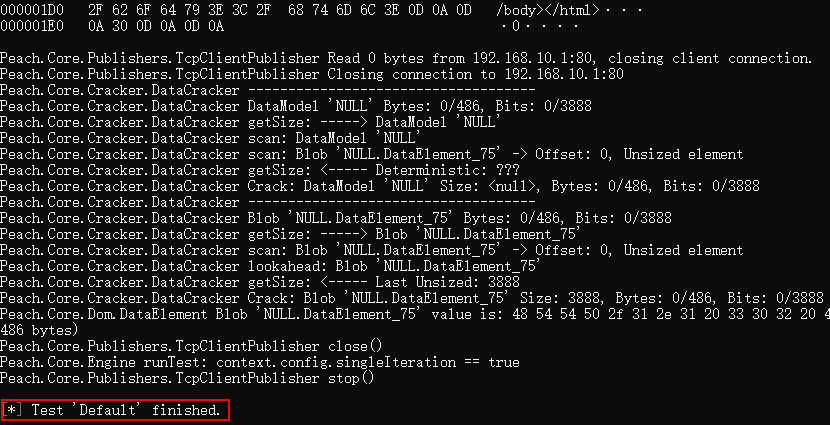
如果打印出上面的信息,那么恭喜你,终于完成了测试套的编写!也就是完成了Peach的数据建模,基本上,你已经完成了99%的前期准备工作!
0×38 结合Burp进行正式测试与结果分析
为了实时监控数据流的变化状况,我们需要监控Peach发送给测试目标的数据。Burpsuite给我们提供了一个便捷的“监控器”。
第一步绑定代理
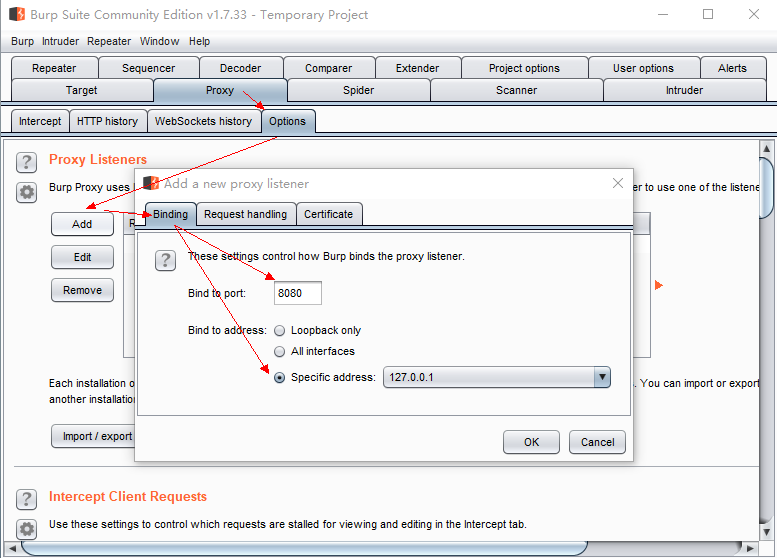
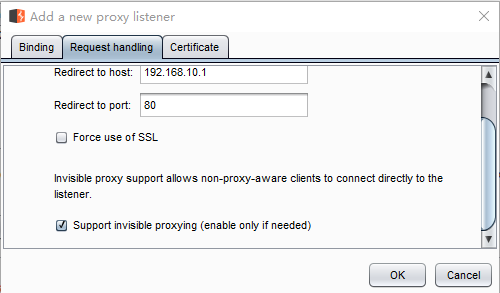
请注意,上述的 127.0.0.1:8080,与编写的测试套 4-my_integrate.xml 中的信息要一致。所以,需要将下面的红框中的数据,也改为127.0.0.1:8080
第二步peach发送的流量重定向到webserver
终于到了最后一步,也就是愉快的fuzz啦!
peach E:\MyPeachPit\4-my_integrate.xml –range 1,150000
–range 指变异的报文数量,官方推荐15W。

等fuzz完之后,筛选一下Burpsuite抓到的所有报文,就可以看到哪些畸形报文,对目标产生了影响。
0×4 总结
Peach最繁重的工作,都在协议的建模上,也就是编写测试套件,中途可能会出现很多错误,需要耐心排查。关于一些更高级的用法,读者可自行查阅官方手册(中文翻译版)。本文中用到的所有代码,都是笔者亲自编写,并且进行了验证。祝大家都能用行之有效的方法,挖意想不到的大洞!
标签:xml,Web,Peach,文件,为例,测试,编写,数据模型 来源: https://www.cnblogs.com/botoo/p/12201131.html