左偏树
作者:互联网
作为可并堆的一种,左偏树算是又好写功能全且复杂度比较优的了
首先介绍一下结构:
左偏是指定义的 \(dis\) 值左子树比右子树大
\(dis\) 指的是 \(min(son_0,son_1)+1\),叶节点为零
注意这里的 \(dis\) 并不是深度,左偏树的深度是没有保证的,哪怕是一条链,只要满足左偏的性质就是符合的
所以要查询堆顶并不能暴力跳父亲,而是要额外开并查集来储存
能保证复杂度大概是因为只要有右子树是空的那么就能插入,那么 \(dis\) 的定义方式就很科学
那么接下来是变形操作
由于左偏树有着二叉树结构,那么也是支持懒标记的,一定注意每次删除堆顶前要先 \(spread\)
当然,理论上也可以可持久化,然而并没有遇见过这样的毒瘤题
以下是一些例题:
用于简单维护集合元素
堆中维护当前活着的骑士集合,由于骑士的死是一次性的且单调,那么每个点暴力弹出即可
每个城有增益效果,懒标记维护即可
代码
#include<bits/stdc++.h>
using namespace std;
#define int long long
const int maxn=3e5+5;
const int maxm=3e5+5;
int n,m,val[maxn],fa[maxn],son[maxn][2],dis[maxn],lazy[maxn],lazy1[maxn];
int sum[maxn],ans[maxn],dep[maxn],hd[maxn],cnt,rt[maxn],a[maxn],b[maxn],c[maxn],st[maxn];
int read(){
int x=0,f=1;char ch=getchar();
while(!isdigit(ch)){if(ch=='-')f=-1;ch=getchar();}
while(isdigit(ch)){x=x*10+ch-48;ch=getchar();}
return x*f;
}
struct Edge{
int nxt,to;
}edge[maxm];
void add(int u,int v){
edge[++cnt].nxt=hd[u];
edge[cnt].to=v;
hd[u]=cnt;
return ;
}
void dospread(int x,int mul,int add){
if(!x)return ;
val[x]*=mul;val[x]+=add;lazy[x]*=mul;lazy1[x]*=mul;lazy1[x]+=add;
return ;
}
void spread(int x){
dospread(son[x][0],lazy[x],lazy1[x]);
dospread(son[x][1],lazy[x],lazy1[x]);
lazy[x]=1,lazy1[x]=0;
return ;
}
int merge(int x,int y){
if(!x||!y)return x+y;
if(val[x]>val[y])swap(x,y);
spread(x);son[x][1]=merge(son[x][1],y);
if(dis[son[x][0]]<dis[son[x][1]])swap(son[x][0],son[x][1]);
dis[x]=dis[son[x][1]]+1;
return x;
}
void dfs(int u){
for(int i=hd[u];i;i=edge[i].nxt){
int v=edge[i].to;dep[v]=dep[u]+1;
dfs(v);rt[u]=merge(rt[u],rt[v]);
}
while(rt[u]&&val[rt[u]]<a[u]){
ans[rt[u]]=dep[st[rt[u]]]-dep[u];sum[u]++;spread(rt[u]);
rt[u]=merge(son[rt[u]][0],son[rt[u]][1]);
}
if(!b[u])dospread(rt[u],1,c[u]);
else dospread(rt[u],c[u],0);
return ;
}
signed main(){
n=read(),m=read();dis[0]=-1;
for(int i=1;i<=n;i++)a[i]=read();
for(int i=2;i<=n;i++)fa[i]=read(),add(fa[i],i),b[i]=read(),c[i]=read();
for(int i=1;i<=m;i++)val[i]=read(),st[i]=read(),lazy[i]=1,rt[st[i]]=merge(rt[st[i]],i);
dfs(1);while(rt[1])ans[rt[1]]=dep[st[rt[1]]]+1,spread(rt[1]),rt[1]=merge(son[rt[1]][0],son[rt[1]][1]);
for(int i=1;i<=n;i++)printf("%d\n",sum[i]);for(int i=1;i<=m;i++)printf("%d\n",ans[i]);
return 0;
}
用于优化 dp 转移
如果 \(dp\) 数组表示的是一些决策,而这些决策是具有贪心或单调性的,那么常常可以通过差分的方式优化
其实这个差分之所以可以优化,是因为相当于手动把所有决策拆分开来,因此对于较简单的问题常常直接从贪心+启发式合并的角度考虑会更好理解
对于 \(dp\) 数组是一个一次函数等特殊形式的情况,往往可以用一些技巧维护出这个函数的样子,而不用维护出每个位置
设 \(f[u][i]\) 表示子树 \(u\) 以 \(i\) 的血量进入能得到的血量
那么答案直接取 \(f[u][0]\) 即可,可以把 \(t\) 下面挂一个权值为 \(inf\) 的点
发现转移很浪费时间
那么不妨把 \(f\) 转化成多个二元组 \((x,y)\),表示以 \(x\) 的血量进入最多增加的血量 \(y\)
过程变成了用当前血量对应从小到大取二元组直到不满足
那么每个点的二元组用堆来维护
那么每个点首先要把子树的堆合并起来
考虑加入 \(a_u\) 后的贡献:
如果 \(a_u\) 大于零,那么直接增加 \((0,a_u)\)
否则考虑进行合并:首先以 \(-a_u\) 作为初始血量来进入这个点,\(a_u\) 为初始的增加量
那么从小到大来取子树中的二元组来进行合并,直到不能合并为止
发现如果增加量为负一定不优,那么这时候需要继续拿,那么相应的血量应该变为 \(x-y'\),指先消耗 \(y'\) 还能进行拿取操作,直到增加为正为止
\(update\):合并的部分貌似有点儿抽象啊,来补充一下
其实就是说如果 \(a_u\) 为负数,那么本来应该增加 \((-a_u,a_u)\),但是需要保证 \(x<-a_u\) 的二元组不会被先取到,那么要把它们都消掉,也就是一直把它们和 \((-a_u,a_u)\) 合并
同时,为了避免加入一个负贡献的二元组,还需要继续往后合并一些二元组使得贡献为正,注意这样可能会让下限提高
对于每个点的堆中存放所有覆盖了子树中所有边以及父亲边的方案,每次取出合法的堆顶即是最小值,设为 \(f_x\)
对于一个节点合并子树时,设 \(sum\) 为 \(\sum f_{son}\),那么应该对子树 \(v\) 的所有方案加上 \(sum-f_v\)
同时对于每个堆顶排除不合法的方案
代码
#include<bits/stdc++.h>
using namespace std;
#define int long long
#define pi pair<int,int>
#define fi first
#define se second
#define mp make_pair
const int maxn=3e5+5;
const int maxm=6e5+5;
int n,m,dis[maxn],lazy[maxn],dep[maxn],fa[maxn],f[maxn],son[maxn][2],rt[maxn],ans,x,y,w,hd[maxn],cnt;
pi val[maxn];
int read(){
int x=0,f=1;char ch=getchar();
while(!isdigit(ch)){if(ch=='-')f=-1;ch=getchar();}
while(isdigit(ch)){x=x*10+ch-48;ch=getchar();}
return x*f;
}
struct Edge{
int nxt,to;
}edge[maxm];
void add(int u,int v){
edge[++cnt].nxt=hd[u];
edge[cnt].to=v;
hd[u]=cnt;
return ;
}
void dospread(int x,int w){
if(x)lazy[x]+=w,val[x].fi+=w;
return ;
}
void spread(int x){
dospread(son[x][0],lazy[x]);
dospread(son[x][1],lazy[x]);
lazy[x]=0;
return ;
}
int merge(int x,int y){
if(!x||!y)return x+y;
if(val[x]>val[y])swap(x,y);
spread(x);son[x][1]=merge(son[x][1],y);
if(dis[son[x][0]]<dis[son[x][1]])swap(son[x][0],son[x][1]);
dis[x]=dis[son[x][1]]+1;
return x;
}
void dfs(int u){
int sum=0;
for(int i=hd[u];i;i=edge[i].nxt){
int v=edge[i].to;
if(v==fa[u])continue;
fa[v]=u;dep[v]=dep[u]+1;dfs(v);
dospread(rt[v],-f[v]);sum+=f[v];rt[u]=merge(rt[u],rt[v]);
}
dospread(rt[u],sum);
while(rt[u]&&dep[val[rt[u]].se]>=dep[u]){
spread(rt[u]);rt[u]=merge(son[rt[u]][0],son[rt[u]][1]);
}
if(u==1)return ;
if(!rt[u]){puts("-1");exit(0);}
f[u]=val[rt[u]].fi;
if(fa[u]==1)ans+=f[u];
return ;
}
signed main(){
n=read();m=read();dis[0]=-1;
for(int i=1;i<=n-1;i++)x=read(),y=read(),add(x,y),add(y,x);
for(int i=1;i<=m;i++)x=read(),y=read(),w=read(),val[i]=mp(w,y),rt[x]=merge(rt[x],i);
dfs(1);cout<<ans;
return 0;
}
P4331 [BalticOI 2004]Sequence 数字序列
提供两种方法:
首先假设为简化版:\(b\) 的限制条件是小于等于
观察发现,对于一段递增的 \(a\),那么 \(b\) 是对应的最优
对于一段递减的 \(a\),那么 \(b\) 是 \(a\) 的中位数时最优
那么考虑将原数列划分为许多段递减的段,每一段都取中位数
发现这样取完 \(b\) 后可能会出现前一个 \(b\) 比后一个 \(b\) 大的情况
那么把前一段和后一段的数合并后再求中位数即可
中位数可以用堆求,弹出直到剩下一半
由于有合并操作,用左偏树维护
这里提供一个更加精妙的做法:
考虑设计一个 \(dp\):\(f[i][j]\) 表示前 \(i\) 个最后一个为 \(j\) 的最小值
转移有两个:\(f[i][j]=f[i-1][j]+|a_i-j|\),\(f[i][j]=min(f[i][j],f[i][j-1])\)
如果对于每个 \(i\) 把 \(dp\) 数组看成一个关于 \(j\) 的函数图像
一定是一个下凸函数
加上取 \(min\) 操作,那么是一个先下降再不变的样子
那么考虑维护出每次这个函数加上一个下凸函数会变成什么样子
先画张图:
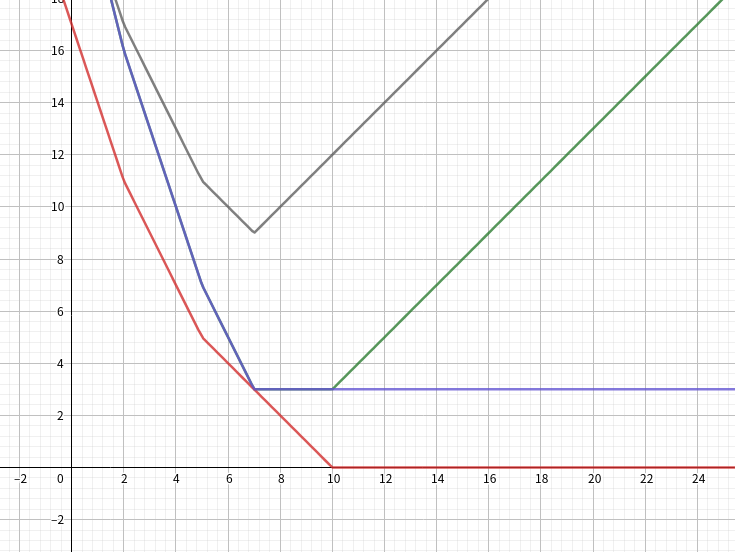
考虑将所有的拐点都放进堆里
那么每次加入一个函数,会让顶点左边的斜率减 \(1\),右边的加 \(1\)
那么最右边的一个拐点如果在顶点右侧,那么之后的斜率为零的直线会变成斜率为 \(1\) 的,然后取个 \(min\) 就没了,于是这种情况每次需要把堆顶弹出
每次更新 \(dp\) 数组所用的值一定是最后一个拐点,取堆顶即可
斜堆
这道题提到了斜堆的性质,顺便记录一下
考虑最后一个节点的来源,根据题意,新插入的节点一定是一路向左,然后往下面挂左儿子得到的
那么只有两种情况:根节点左儿子路径上第一个没有右儿子的节点,或者是极左链的叶节点(且父亲没有右节点)
两种都判断一下,优先选第二种(因为字典序更小)
标签:ch,return,int,son,那么,maxn,左偏 来源: https://www.cnblogs.com/yang-cx/p/15609806.html