袋鼠云产品功能更新报告01期丨用诚心倾听您的需求
作者:互联网
作为一家以“客户第一”为价值观的公司,袋鼠云一直以来关注客户体验,专注提升产品品质,不断收集客户反馈,持续增加新功能并不断优化旧功能,为用户输出最佳产品使用体验。2022年上半年,我们新增了许多重要功能,并进行了若干细节更新,然后整理了这份产品优化报告,在此与您分享,欢迎您提出宝贵建议。
那么究竟具体迭代优化了哪些内容呢?下面就给大家一一进行介绍。
数栈DTinsight
1、数据安全集成Ranger、LDAP
用户痛点:在老版本的数栈中,数据安全的管理方式是比较弱的,虽然我们也做了表权限的管理、在资产中也有数据分级分类的功能,但存在以下几个硬伤:
· 权限与底层不打通
· 授权方式粗放、简单
· 权限不能全平台生效
新增功能说明:综合上述用户痛点,需要集成标准权限控制技术,实现一体化、全域的数据权限控制。
Hadoop体系内,我们通过Ranger来实现数据权限的集中控制,包括了绝大多数的Hadoop组件。并且Ranger本身可支持更丰富的权限控制,比如HBase等。
在数栈的标准的数据安全方案中:
· 用户可通过LDAP认证,访问各类jdbc类应用,比如Hive、Spark、Trino等。
· 若用户需要直连HDFS访问数据(比如通过Python或shell),或访问Kafka,则只能通过Kerberos证书来访问。
(新增功能示意图)

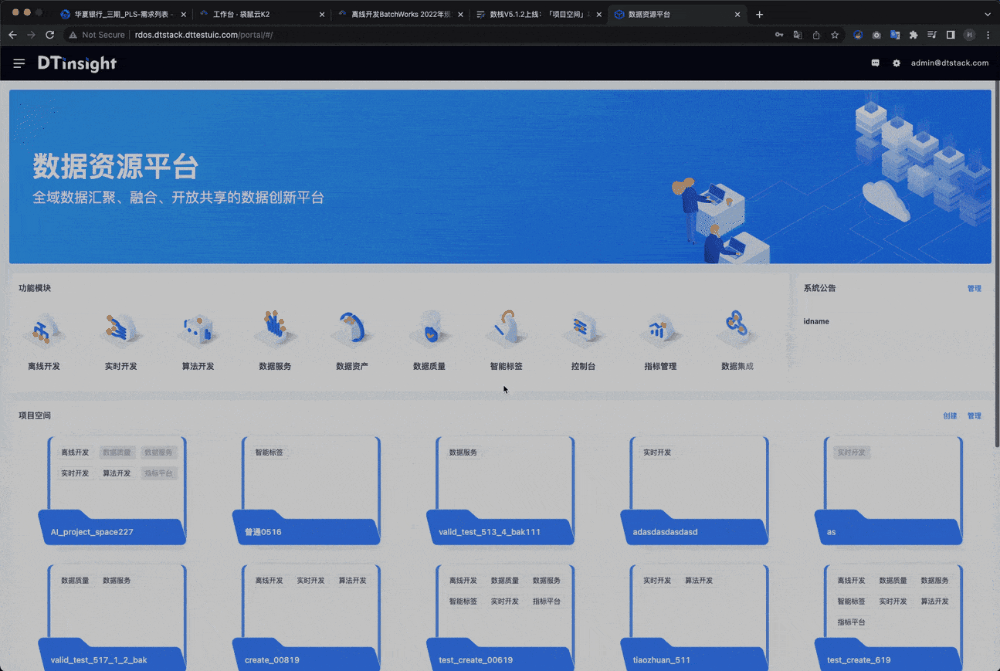
2、项目空间
用户痛点:数栈之前是采用「租户-项目」的模式来管理的,而且各产品之间是没有关系的,比如同样在「A」租户内,离线可以有a、b、c等项目,实时可以有d、e、f等项目,而这些项目之间是毫无关系的。
新增功能说明:「项目空间」,是为了将各产品的项目打通而设计的。也就是说,离线开发的a项目可以和实时开发的d项目组合,形成一个「项目空间」。打通之后带来如下便利:
· 解决子产品之间的零散、割裂感的问题,体验上,产品的整体感更强。
· 效率提升,减短在子产品之间切换、跳转的交互路径,提升工作效率。
项目空间提供了新的产品-项目管理方式,不是替代,而是同时存在这2种管理方式。
(新增功能示意图)
以下内容为各子产品新增功能及体验优化项
离线开发平台
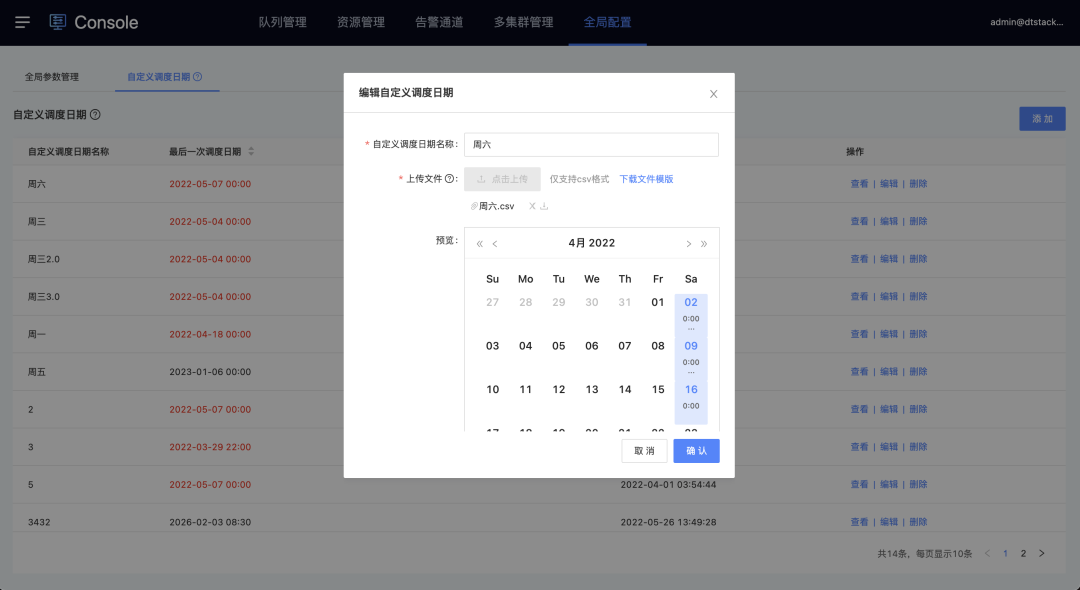
1.自定义调度日历
新增功能说明
除系统固定的天、周、月、小时、分钟及cron表达式外新增数栈全局自定义调度日期配置(以适配客户的节假日、交易日等无规律周期的特殊调度时间要求)。
用户可在控制台通过上传日期格式的csv文件进行调度周期创建,保存后可在全局离线开发任务中使用。
(新增功能示意图)
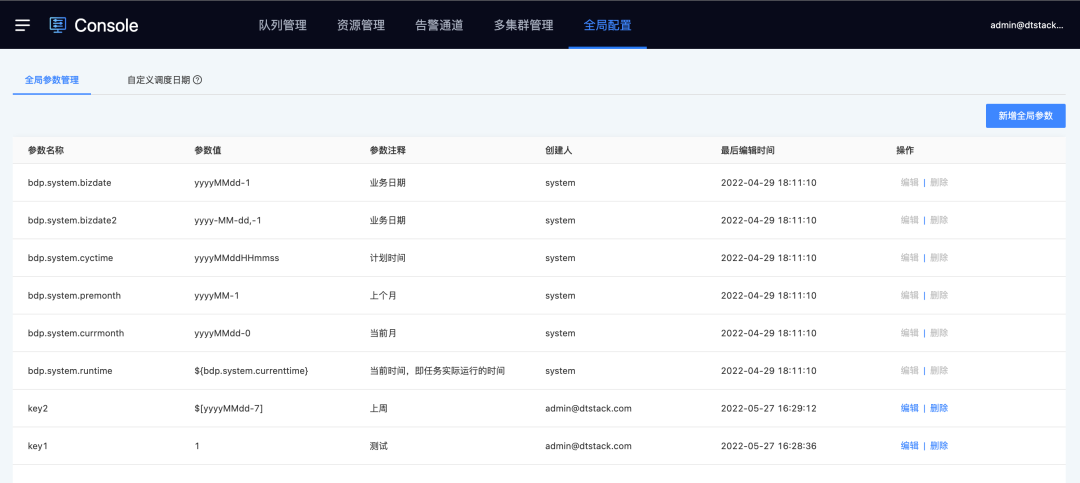
2.自定义全局参数
新增功能说明
全局参数管理支持定义,支持在控制台配置全局属性的参数,可以被所有租户下的项目引用,系统参数也作为默认的全局参数维护在控制台中。
(新增功能示意图)
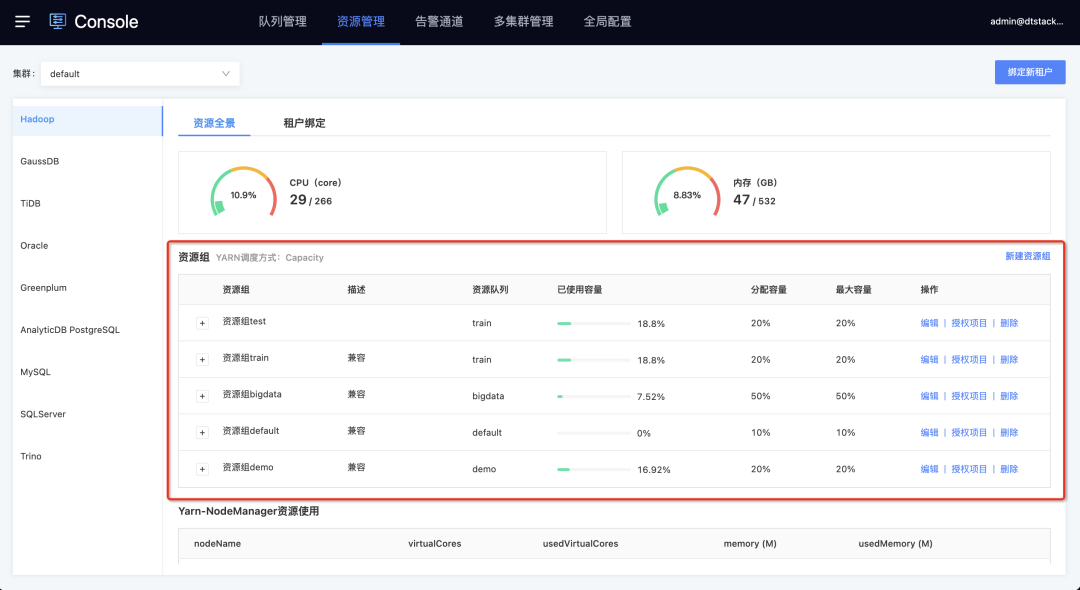
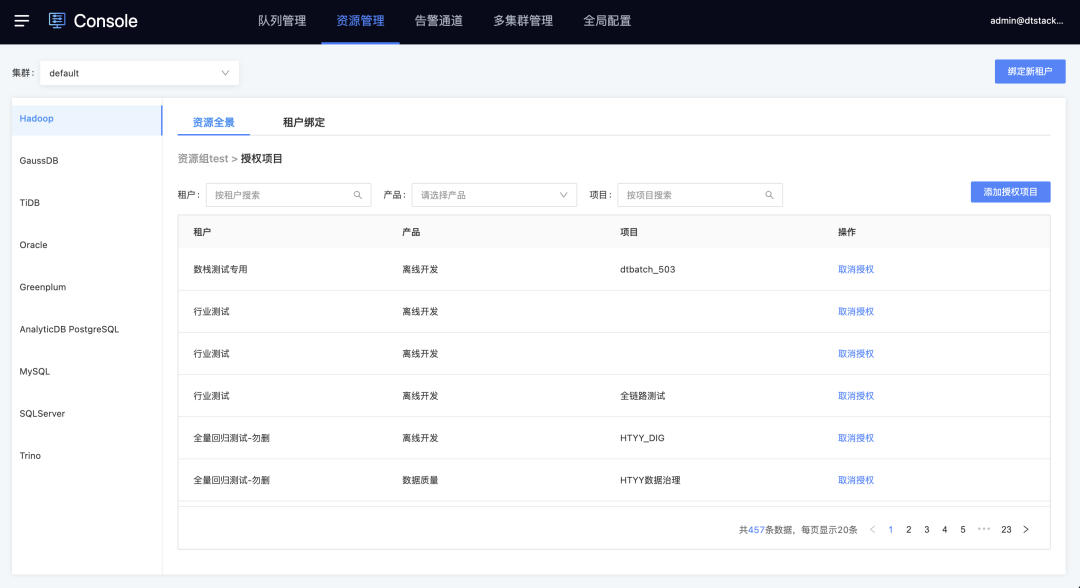
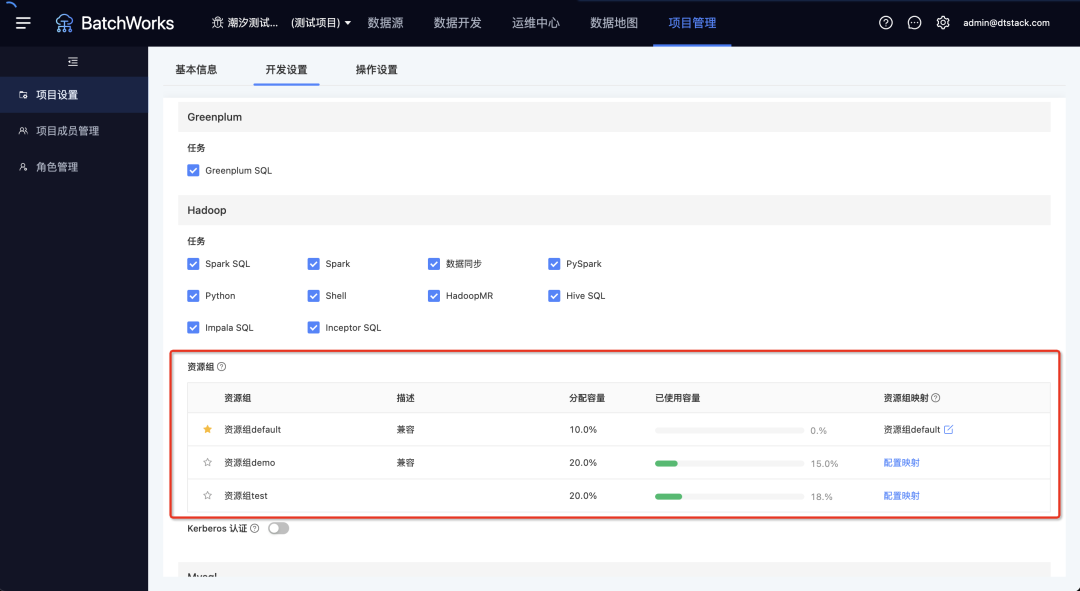
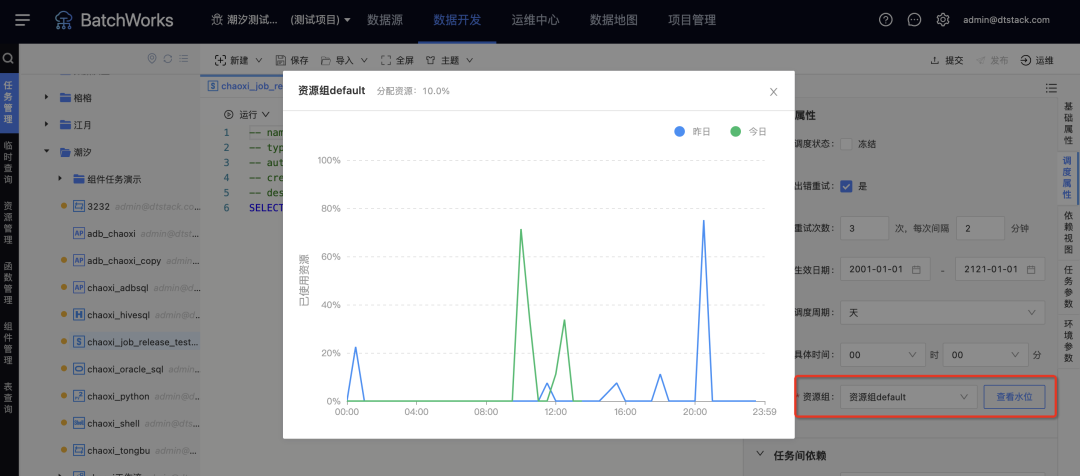
3.资源组
新增功能说明
一个hadoop资源组对应YARN上的一个队列,不同租户/项目/任务使用不同的资源组可实现资源隔离。
适用场景:不同的任务需要分配到不同的资源组运行,例如高优先级任务走高优先级资源组,低优先级的走另外的资源组,保障任务运行。
(新增功能示意图)
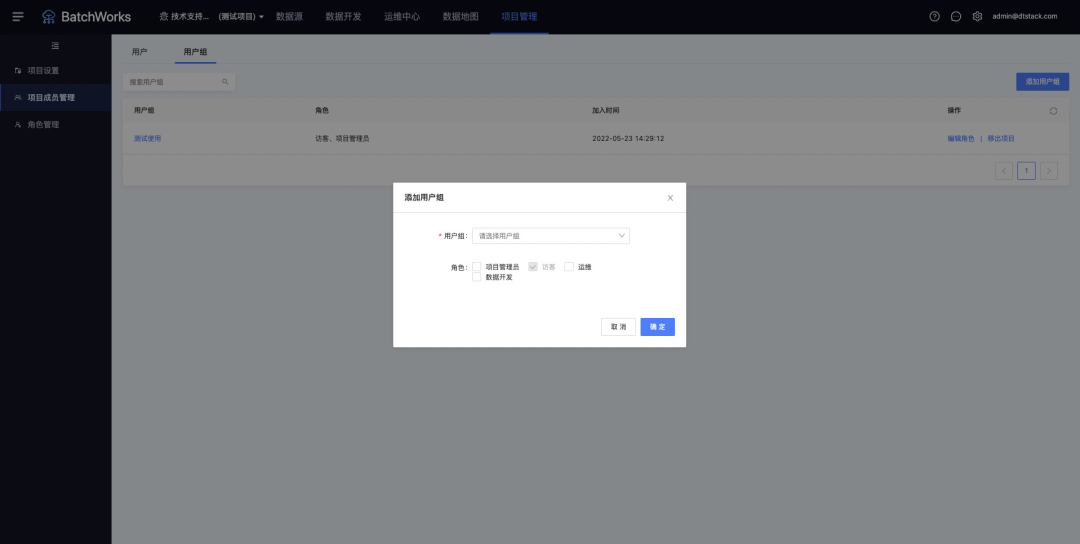
4.用户组角色授权
新增功能说明
支持对接UIC的用户组,并对用户组进行角色授权 。
在「项目管理->项目成员管理->用户组」中,可添加UIC中设定的用户组,并对用户组赋予角色权限,后续在uic中对用户组增加成员时,该成员将被自动添加至用户组所在项目中并自动赋予相应角色。
(新增功能示意图)
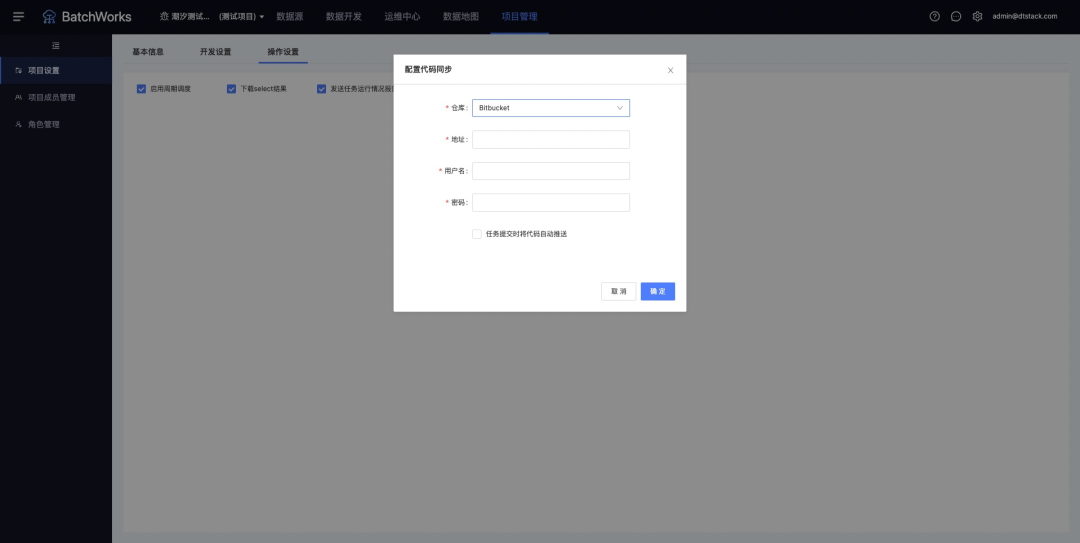
5.对接Bitbucket进行代码备份和同步
新增功能说明
在「项目管理->项目设置->操作设置」中,可配置代码仓库地址和用户,在数据开发IDE中进行开发时,可进行代码拉取和推送。
(新增功能示意图)
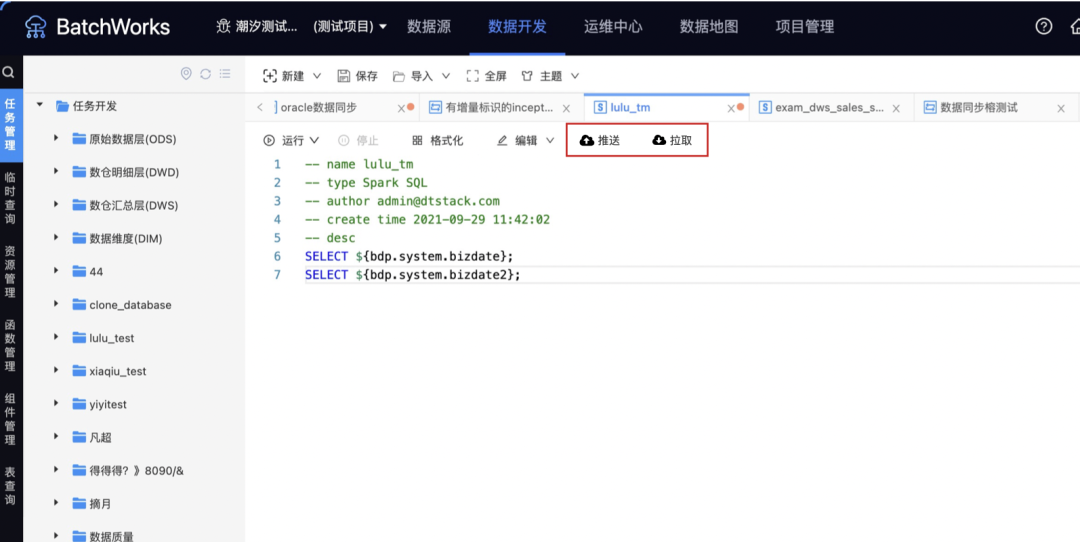
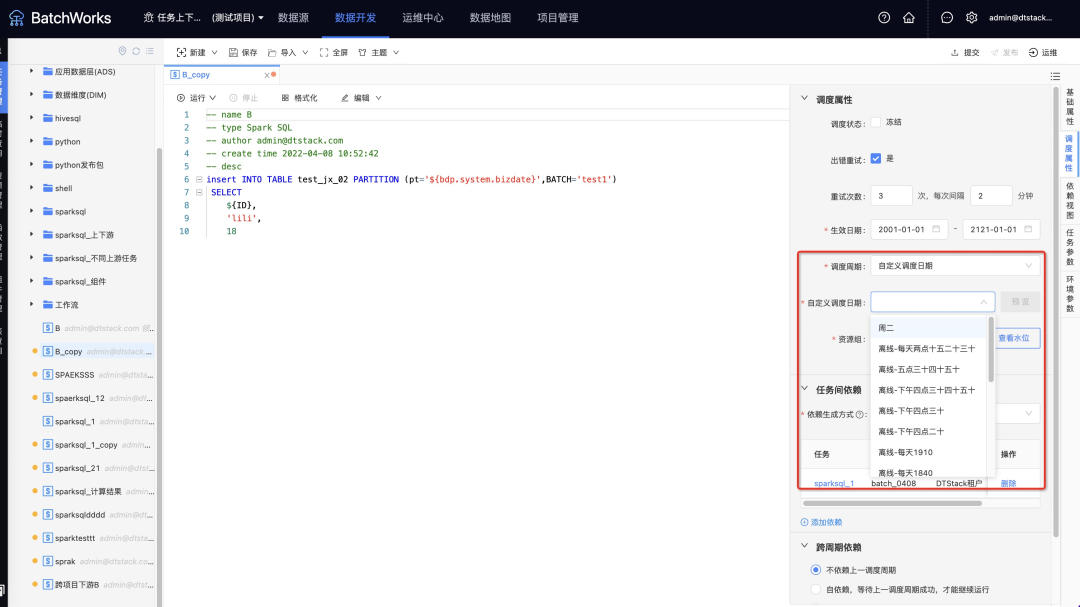
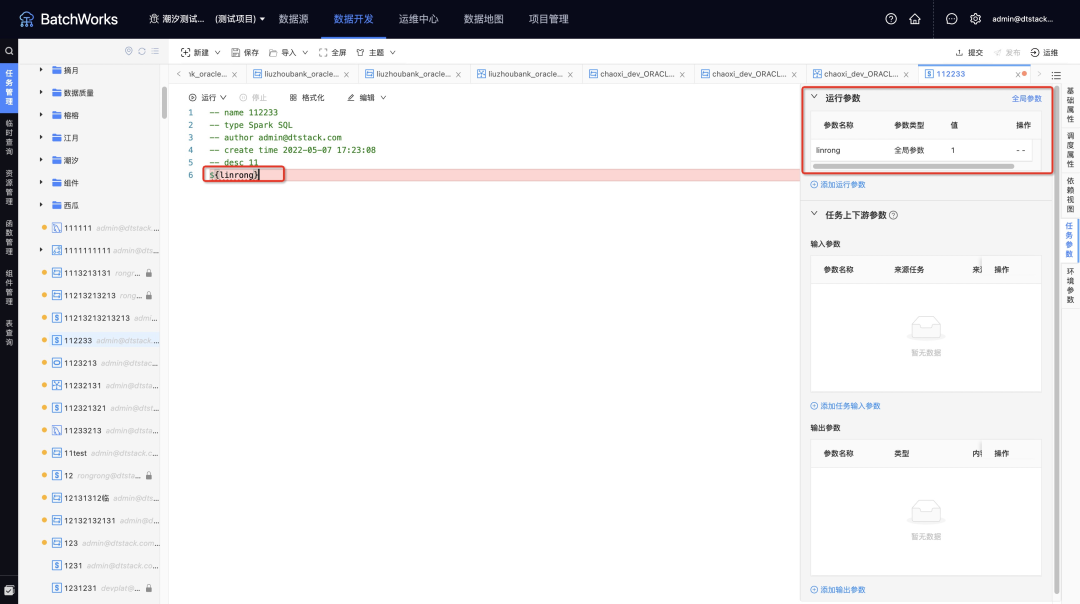
6.任务上下游参数传递
新增功能说明
· 上下游参数支持任务类型有sparksql、hivesql、shell、python(暂不支持工作流及其上述类型的子节点),其中通过资源包引用创建的python任务不支持设置输出参数(输出参数隐藏),支持输入参数;
· 原系统参数和自定义参数进行合并展示,展示在运行参数下;
· 上下游参数支持的参数类型有常量、自定义运行参数、上游参数的计算结果。
(新增功能示意图)
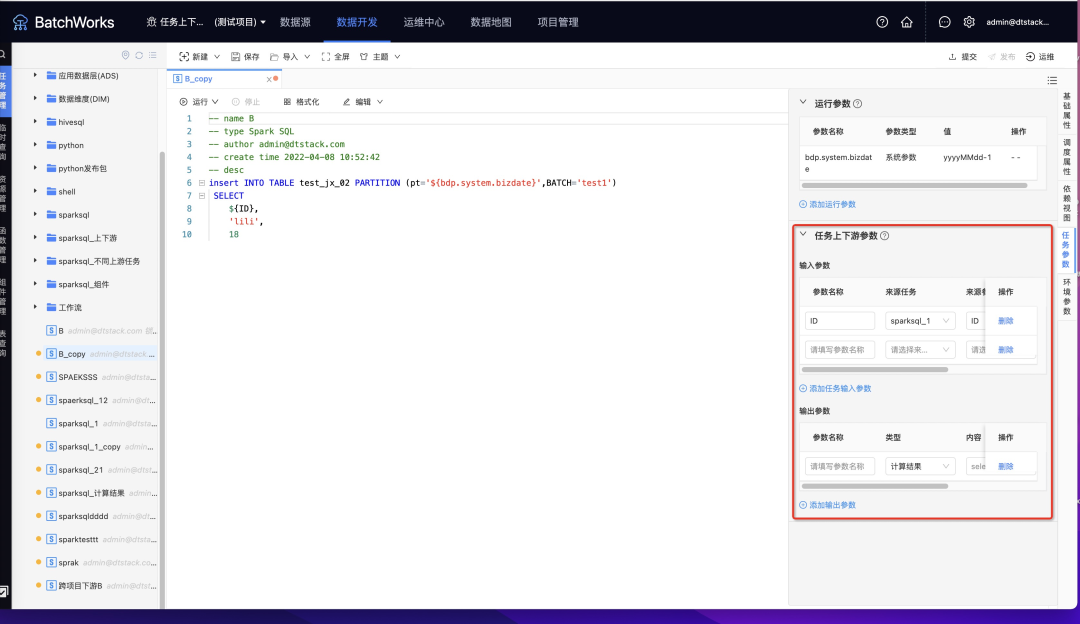
7.项目级Kerberos认证
新增功能说明
可在项目级上传kerberos证书并选择影响任务,选中任务在提交时将使用此证书提交。
(新增功能示意图)
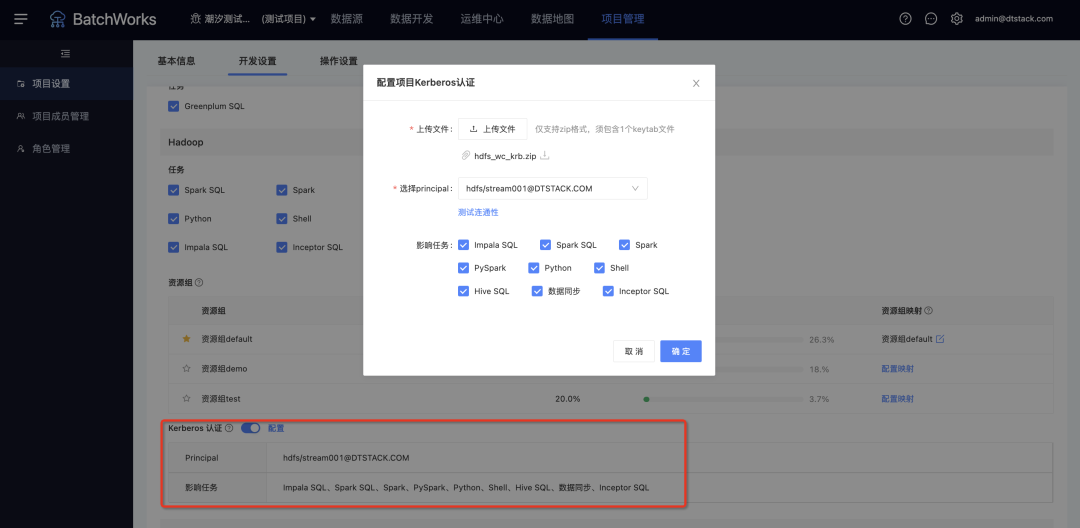
8.搜索优化
新增功能说明
支持普通搜索(原搜索方式)和高级搜索(支持按名称、描述、类型、代码内容和负责人搜索任务、临时查询、资源、函数和组件)。
(新增功能示意图)
9.调度自动同步信息
体验优化说明
支持mysql、oracle、sqlserver、hive数据源连接信息变更后(数据源链接、数据源用户、认证信息等),调度将会自动同步,任务运行时会获取新的数据源信息。
10.任务提交时的备注格式可在配置文件中设置
体验优化说明
如果客户需要自定义提交备注格式,比方需要新增业务变更、提交时间,需要在离线配置文件application.properties中增加参数
task.submit.template=[{"code":"defaultCode","remark":"备注","required":true},{"code":"code1","remark":"业务变更","required":true},{"code":"code2","remark":"提交时间","required":false}]
(优化后示意图)
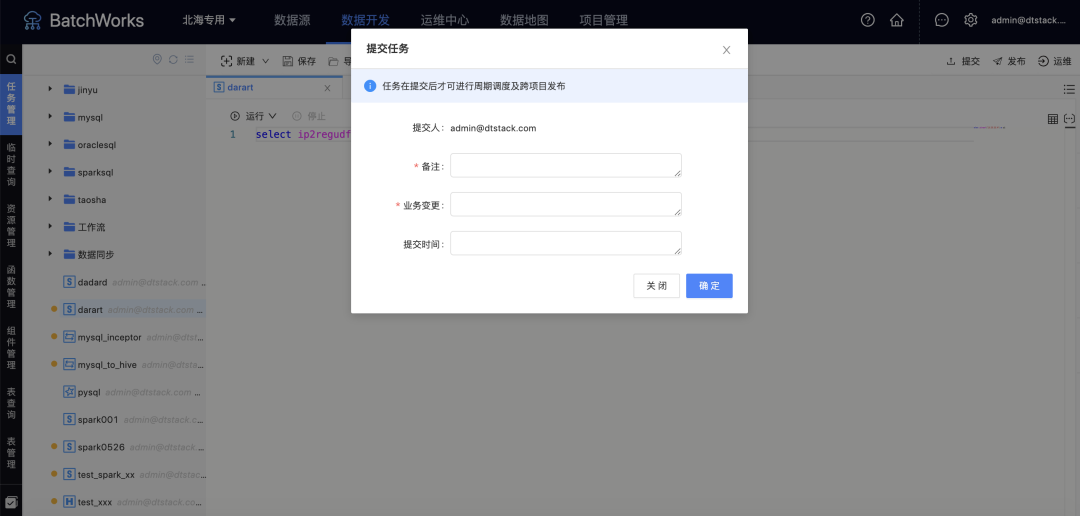
11.开发
体验优化说明
· 数据开发页面表查询菜单支持查看当前项目默认schema所在集群下的所有Hive、TiDB、ADB表
· 文件目录的字符数限制由20放宽为64
12.数据同步
体验优化说明
· hive、mysql、DMDB、DB2数据源的数据同步时可以选择schema
· 写redis支持hash数据结构
· 字段映射支持对已映射的字段进行排序整理
13.其他优化项
体验优化说明
· hive3cdp支持元数据同步
· 数据文件治理规则中的文件数最小值限制由100调整为10
· 杀任务、冻结任务,任务管理、周期实例、补数据实例的批量操作增加二次确认
· 数据源连接信息变更后自动同步至调度,任务运行时会获取新的数据源信息,现已支持mysql、oracle、sqlserver、hive数据源,后续会支持剩余数据源
· 任务提交时的备注格式可在配置文件中设置:任务提交时的内容是必填的,可以增加几个文本框字段
数据资产平台
1.数据中台全域资产汇聚
新增功能说明
· 在原先的库、表、字段基础上,新增了【离线任务】、【实时任务】、【数据API】、【数据标签】的元数据查询。此类元数据不需要用户做连接采集的管理,数据资产会自动实时采集同租户下的其他子产品中所有项目内的元数据信息。
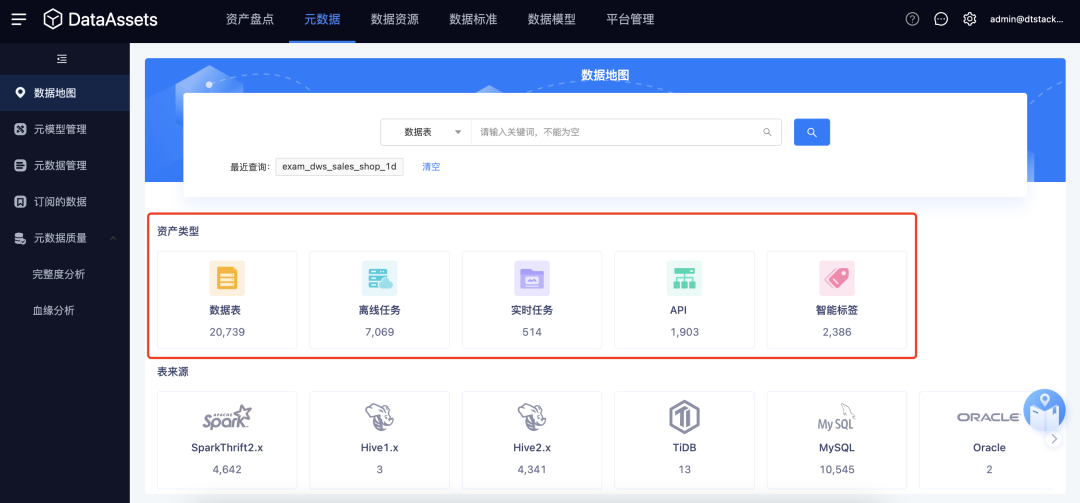
· 支持对某一类资产的搜索
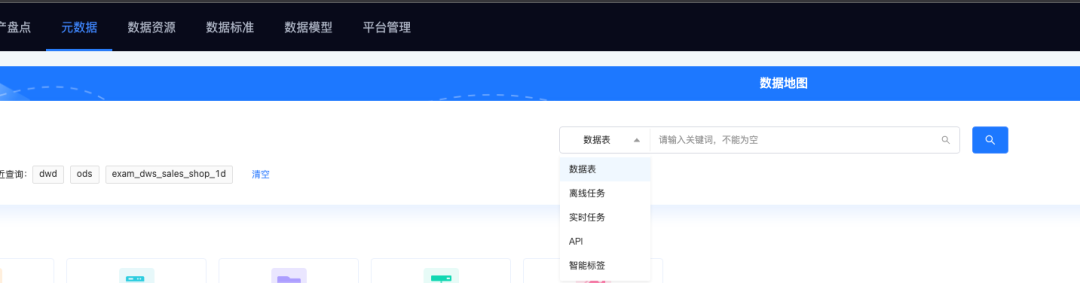
· 如「数据API」资产的详情、「离线/实时任务」资产的详情、「智能标签」资产的详情
(新增功能示意图)
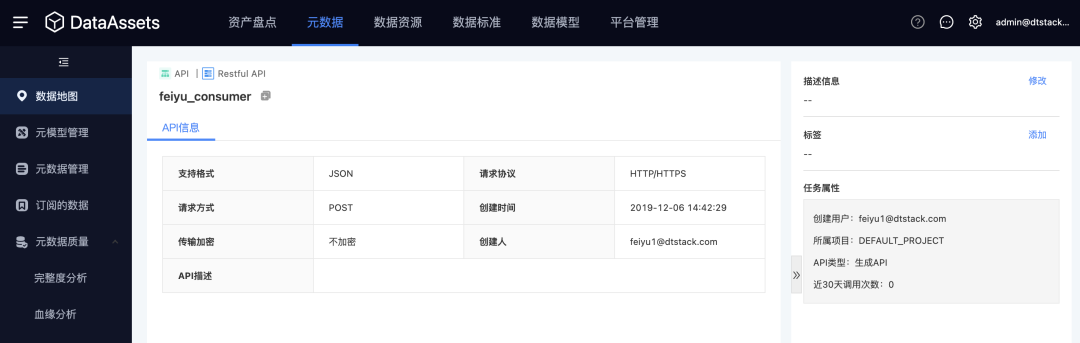
2.资产打标
新增功能说明
支持对任意资产维护自定义标签,并通过标签进行过滤查询。
(新增功能示意图)
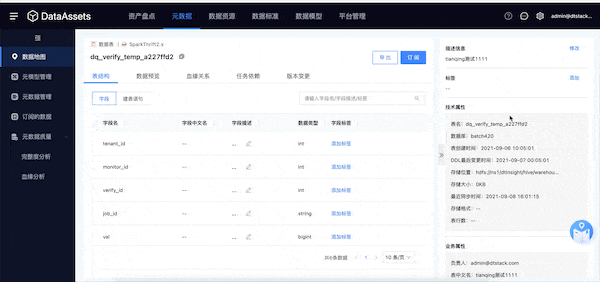
3.血缘解析能力增强
新增功能说明
在原有血缘解析的基础上,新增了【任务节点】,帮助用户更完整的理解数据流转路径。
(新增功能示意图)
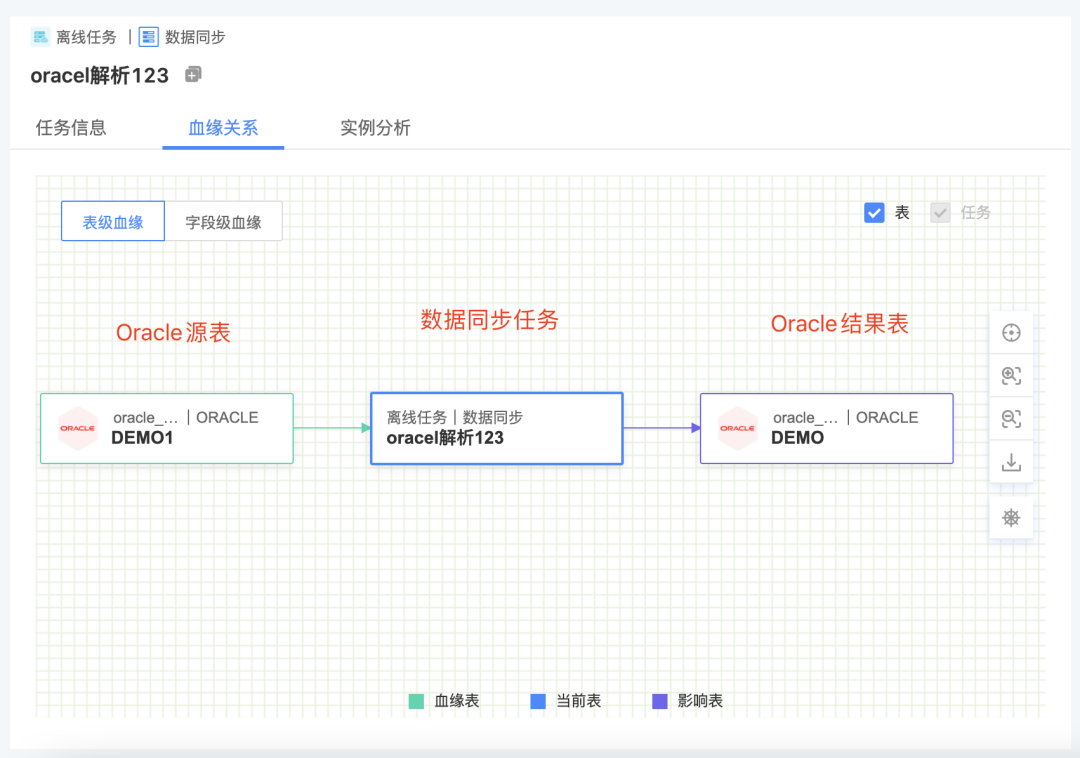
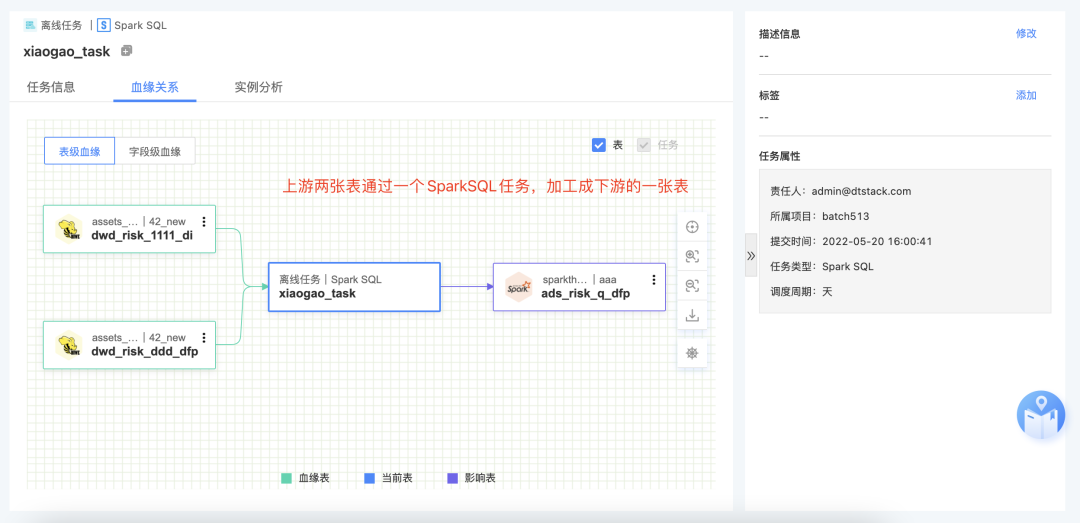
4.其他新增功能
新增功能说明
· 数据模型支持标准化检测、发布审核:用户新增、编辑数据模型时,将会自动提交管理员审批,审批通过后实际执行
· 数据同步任务血缘解析:支持对基于FlinkX的离线数据同步任务的血缘(不支持实时采集任务的血缘解析)
· 增加Impala元数据采集
· 支持按照用户组授予角色
· 关键操作日志安全审计功能
· 支持对SparkThift、Hive2.x、Inceptor、Doris、MySQL、Oracle、SQLServer、TiDB表行数的统计。Hive表的表行数是通过执行Hive analyze实现,需注意此功能对性能的影响
实时开发平台
1.支持PyFlink
新增功能说明
为了拓展流任务的灵活性,实时开发平台集成了PyFlink,新增了PyFlink的任务类型。
PyFlink是什么,简单点说就是Flink+Python,或者说是Flink on Python。两者的结合意味着您可以在Python中使用Flink的所有功能,并且将Python广泛的生态系统的计算功能运用在Flink框架上,以提高解决数据问题的能力。
2.统一建表
新增功能说明
实时现有的FlinkSQL开发流程是:创建任务-创建Flink表-编辑SQL逻辑-任务提交。比如同一个Kafka数据源,在不同的任务中引用,需要多次创建Flink表,并且不可复用。
「统一建表」,是为了将建表信息维护进持久储存,减少重复的建表动作、并进行统一的管理而设计的。也就是说,一个数据源只需要一次建表动作,在任务中可以重复引用,便于元数据管理和后续表的权限管理等。
统一建表,引用了Catalog 管理,是提供了一种新的表创建、管理方式,原来的表逻辑依然保留,并且可以在一个任务中同时使用。同时存在这2种方式。
3.Batch模式
新增功能说明
· 实时平台为了实现批流一体,结合flink 的特性进行调整,针对FlinkSQL任务添加了对batch模式的支持。
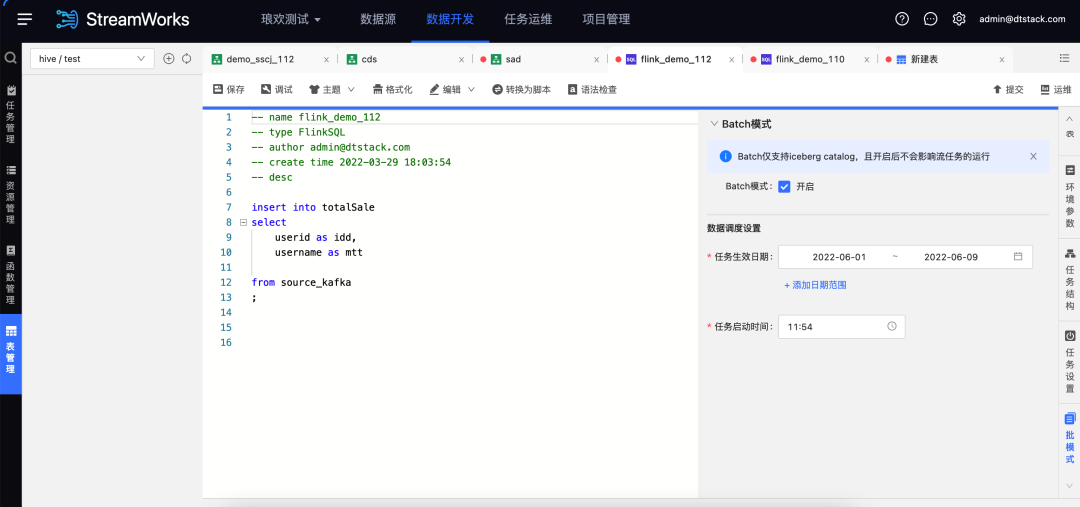
· 在任务运维的「批任务记录」里,可以查看批任务的历史运行情况、查看日志、下载日志等。
(新增功能示意图)
4.Flink1.12
新增功能说明
· Flink CDC支持数据还原
· FlinkSQL维表、结果表支持Impala
· 支持自定义Kafka Format格式,当前支持csv、json、avro三种格式,可自定义扩展新的格式,例如protobuf
5.其他新增功能
新增功能说明
· 消息管理平台和实时的合并:实时将与Kafka消息管理平台共同输出,未来也可以输出Kafka,需注意权限情况,只有租户管理员/租户所有者才具备Kafka集群管理的权限,其他角色只有查看权限
· 支持MessageQueue作为数据源「sow」
· 维表结果表支持Doris
· 开发界面,增加SQL结构展示
· 支持每个任务指定资源队列提交
6.产品优化项
体验优化说明
· 支持将oracle维表作为选择视图
· flinksql中使用sasl/scream认证放是的kafka作为源表报错
· 开启出错重试时,可以选择任务重跑还是续跑
· 语法检查报错信息中含明文密码
· Flink1.12实时采集的参数模版中增加参数
· 任务调试:调试数据管理/引用,可以复用Flink用来调试的数据;
· 开启出错重试时,可以选择出错重试时,是重跑还是续跑;
· 资源管理:资源详情上显示资源绝对路径
数据服务平台
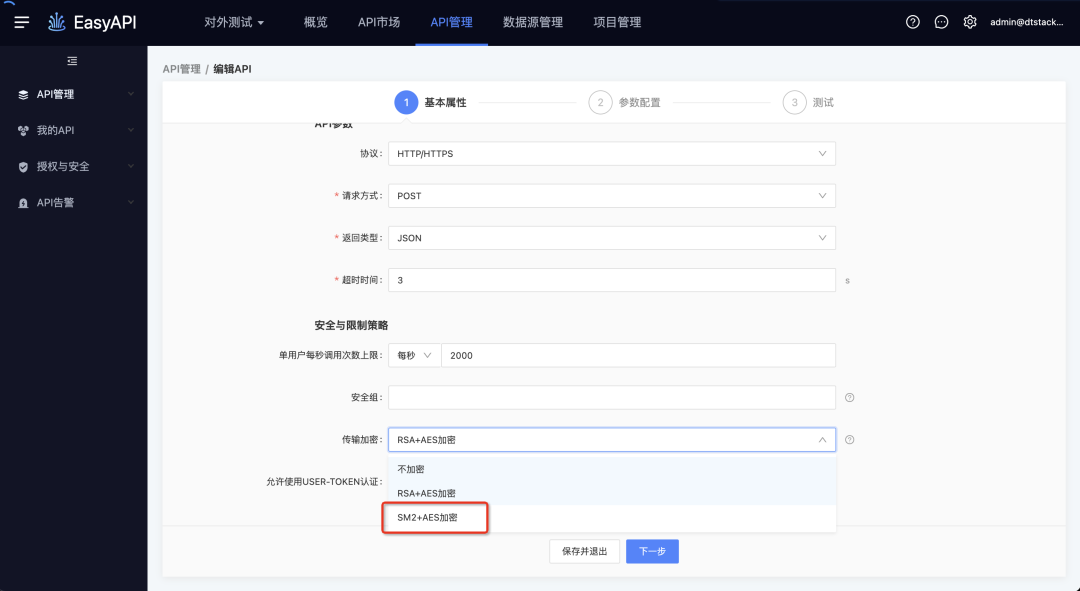
1.API传输,支持国密sm2加密
新增功能说明
(新增功能示意图)
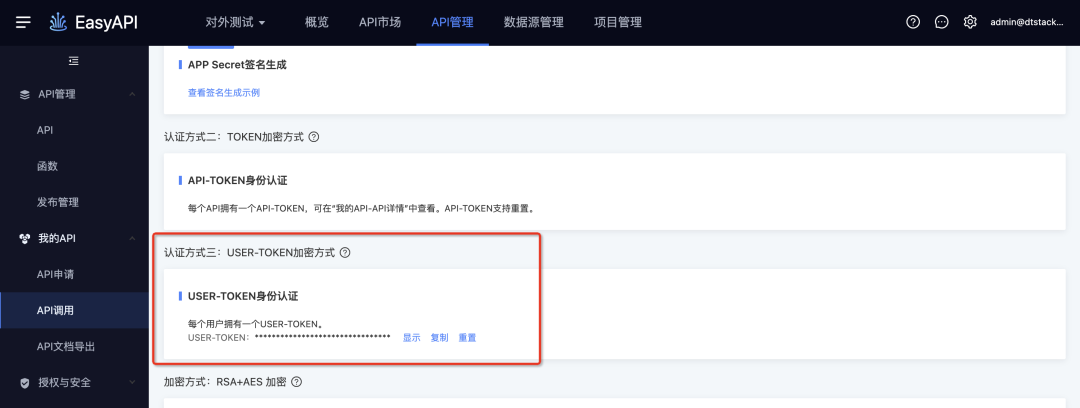
2.调用不同API使用同一认证信息
新增功能说明
同一用户调用不同API使用同一认证信息,不用每个API一个token。比如客户有个业务系统,营销系统,则营销系统需要20个API,可以使用同一个token。
(新增功能示意图)
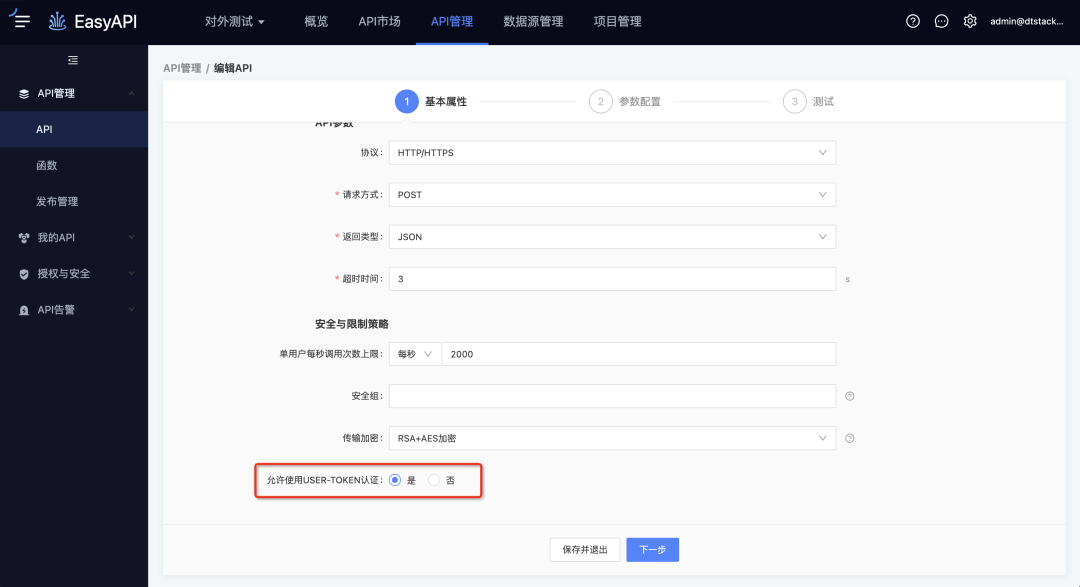
3.API版本管理
新增功能说明
(新增功能示意图)

4.其他新增功能
新增功能说明
· 模版向导模式生成sql增加排序功能
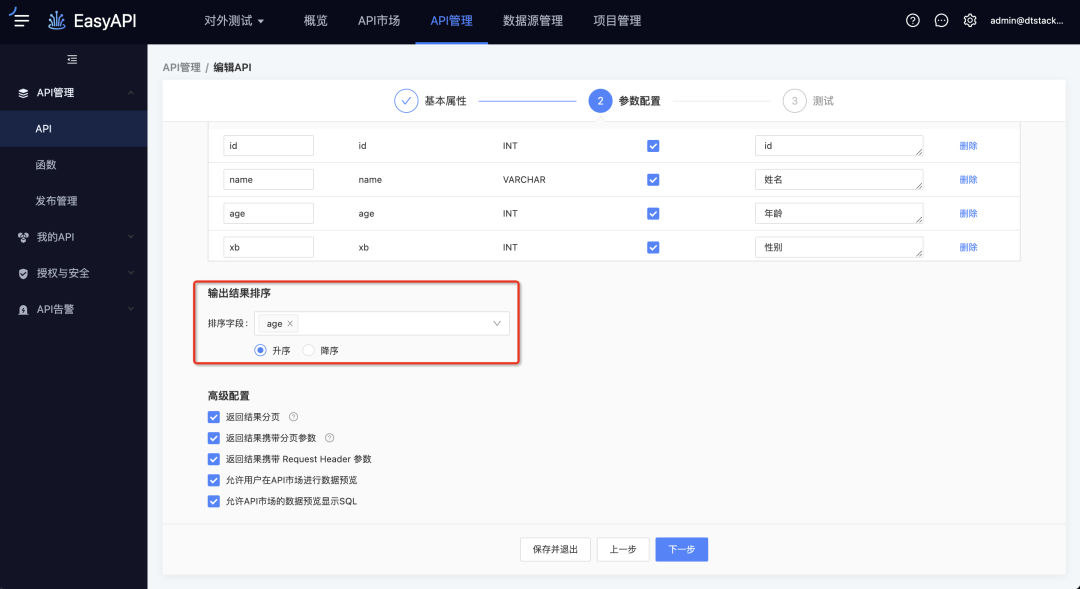
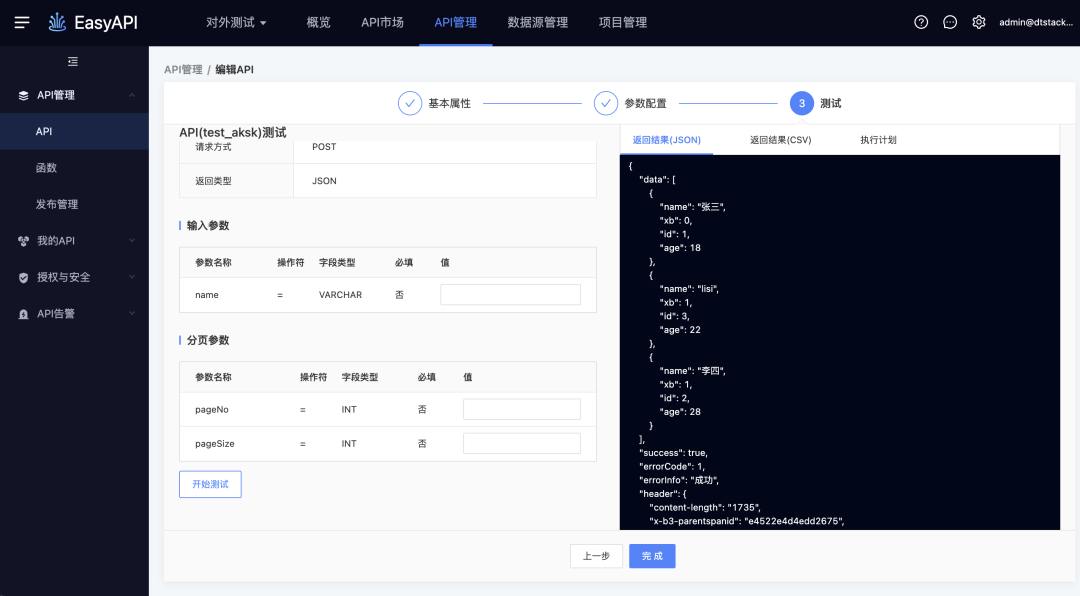
· 生成/注册API保存测试入参
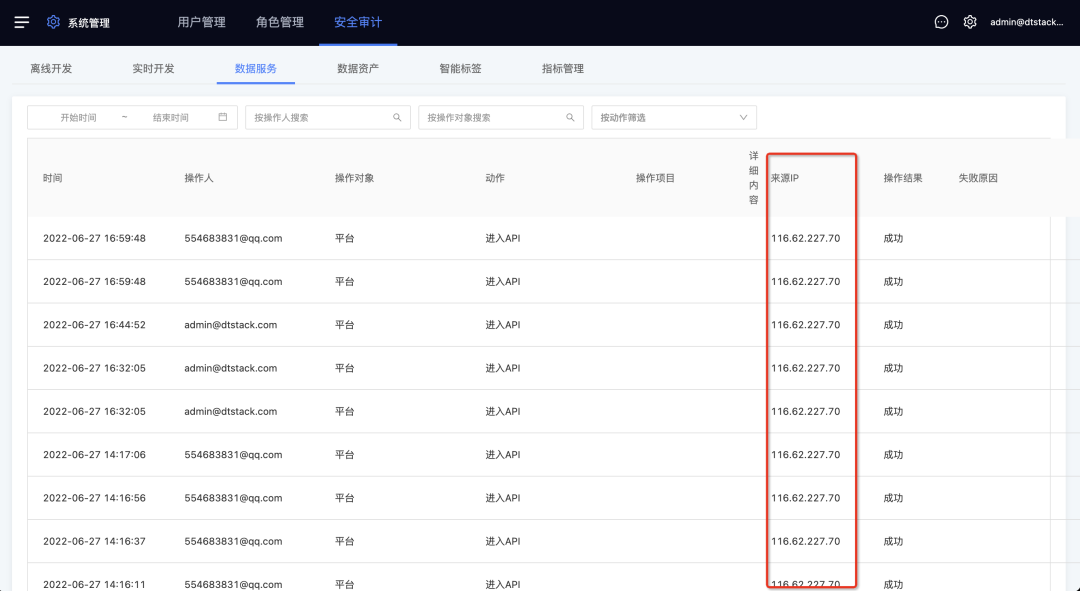
· 安全审计中增加IP
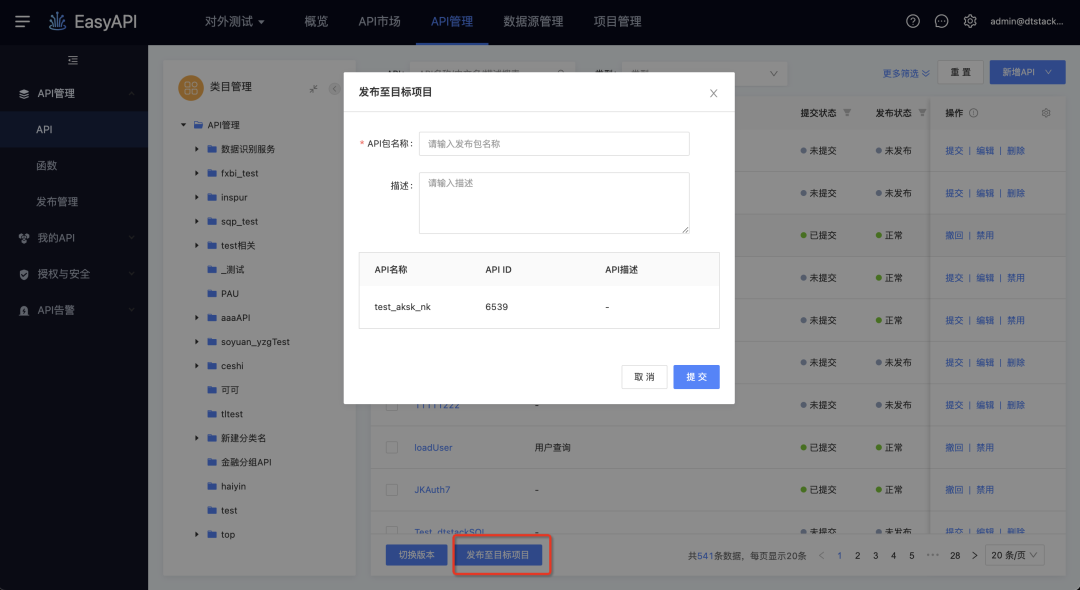
· API一键批量切换版本
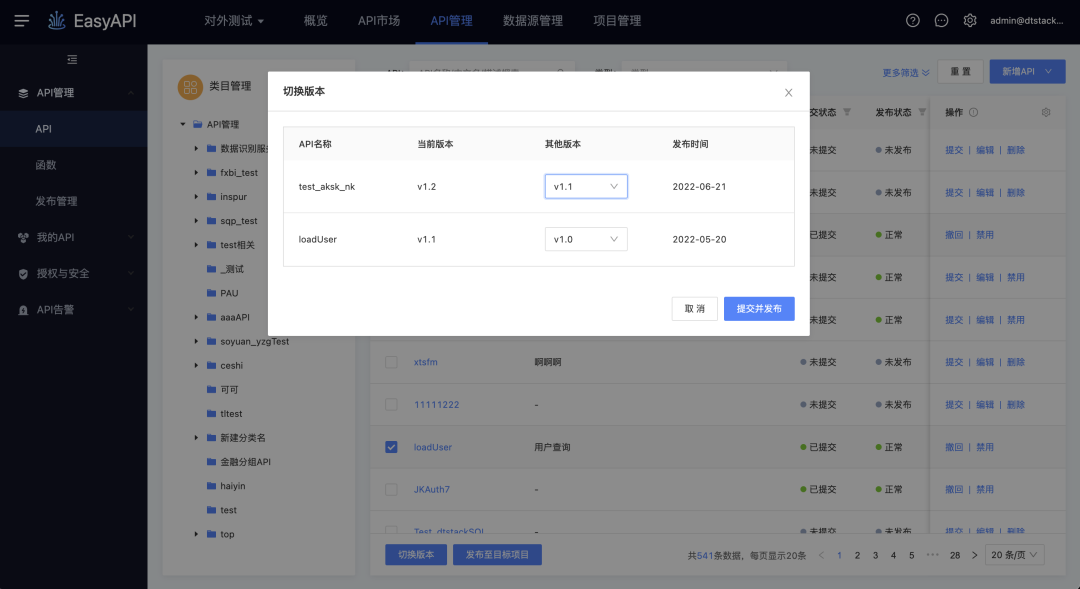
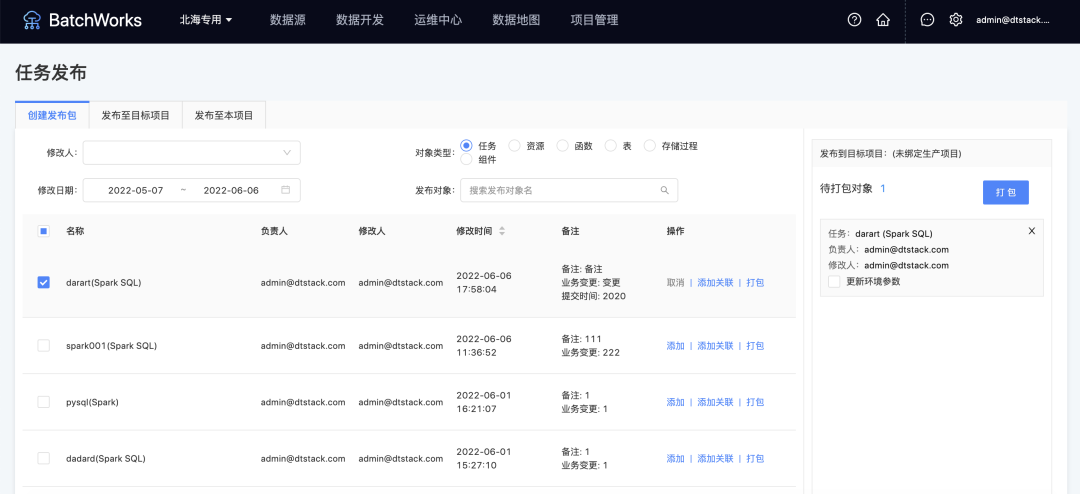
· 支持跨项目发布
(新增功能示意图)
数雁EasyDigit
客户数据洞察平台(原智能标签平台)
1.预置demo
新增功能说明
预置新零售行业、基金行业demo,demo里有示例数据,方便用户更好地结合实际业务场景体验产品功能。
(新增功能示意图)
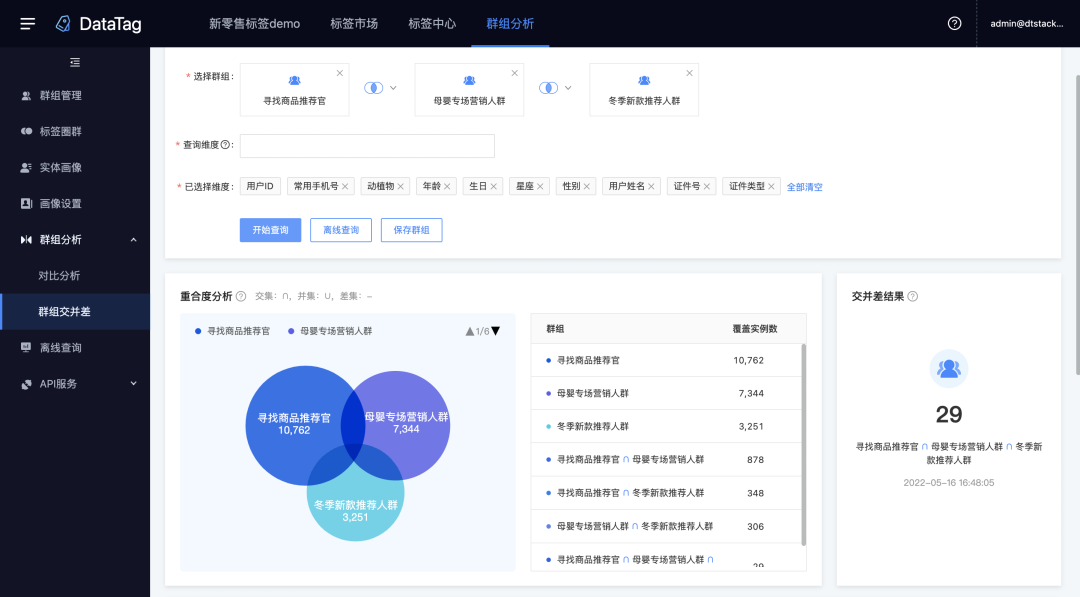
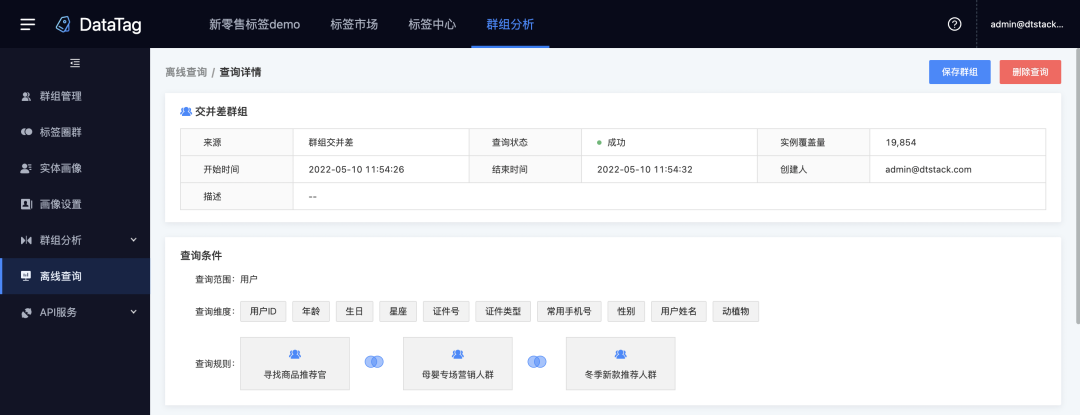
2.群组交并差
新增功能说明
对多个群组进行交集、并集、差集计算,分析群组的重合度情况,并形成一个新群组。
(新增功能示意图)
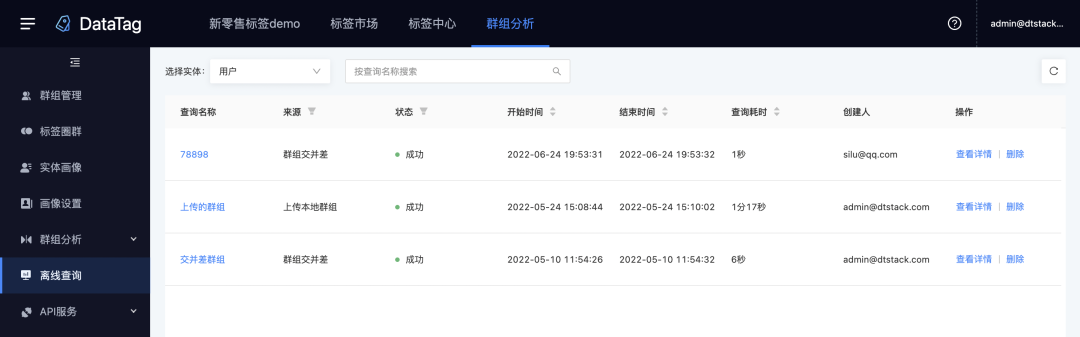
3.离线查询
新增功能说明
数据量较大时,为减轻系统的运行时间而进行的后台数据运算操作;点击查询后,没必要一直在页面等待结果。
(新增功能示意图)
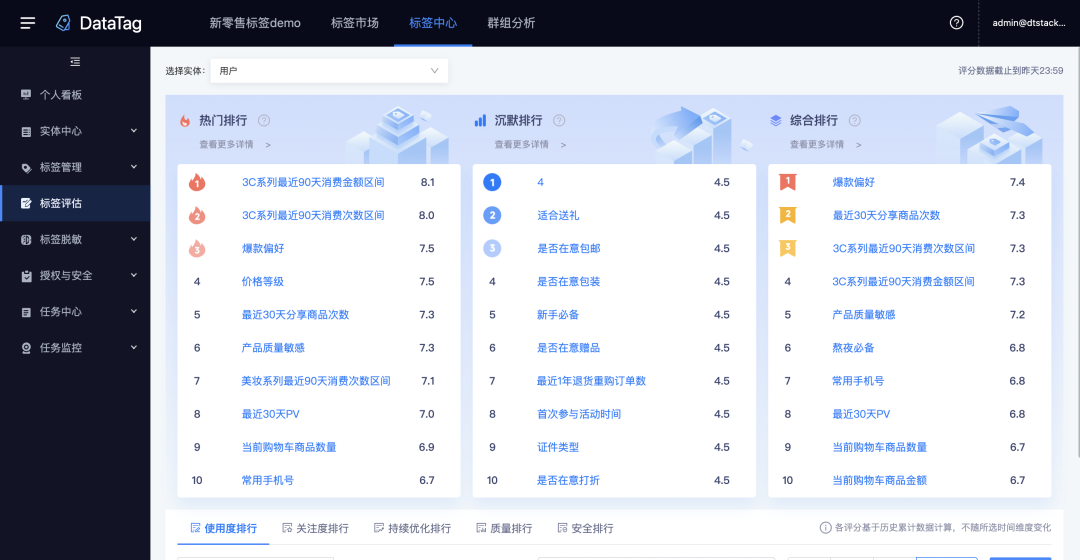
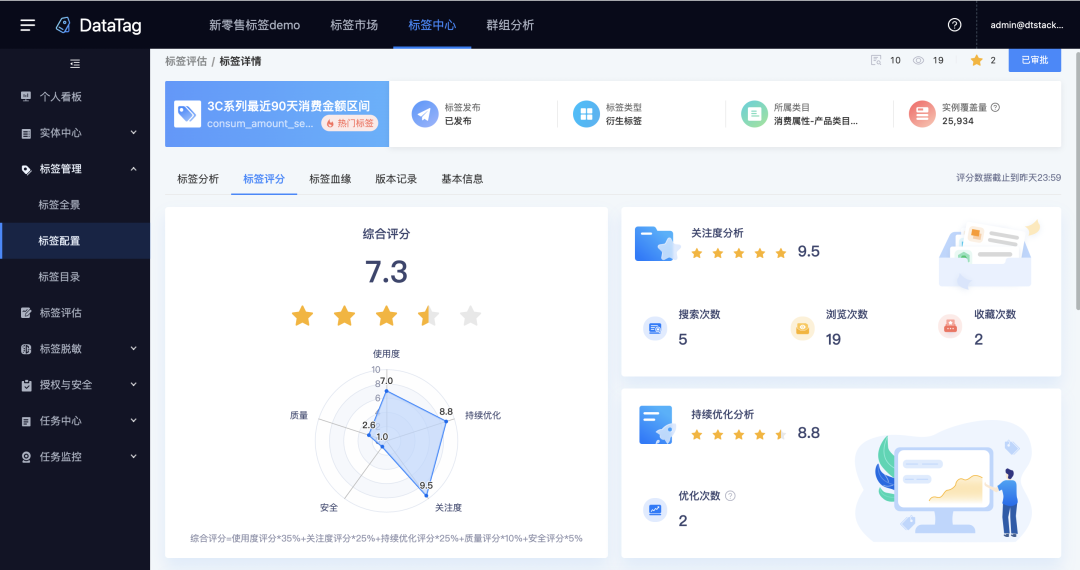
4.标签评估
新增功能说明
标签体系效果评估,支持查看标签评分,从标签使用评分、关注评分、质量评分、持续优化评分、安全评分等5个维度计算。
对标签效果进行多方位评估,有助于控制标签质量,帮助标签管理人员不断地提升使用价值。通过创建一套完整的评估体系,对于价值不高或质量较差的标签,可以考虑下线并持续优化,等达到要求后才上线至市场,开放给业务使用。
(新增功能示意图)
5.标签市场
新增功能说明
「标签市场」是面向所有人员开放的标签上架中心,标签管理、开发人员通过平台创建完标签后对其进行发布,即可发布至「标签市场」;通过「标签市场」,可查看所有已经发布的标签,了解标签的元数据和规则信息,分析标签分布情况、上下游血缘、对比版本信息,掌握标签的整体情况。本次升级了如下内容:
· 对热门标签、沉默标签进行标识
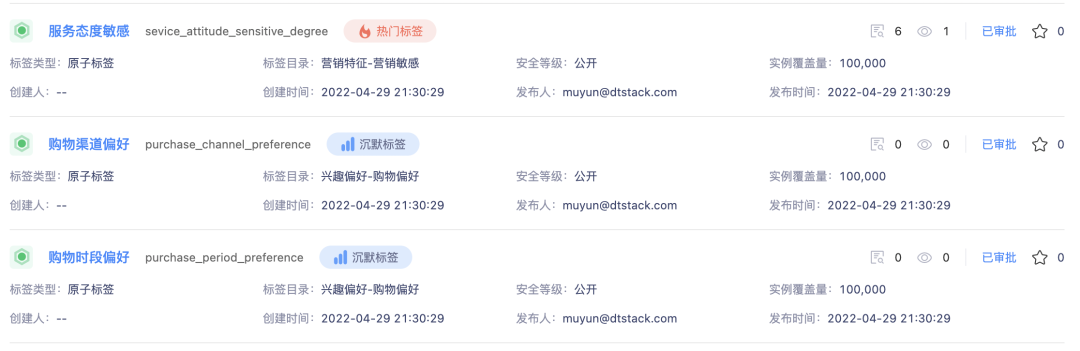
· 支持收藏标签,展示标签的浏览、使用次数
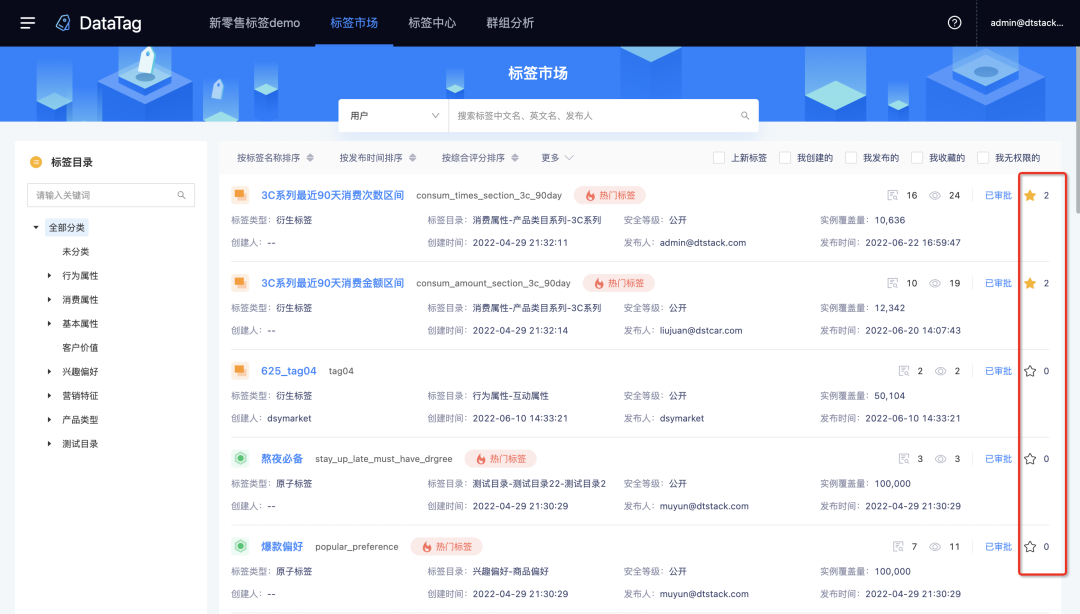
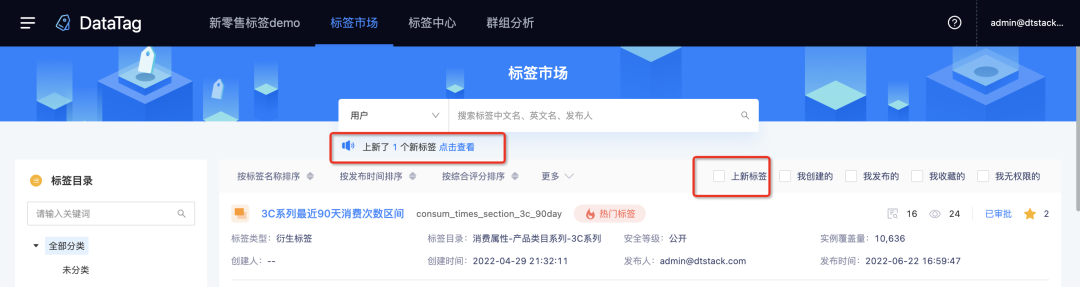
· 增加了标签的上新提醒
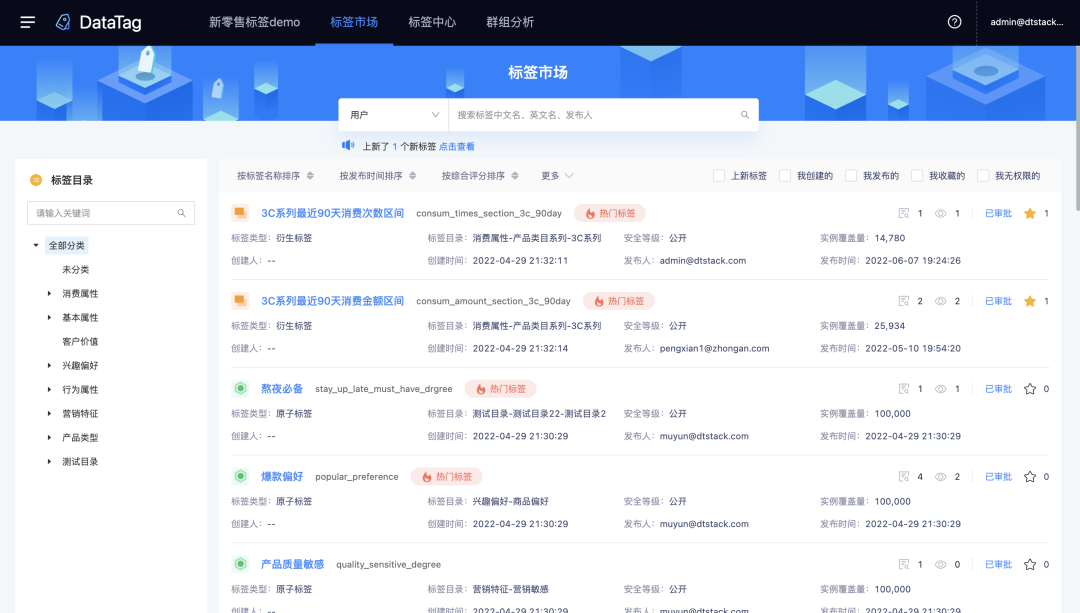
· 支持按照标签名称、发布时间、综合评分等规则排序
(新增功能示意图)
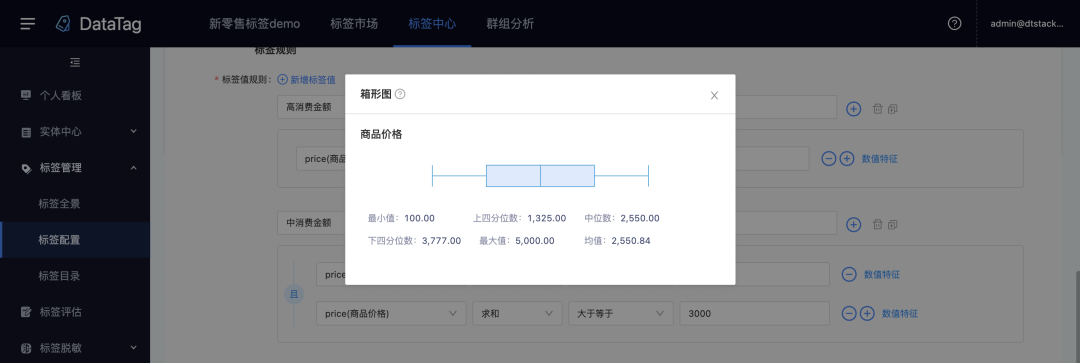
6.箱形图
新增功能说明
数值标签展示统计信息。标签创建时,可计算标签最大值、最小值、四分之一位数、四分之二位数、四分之三位数,方便用户分层。
(新增功能示意图)
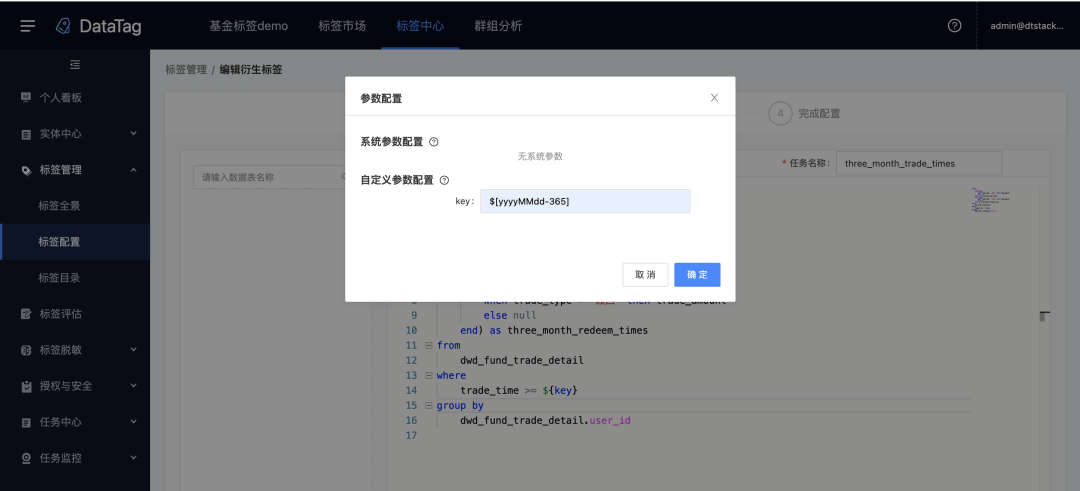
7.SQL标签
新增功能说明
加工SQL标签时支持自定义时间参数,可用于加工类似“最近30天···”等带统计周期的标签。
(新增功能示意图)
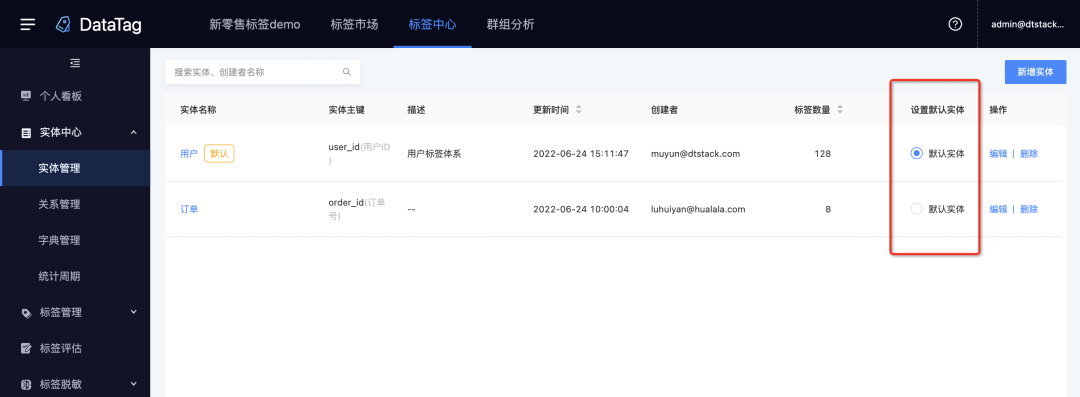
8.默认实体
新增功能说明
支持设置默认实体,平台内选择实体的地方将选中默认实体,减少用户的操作成本。
(新增功能示意图)
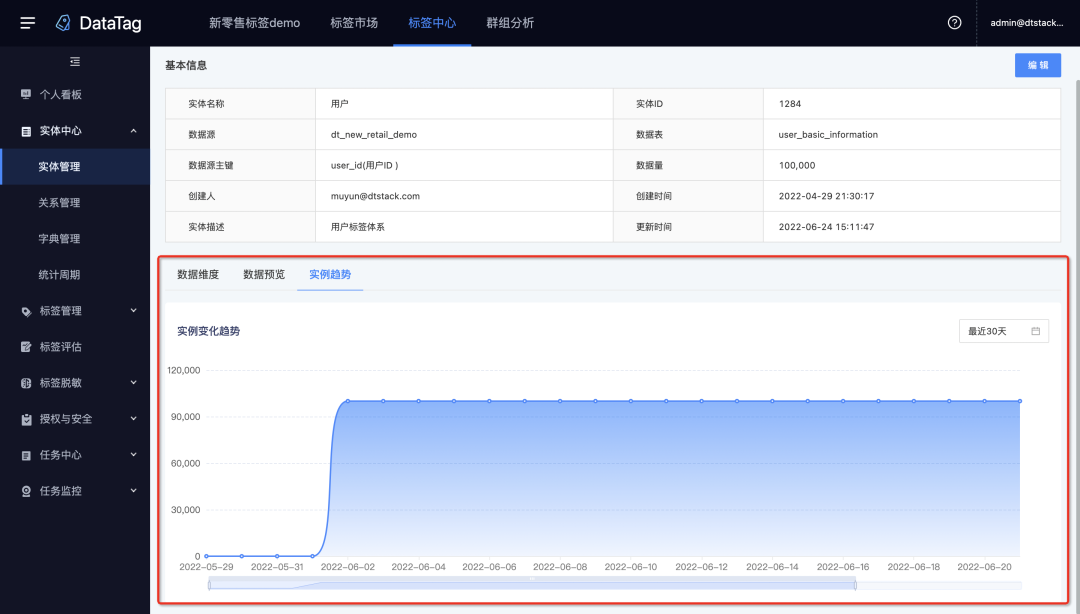
9.实体变化趋势
新增功能说明
支持查看实体的实例变化趋势,帮助用户掌握实体总数据量的历史变化。
(新增功能示意图)
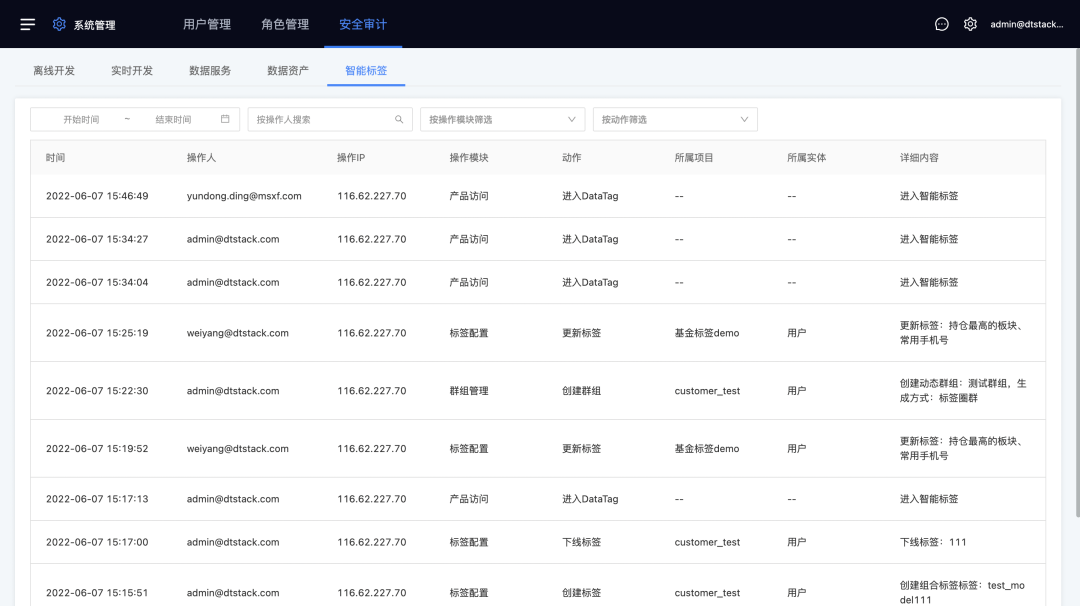
10.审计日志
新增功能说明
支持查看操作记录日志。
(新增功能示意图)
11.标签类目分布图
体验优化说明
通过下钻交互的矩形树图展示不同类目的标签分布情况。
(优化后示意图)

12.其他优化项
体验优化说明
· 支持源表修改数据类型:主表、辅表修改字段类型后,系统内部将自动同步
· 上传本地群组:功能界面及技术优化
· 主键重复问题优化:当源表的主键数据重复时,将处理系统内的表,保证标签大宽表、标签临时表的主键唯一
· Hbase表压缩:支持针对Hbase列簇指定不同的压缩格式,解决从Hive同步到Hbase导致的数据膨胀问题
· 主键脱敏:支持对主键标签脱敏
指标管理分析平台
1.预置demo
新增功能说明
预置银行绩效考核demo,demo里有示例数据,方便您更好地结合实际业务场景体验产品功能。
(新增功能示意图)
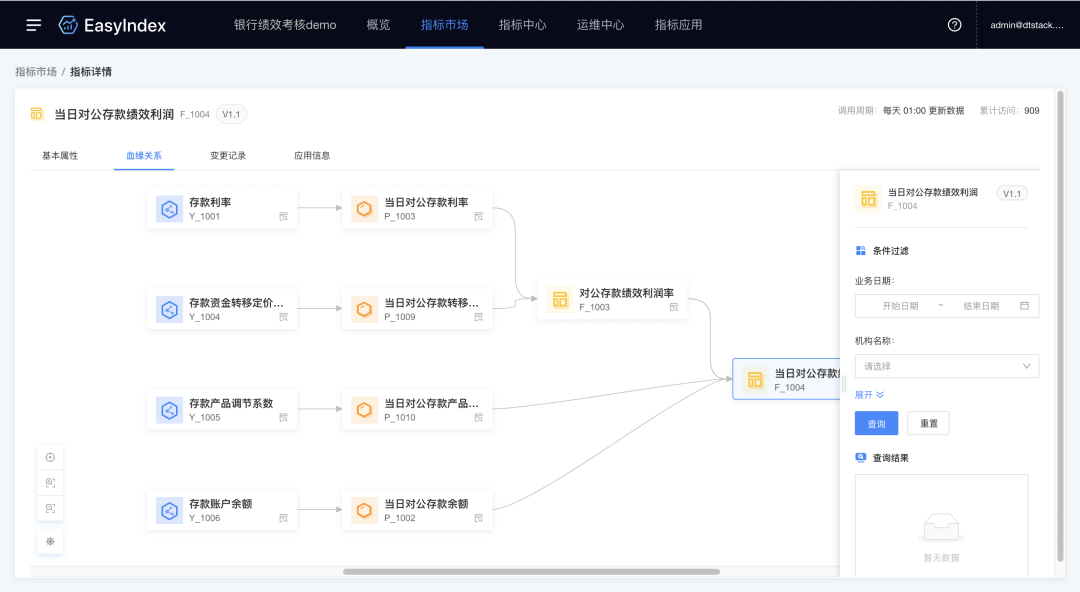
2.指标血缘
新增功能说明
支持查看指标上下游血缘关系,在线进行指标计算结果的溯源。
(新增功能示意图)
3.产品首页
新增功能说明
产品概览分析页面,展示项目的整体情况。
(新增功能示意图)

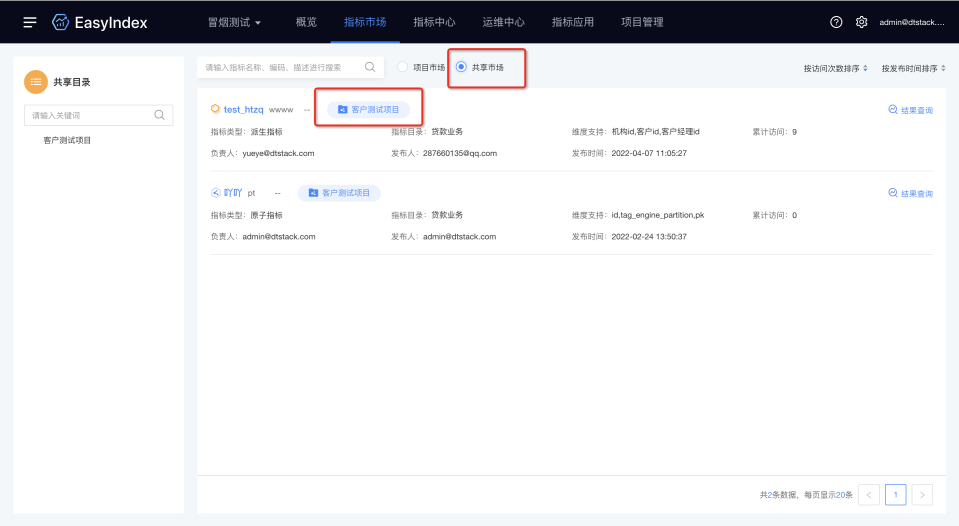
4.指标共享
新增功能说明
跨项目的指标共享,针对租户级别的用户,可以选择将A项目市场下的指标共享到B项目的共享市场中,实现跨项目的指标分享,共享的同时,可以控制共享的规则,控制被共享的项目查看的数据范围。
(新增功能示意图)
5.数据权限
新增功能说明
指标数据行级访问范围控制,支持针对指标的计算结果,控制查看的行级数据范围,支持针对用户的属性动态设置权限规则。
(新增功能示意图)
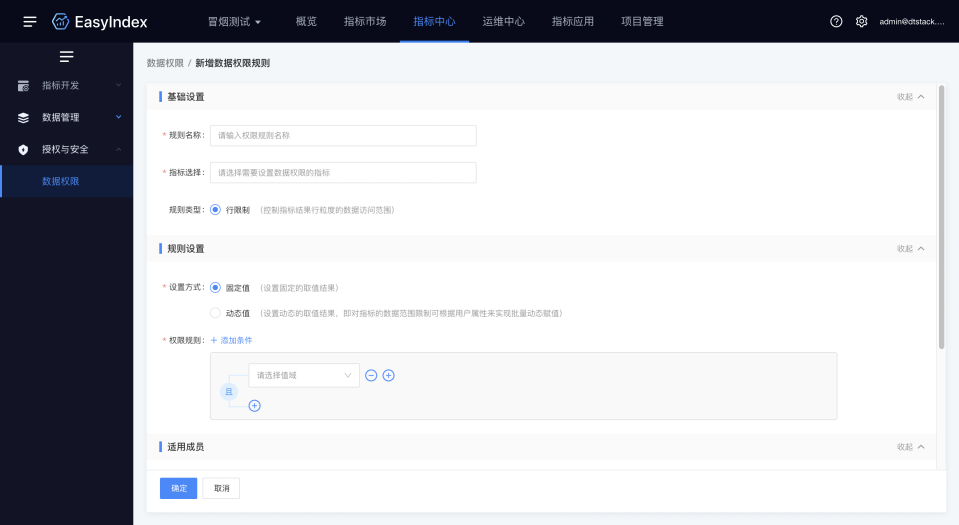
6.交互升级
新增功能说明
· 支持选中指标后,拖动到画布界面,插入公式中的任意位置
· 增强了组件左右添加效果
· 优化了画布右侧拉伸使用效果
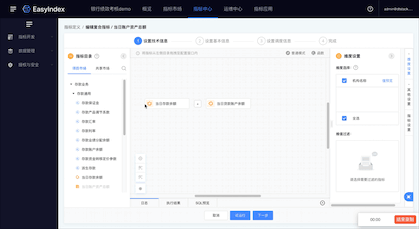
(新增功能示意图)
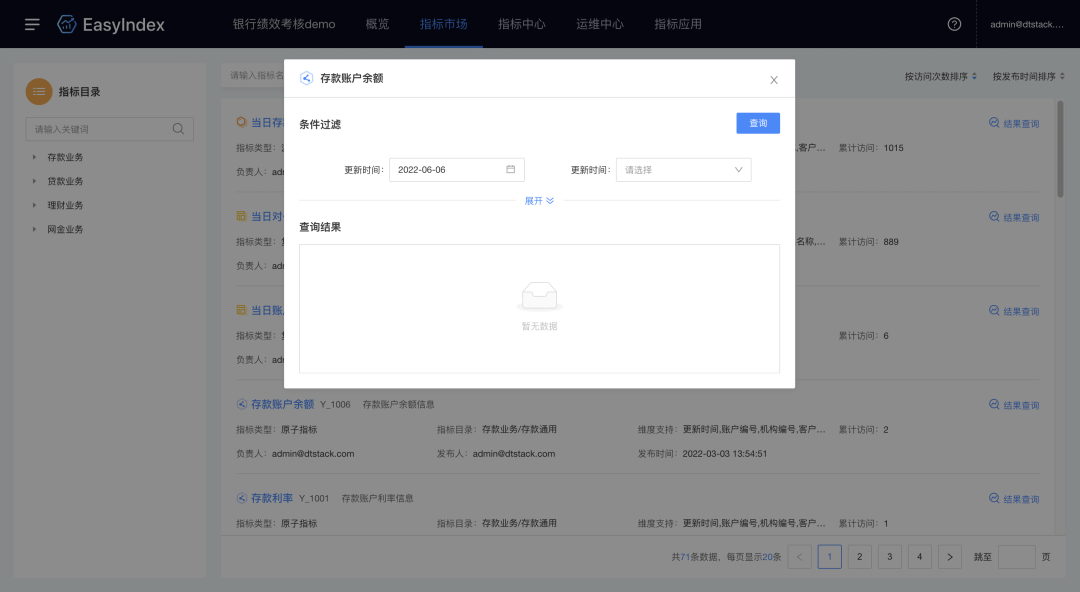
7.原子指标结果查询
新增功能说明
· 针对原子指标的来源表,进行有条件的结果数据查询
· 支持在指标市场中,选择原子指标进行结果查询
(新增功能示意图)
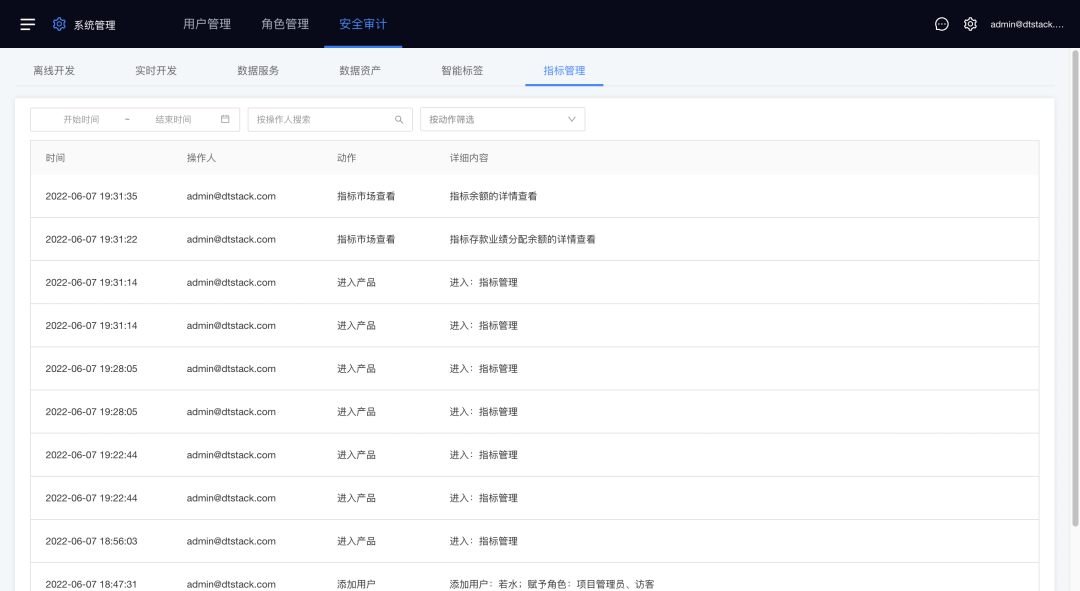
8.审计日志
新增功能说明
支持查看操作记录日志。
(新增功能示意图)
9.产品优化项
体验优化说明
· 数字开头的schema、table表名适配,代码中会自动加双引号
· 数据模型前端重构
· 运维中心单独开发
· 复合指标操作界面自适应
标签:功能,01,标签,新增,支持,诚心,说明,袋鼠,示意图 来源: https://www.cnblogs.com/DTinsight/p/16649875.html