Incremental Learning Techniques for Semantic Segmentation 论文阅读笔记
作者:互联网
Incremental Learning Techniques for Semantic Segmentation 论文阅读笔记
摘要
当需要增量学习新任务时,由于灾难性的遗忘,深度学习架构表现出严重的性能下降。 之前增量学习框架专注于图像分类和对象检测,本文正式提出了语义分割的增量学习任务。作者设计了方法提取先前模型的知识以保留有关先前学习的类的信息,同时更新当前模型以学习新的模型。 与最近的一些框架相反,本文方法不存储来自先前学习的类的任何图像,并且只需要最后一个模型来保持这些类的高精度。
方法
在输出层进行蒸馏
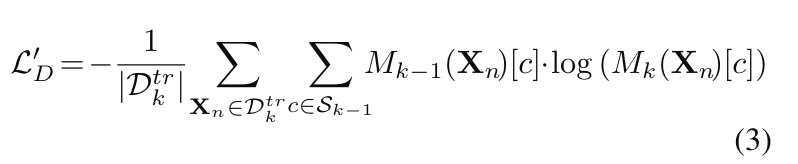
仅使用该损失函数的模型作为baseline,一个改进是针对模型的Encoder:
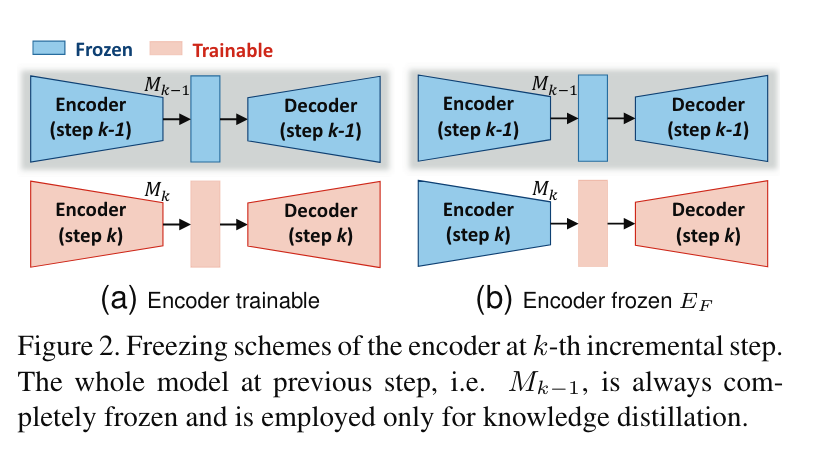
即训练时冻结Encoder,只训练Decoder以保持在之前steps中学习到的特征提取能力。上一个step的模型参数也进行冻结,仅用于知识蒸馏。(这里有一个疑问是如果当前这一步一直冻结Encoder,那么Encoder在什么时候训练当前这一步的提取能力呢?等有时间看看代码!)
在中间特征空间进行蒸馏
作者指出在中间特征空间进行蒸馏时不应用交叉熵损失而是应该用L2损失,这是因为这些层并非分类层而仅仅是中间的阶段,参数应该紧靠上一个step的参数。蒸馏项计算如下:
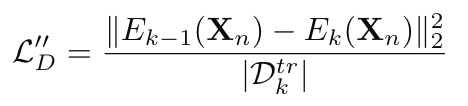
模型\(M_k\)可以被解耦为编码器\(E_k\)和解码器,上式中是用编码器的输出计算蒸馏损失。其中\(D_k^{tr}\)是第k步的数据集。
标签:冻结,Segmentation,Semantic,蒸馏,模型,损失,Encoder,学习,Incremental 来源: https://www.cnblogs.com/lipoicyclic/p/16670772.html