如何像Facebook一样构建数据中心 – BGP在大规模数据中心中的应用(3)
作者:互联网
作者简介:史梦晨,曾就职于国内金牌集成商, 现就职于EANTC( 欧洲高级网络测试中心),研究方向:网络架构,测试,运维(大规模数据中心,SD-WAN,EVPN,Segment Routing, NFV), 邮箱superrace@gmail.com
在之前的章节中,我们学习了RFC7938中介绍的关于:
- 为什么选择bgp
- 如何设计ASN
- 如何通告路由条目以及在何处进行边界汇总
今天来继续讨论一些路由设计的细节

ECMP
基础ECMP
ECMP是CLOS拓扑里面基本的流量分担机制,有以下特点/属性:
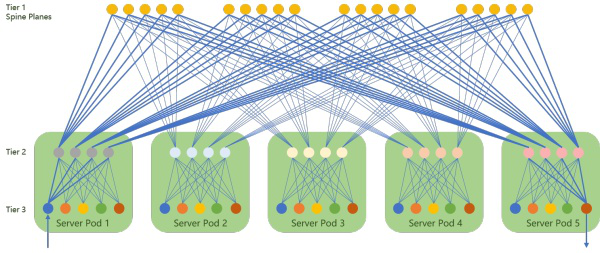
- 所有去往相同IP的流量都应该由从低层tier往所有的高层tier的链路分担。(如图一:tier 3到tier 2有4个链路,tier 2到tier 1 有5个)
- ECMP路径的数量由tier 1设备数量决定(如图一,20条负载均衡链路)
- 需要所有的设备都支持Multipath fanout,最大的数量不能少于上行方向或下行方向直连链路的最大值(如图一,20),同时,这个数量不能超过任意设备的1/2的借口数量(比如fanout 32就需要全网交换机不能少于64个口,也就是说用64口交换机最多部署32个tier 1设备)
- BR可能对这个数量会需求更多,如果做路由汇总的话
- 如果ECMP路径数量达不到需求的话(比如最大10条),可以混合使用2层的逻辑链路聚合(比如每2条链路聚合成一条),但是这样带来的问题就是在第二级的ECMP可以用的entropy就少了从而可能部分链路不能被利用上(flow polarization)
基于multiple ASNs的BGP ECMP
一些基于应用的负载均衡需要我们在不同的Tier3设备上宣告同样的网段。如果采取这样的部署手段,那么在其他设备上就会看到这些网段有着不同的AS_Path,但是同样的AS_PATH的长度。基于BGP选路策略,我们通过之前的CLOS和ASN的设计就实现了在这些路径上的负载均衡,因为除了AS_Path不同以外,其他的BGP选路属性都是一样的。
Weighted ECMP
我们还可以通过调整Weight(权重)值来对路径进行优化。我们可以通过“第三方下一条”注入带不同权重的路由来进行非均衡的流量分担,基于不同的链路权重可以分配不同的流量。注意这里的weight不是14条选路属性的第一条Cisco特有的权重值,因为那个只有本地有效而且只是优选路径。我们可以通过RFC draft-ietf-idr-link-bandwidth定义的Link Bandwidth Extended Community来实现。
一致性哈希
作者推荐使用一致性哈希(Consistent Hash)来解决在ECMP组里增加/删除下一条对流量的影响,这里就不展开讨论了。值得注意的是部署一致性哈希需要更多的硬件资源,比如TCAM。
路由收敛属性
这章将介绍路由收敛属性,作者提出可以通过部署支持BGP对等会话快速失效(BGP Fast Peering Session Deactivation),对应路径失效时RIB和FIB实时更新(timely RIB and FIB updates upon failure of the associated link)来实现亚秒级的收敛。
故障检测时间
通常的BGP要通过来反应链路/节点的失效。在此设计中,因为没有IGP,所以BGP Keep-alive(或者其他的keep-alive机制)和链路失效trigger就成为唯一的保护机制。
如果只通过keep-alive来触发失效进行链路保护,收敛时间通常很高,取决于time-out时间,但是一般也是秒级的收敛。但是很多BGP可以通过链路失效触发关闭BGP对等会话(BGP peer session)的功能。这样我们的收敛时间就取决于”link-down”事件而不是定期的keep-alive。现在数据中心里一般都用点到点的光纤连接,一般的检测时间都在毫秒级。
Ethernet链路可以做到更可靠的故障检测。有的可以通过CFM(Connectivity Fault Management),还有的支持BFD(Bidirectional Forwarding Detection, RFC5880)实现亚秒级的检测和通知BGP进程。但是这也需要额外的特性支持,和需求1冲突。
事件传播时间
在这个方案设计里,消除BGP MRAI(MinRouteAdvertisementIntervalTimer)的影响也被考虑进来了。在RFC4271中规定指定对等体在发送或者撤销路由过程中最少要间隔MRAI计时器(一般是可以配置的)来减少频繁更新带来的影响。当对等体完成路由更新后启用MRAI定时器,在这个时间内对等体不再发送更新或者撤销消息。所以当一个BGP speaker 由于路由失效,等待新的路径被邻居发送回来,并且loc-rib没有备选路径的时候,MARI计时器会造成很大的收敛延时。
在CLOS架构里,一般来说每个BGP speaker都有一个(比如某个tier 2到某个tier 3)或者N个路径(比如某个tier 2到某个tier 1)去往一个同样的prefix。这里2种情况会:
1.当某个tier 2到某个tier 3的链路失效时,由于没有备用链路,Tier 2设备会立刻发送一个withdraw给所有tier 1,所有被影响的tier 1收到以后可以立刻收敛计算。
2.当某个tier 2到某个tier 1失效,首先会计算出新的下一跳组(ECMP),如果这个path是之前选择的最佳路径的话,会通过update消息发送“implicit withdraw”。
CLOS扇型发散(fan-out)的影响
(关于fanout,相比扇出,可能我觉得这里扇形发散更好理解)
CLOS架构的fan-out,某些情况下很大程度上会影响”从上到下“的收敛时间,造成路由震荡。继续上一节的case 1:
1.当某个tier 2到某个tier 3的链路失效时,由于没有备用链路,Tier 2设备会立刻发送一个withdraw给所有tier 1
2.所有被影响的tier 1收到以后可以立刻收敛计算。
3.之后,所有的tier 1设备会向所有相连的tier 2(除了发起的那个tier 2)发送更新报文。
4.这些tier 2应该等所有tier 1发送完成以后再移除对应的路由
5.继续传播给tier 3设备。
在这个过程里,如果某些步骤1或者步骤3发送消息的设备由于某些原因延时了发送更新消息,那么就会造成更新消息分布过于分散,间隔好几秒。所以为了防止这种情况发生,BGP需要支持更新组(update group)。更新组定义了一组共享同样的”对外策略”的邻居,bgp speaker会同步的向这个更新组的组员发布更新消息。
最后作者还提出了在这个解决方案里不推荐使用”route flap dampening”来解决clos里的路由震荡。
故障影响范围
一个网络只有当所有被影响的设备都被通知了故障并且重新计算生成了RIB和FIB以后才能宣称自己收敛完毕。大型的故障影响范围就意味着更长的收敛时间,因为更多的设备需要被通知,从而造成网络的不稳定。这章主要介绍CLOS拓扑的BGP相比于链路状态协议,为何会减少故障影响范围。
BGP从行为上来说表现为距离矢量型路由,因为从本地路由器角度,它只把它认为的最佳路径发送给邻居。因此,有的故障可以被掩盖住,如果本地能立刻找到备选路径的话,此故障就不必通告给其他邻居。在最坏的情况下,数据中心中所有的设备要么彻底删除一个prefix,要么在FIB里更新ECMP组。但是很多故障并不会有如此大的影响范围。
1.Tier 2 和tier 1之间个链路故障:这种情况下,Tier 2只需要更新本地FIB,不需要告诉Tier 3设备,除非这个path是之前选择的最佳路径,Tier2会通过update消息发送“implicit withdraw”,而且这并不影响流量的转发。对于Tier 1来说,需要删除对应的Tier 2的prefix,更新ECMP,通知其他直连的Tier 2, 同样其他Tier 3也不需要被通知和收敛。
2.Tier 1设备故障:这种情况下,所有直连的Tier 2设备需要需要更新ECMP组,Tier 3设备同样不知情。
在多个prefixes需要在FIB中更新的情况,我们需要注意的是这些prefixes共享一样的ECMP组。因此,如果系统中支持”分层FIB(hierarchical FIB)“,只需要做一次改动就可以。分层FIB(hierarchical FIB)意思就是下一跳的信息和prefix查找的表是分开的,因此只需要将下一跳通过指针指向对应的下一跳的分表,改动下一跳分表就可以快速更新FIB。(RFC draft BGP Prefix Independent Convergence)
虽然使用路由汇总可以进一步减少故障影响范围,但是之前我们也提到了会造成路由黑洞。尽管这里列举了一些影响范围不大的情况,我们仍然会面对最坏的情况:所有的设备控制平面都需要收敛,这也是CLOS的属性之一,跟EBGP的选择没有关系。
微环路
一般Tier 2设备都有会默认路由指向Tier 1设备。当一个Tier 2完全失去某个Tier 3后面的prefix而Tier 1没有更新这些prefix时候,就会造成微环路(Routing Micro-Loops)- Tier 1发给Tier 2, Tier 2通过默认路由丢回给Tier 1,直到Tier 1更新路由表。
为了减少这种情况的影响,我们可以配置一个静态路由去把这些报文“丢掉”或者指向null,这个静态路由需要比默认路由稍微“详细”一点。对于Tier 2设备来说,这可以是一条汇总路由,覆盖了所有的下联的Tier 3设备上的服务器网段,对于Tier 1设备来说,应该覆盖所有数据中心里的服务器网段。这个静态路由只有从网络收敛期间到学到新的更详细的路由这段时间内有效。
总结
到这里,这篇RFC 7938的介绍差不多就结束了,后面还有1章可选的设计,将来有可能介绍给大家。在写作的过程中通过不断的阅读RFC和参考资料让我对这篇设计方案有了更深的理解,也希望能和感兴趣的工程师探讨交流。后续的文章可能还会以Facebook为背(xue)景(tou)讨论Segment routing在大规模数据中心里的应用,敬请期待。
章节回顾:
如何像Facebook一样构建数据中心 – BGP在大规模数据中心中的应用(1)
如何像Facebook一样构建数据中心 – BGP在大规模数据中心中的应用(2)
标签:数据中心,ECMP,BGP,Tier,Facebook,链路,tier,路由 来源: https://www.cnblogs.com/zy09/p/16520868.html