如何发现问题
作者:互联网
如何发现问题
服务端开发实践分享
引入
过去,我们常常讨论:如何解决问题?
往往一个项目上线前,反馈很好,稳定性很高。
但是,上线后,卡顿、炸服、宕机,常有的事。
问题还是有的,只是我们没有发现。
没有问题,才是最大的问题。
换个思考方向:如何发现问题?
铺垫
问题被发现的来源:以bug为例
- 测试提单
- 用户反馈
这样子太被动,我们要化被动为主动。
目标:
- 在测试提单前,解决掉,不给测试提单的机会。
- 在产生影响前,解决掉,不给用户吐槽的机会。
做了哪些?
- 提前沟通
- 静态分析
- 代码审查
- 日志系统
- 日志推送
- 监控系统
- 数据链条
- 内部测试
一、提前沟通
主动提前去沟通需求。
思考:为什么要做这个需求? 开发要学会如何决策。
程序对项目负责,不是对策划负责。
需求文档中最重要的部分:设计思考。
出发点:万物生于有,有生于无。需要改,请趁早。
二、静态分析
bug有多高级,原因就有多低级。
一次10分钟的检查,能规避掉很多因手误产生的bug,节约大量调试时间。
工具:Cppcheck、TScanCode、Luacheck
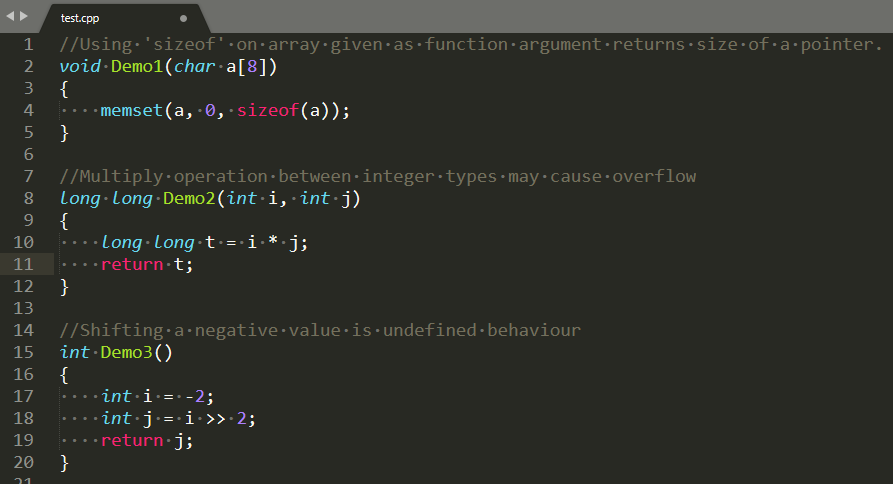
出发点:快速发现低级错误。
三、代码审查/Code Review
代码审查是真正的白盒测试。
没有经过代码审查,仅凭测试很难保证代码质量。
代码审查目的:相互学习。
找问题是副产品。
出发点:换一个角度看事物,避免思维定式。
四、日志系统
把日志打好、打全。
好的标准:针对简单的业务,能通过日志100%确定原因。
如果没有这一行日志,会不会影响定位问题?如果会,那就加上。
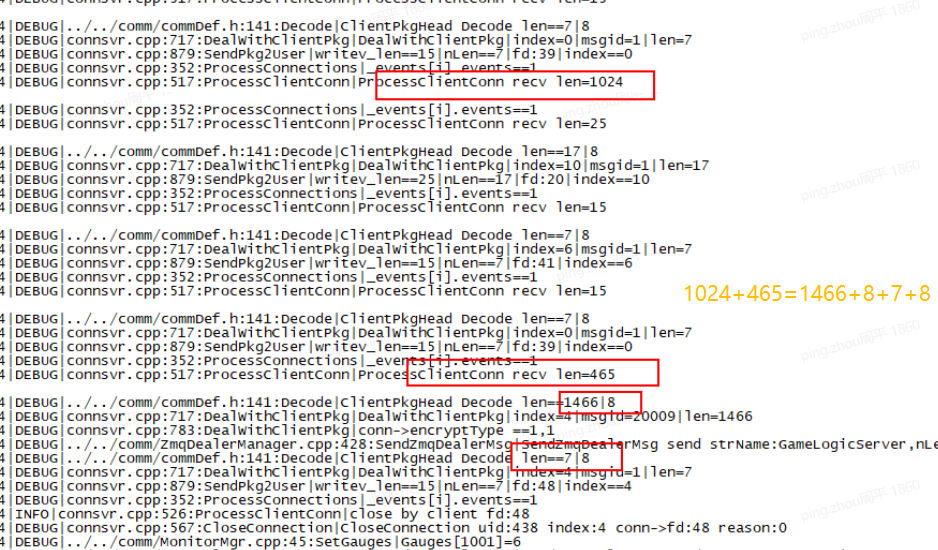
出发点:日志是调试的最佳利器,没有之一。
五、日志推送
在错误发生时,及时提醒开发,从而快速修复。
内网:信鸽 外网:Sentry
不同的场景下,选择不同的工具。
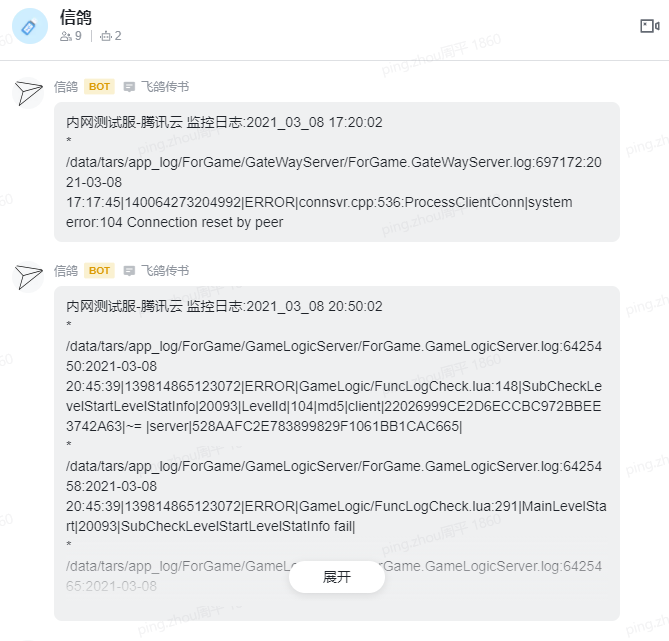
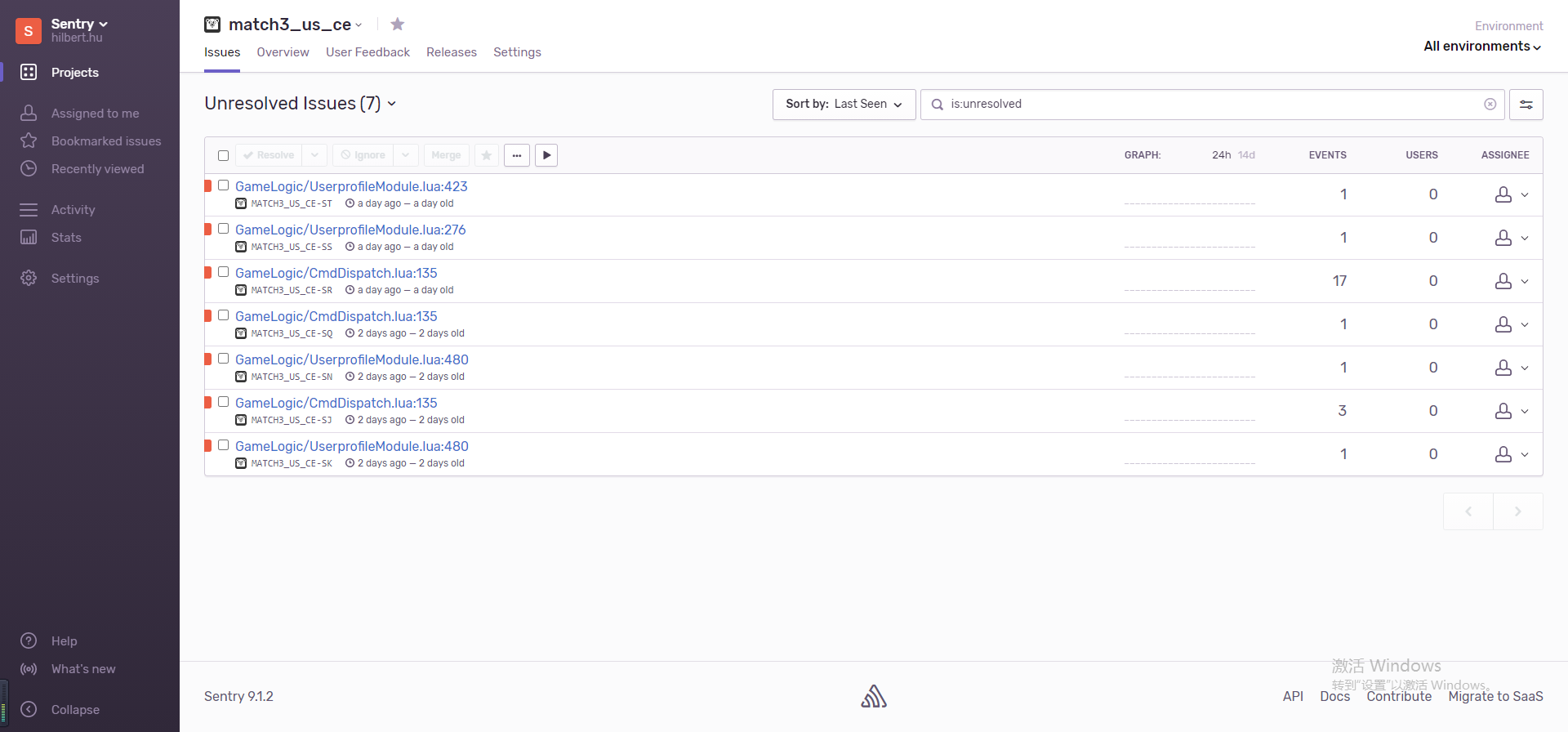
出发点:互联网服务 核心价值观之一:“不要我等”。
六、监控系统
基础层面:
如:机器、mysql、redis、process
业务层面:
如:在线人数、进程间的连通性、登录耗时、资源使用量
用途:压测、日常检查、报表输出
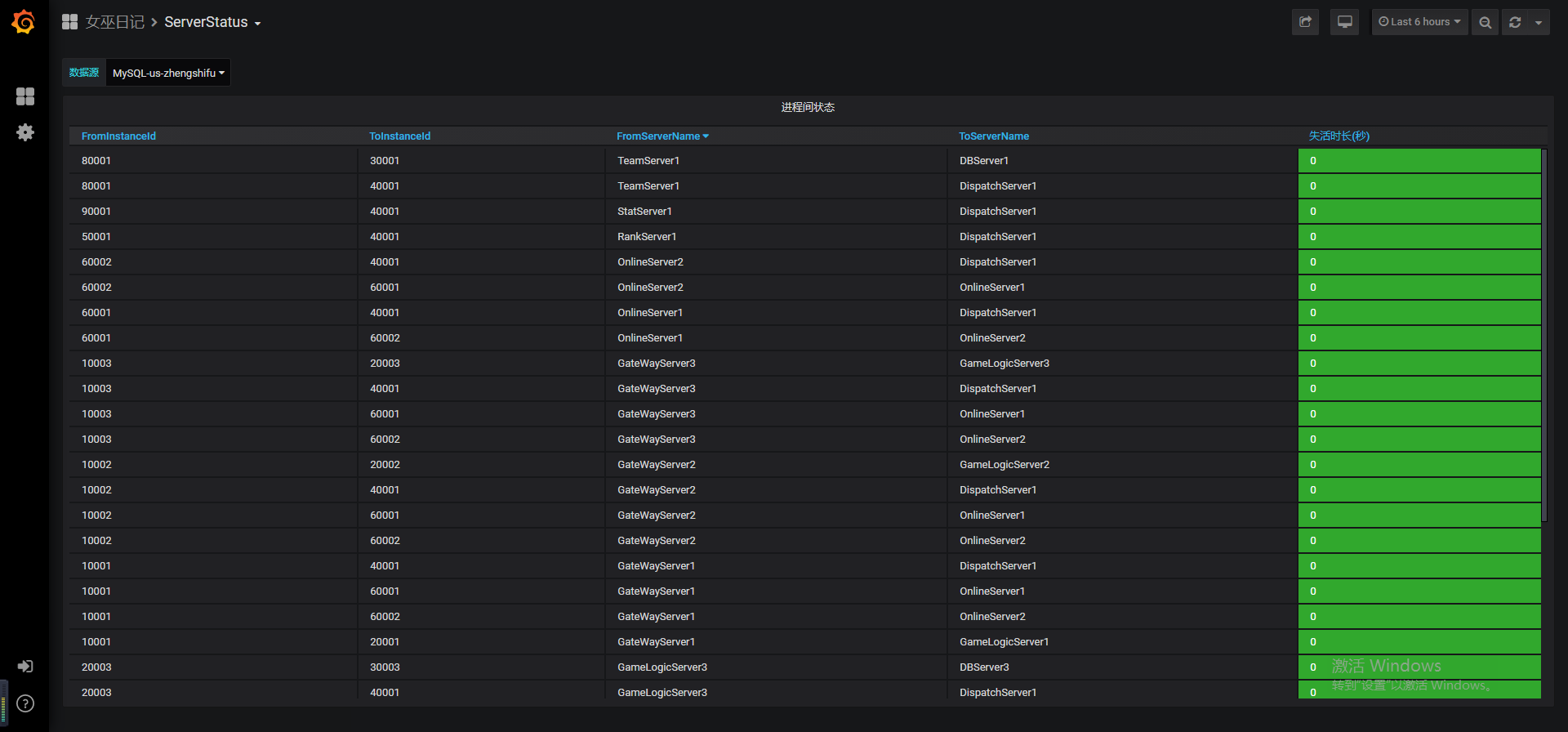
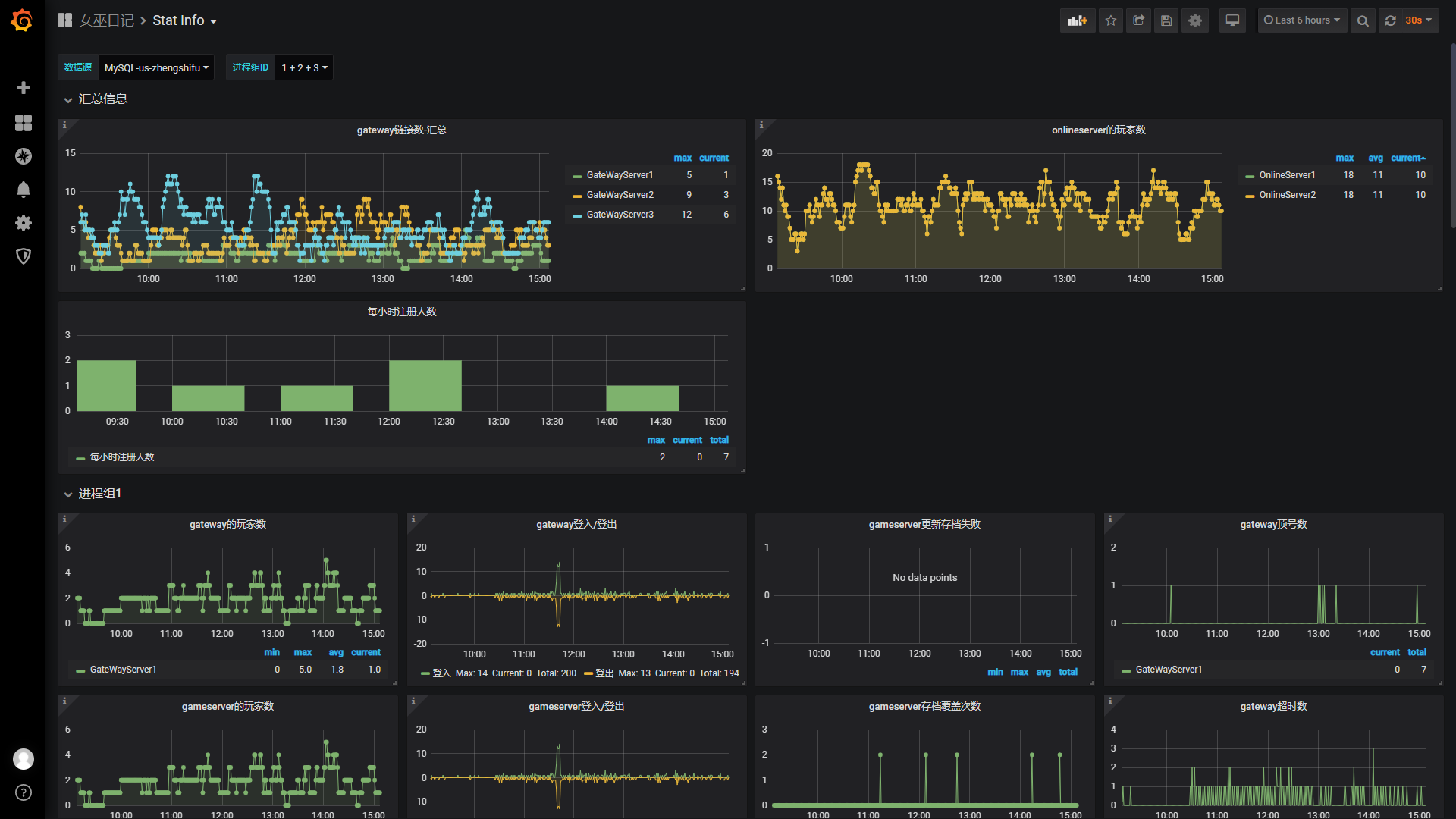
出发点:错误在一个时刻点看不出来,但在一段时间内就很明显了。
七、数据链条
客户端的表现,正常的;服务端的日志,也正常的;但是,数据就是不对。
原因:数据出错后,不会立即显现,需要过一段时间才会暴露。
记录所有的数据变化:结构化、统一化。
保证出问题时,可以回溯历史,获得出错时间点的上下文。
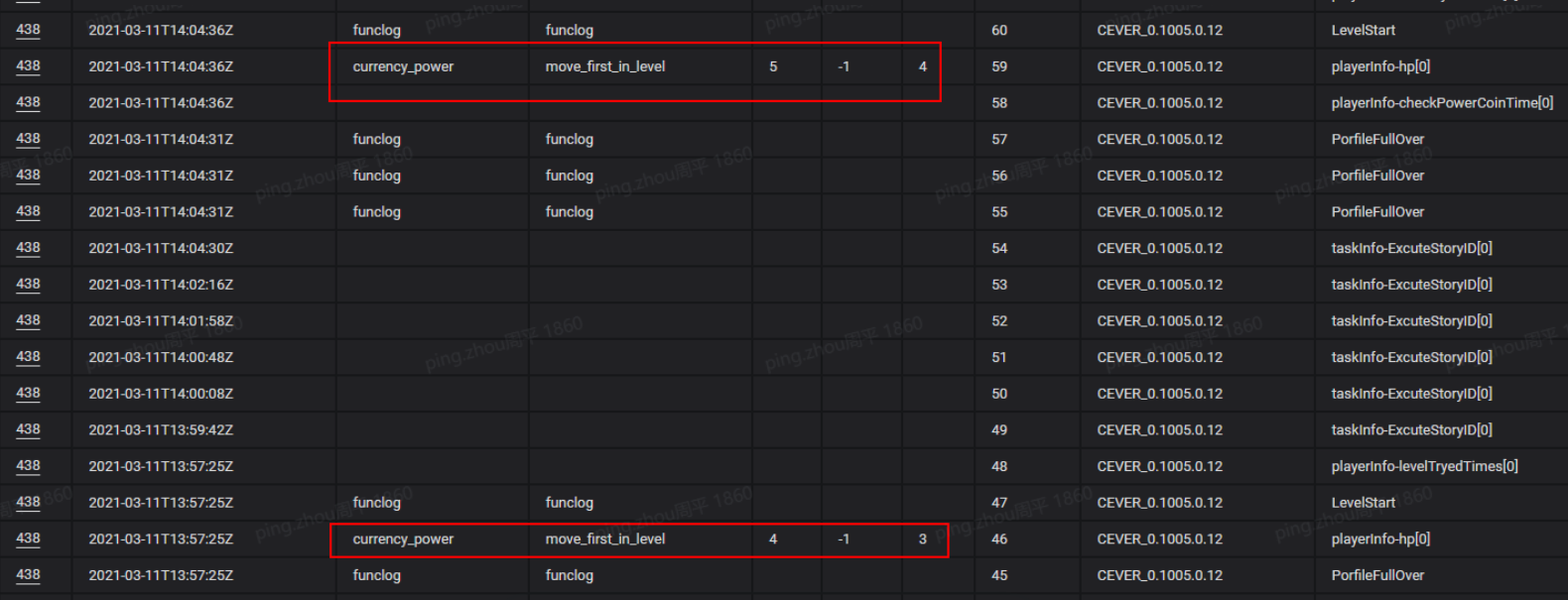
出发点:数据链,是环环相扣的。
八、Dogfooding / 内部测试
因微软而广为人知,一封题为“Eating our own Dogfood”的邮件,目的:提高内部使用自家产品的比重。
这个方法常被用来作为彰显对自家产品信心的手段。
在体验的过程中,发现了一些问题,尤其是细节上的处理。
本质:同理心。
出发点:如果打算让顾客买我们的产品,那么至少我们也要愿意使用这些产品。
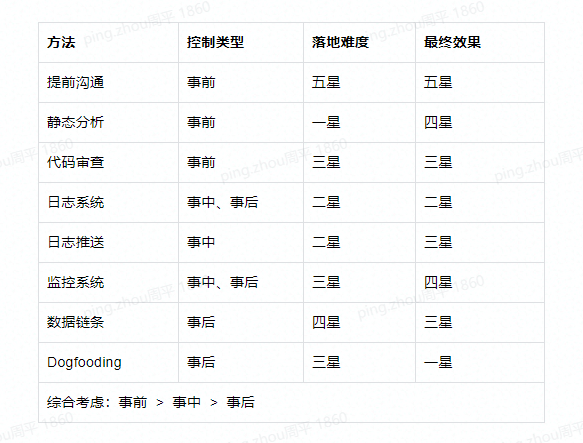
效果
上面的这几点,是已经被验证过行之有效的,也是比较容易落地的。
实际上,一开始代码写的也有问题,只是提前发现了,然后及时修复了。
屠龙刀固然厉害,用的最多的还是菜刀。
核心
问题意识:发现在早 预防在先 解决在小
培养问题意识:
- 发现问题的能力
- 提出问题的能力
- 分析问题的能力
- 解决问题的能力
- 总结问题的能力
发现问题的能力:防患于未然
标签:发现,审查,出发点,代码,问题,如何,日志 来源: https://www.cnblogs.com/txtp/p/16626696.html