论文整理:《基于着色Petri网的无人机侦察规划》
作者:互联网
整理:《基于着色Petri网的无人机侦察规划》
- 无人机任务规划可分为 路径规划、战术规划、航迹规划,本文侧重于对 战术规划 的设计
传统存在问题 and 本文提出方案
- 传统的 Petri 网不能准确模拟战术规划中资源及任务正负效应建模
- 采用
着色Petri网进一步设计网间结构,利用总体目标管理图以及变量管理图实现了消耗类资源以及多目标任务规划中的正负效应模拟
方案各环节浅析
着色Petri网
基于Petri网上,主要对托肯以及有向弧进行了扩展:
- 每个标记附加一个颜色数据值(可以用来表示消耗类资源)
- 对各条有向弧定义标记类型和通过条件
- 对变迁定义变迁表达式函数,对触发条件进行约束。
因为暂时还没系统学习过离散数学,并不能非常好的理解形式化定义的各个部分,但大致意思还是能明白的
计划-目标层次分解
使用树结构对计划和目标进行分解和描述
- 目标/子目标节点可以包含多个计划节点
实现任一计划,都可完成该目标
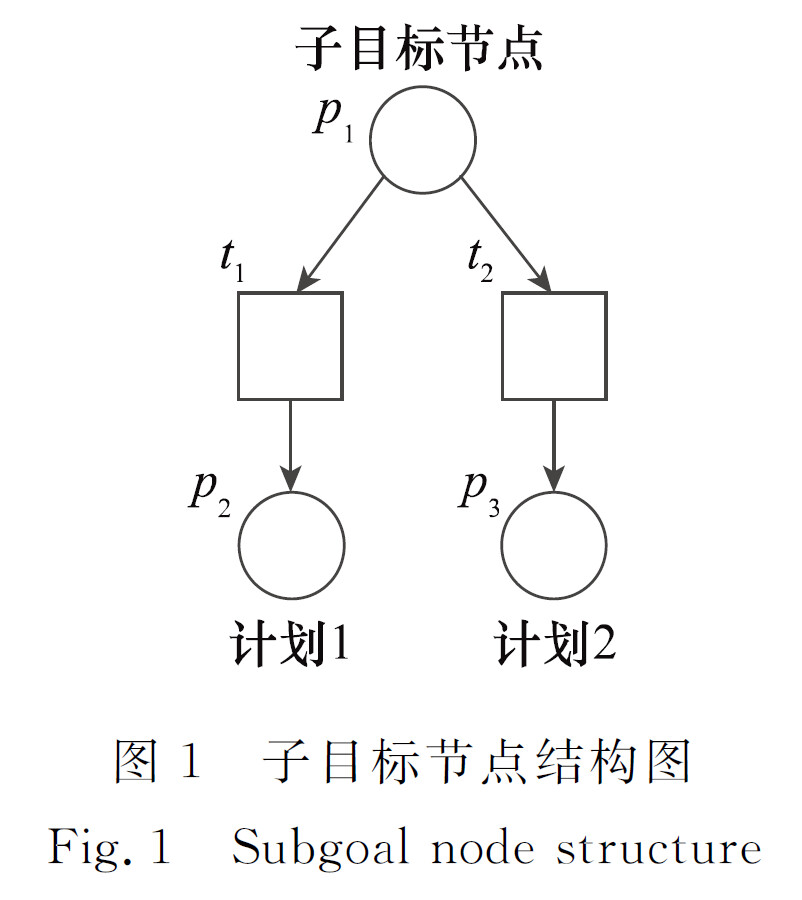
子目标节点的托肯可以通过任意一个变迁转移到某一个计划结点
个人理解:要完成一个计划,可以分解为完成多个目标,例如实现一个战略计划,则需要达成多个目标
- 计划节点可以包含多个子目标节点
实现所有子目标,才可以完成该计划
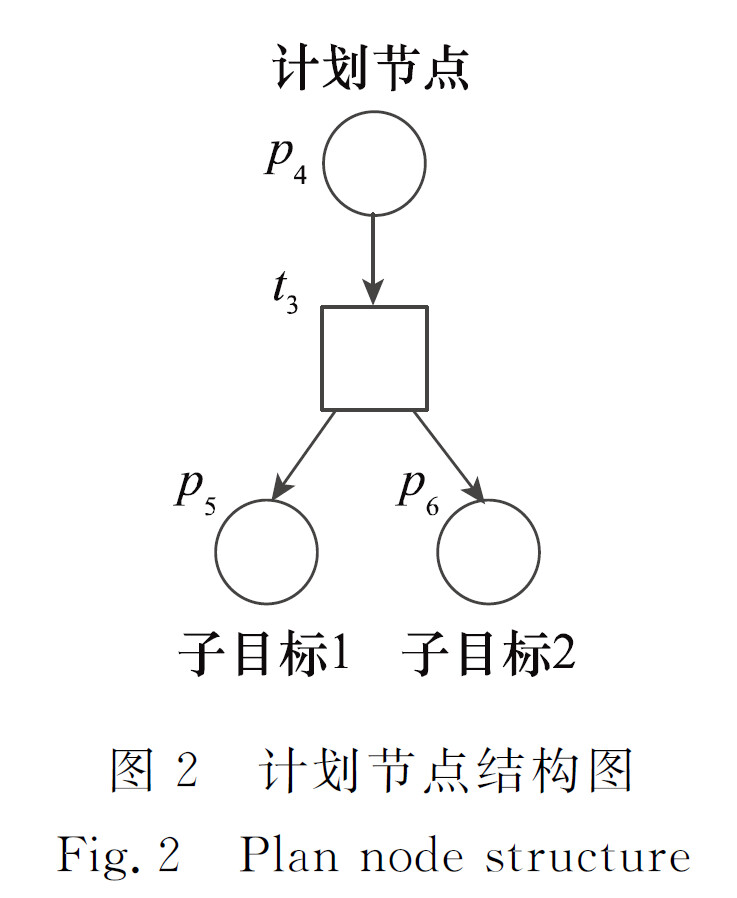
计划节点的托肯会转移到各个子目标结点
个人理解:要完成一个目标,可以分解为完成多个计划中的一个,比如可以用PlanA,PlanB来达成一个目的。
消耗类资源规划建模
基于着色技术,通过资源信息总览实现对各类资源和资源消耗总量的记录,借此可以判断某目标能否安全完成(安全性)以及资源消耗总量情况(最优性)
- 消耗类资源模型
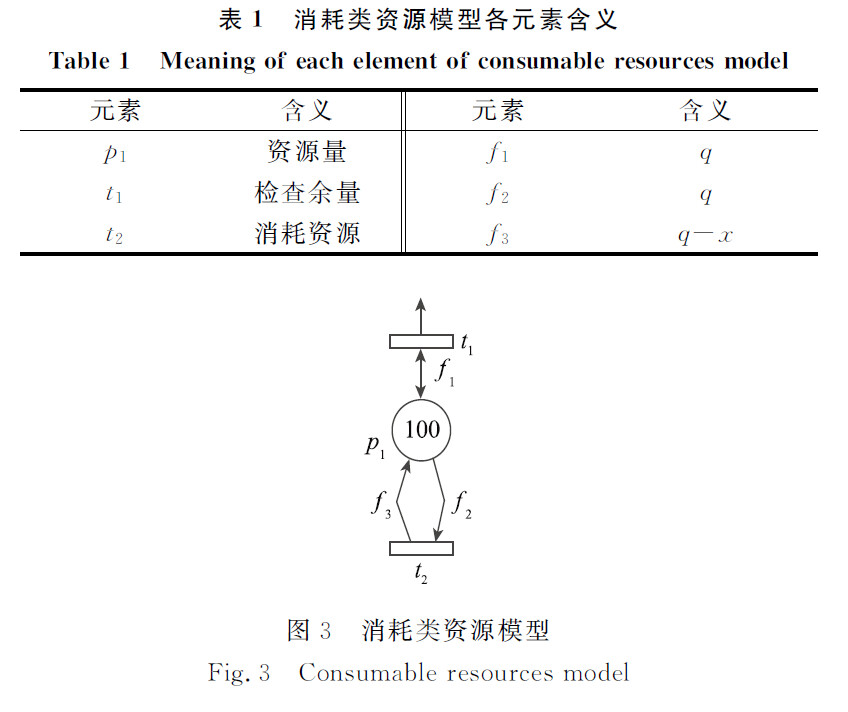
阅读笔记:
对于 t1,当满足 q >= x 时,就进行变迁,从 P1 走 f1 给予 t1 q 个资源,进行检查后,再走 f1 返还给 P1 q 个资源。 对于t2,当满足 q >= x 时,就进行变迁,从 P1 走 f2 给予 t2 q个资源,再走 f3 从 t2 给予 P1 q - x 个资源 另外,双向箭头一般代表着比较、判断,尤其是在后面的 "与资源信息总览比较" 中
-
最优计划推理结构图
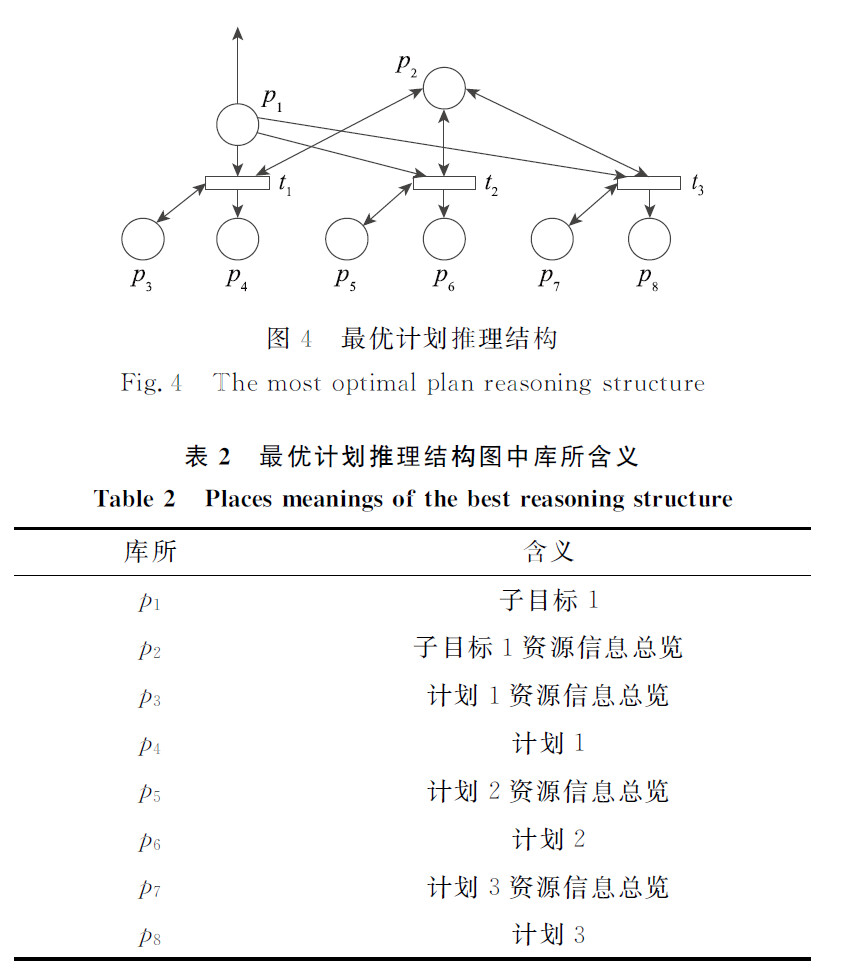
阅读笔记:
先进行双向指向的变迁(用于比较和判断资),若ok,那么再继续进行最优计划的那条路进行变迁
- 基于资源信息总览的任务目标推理
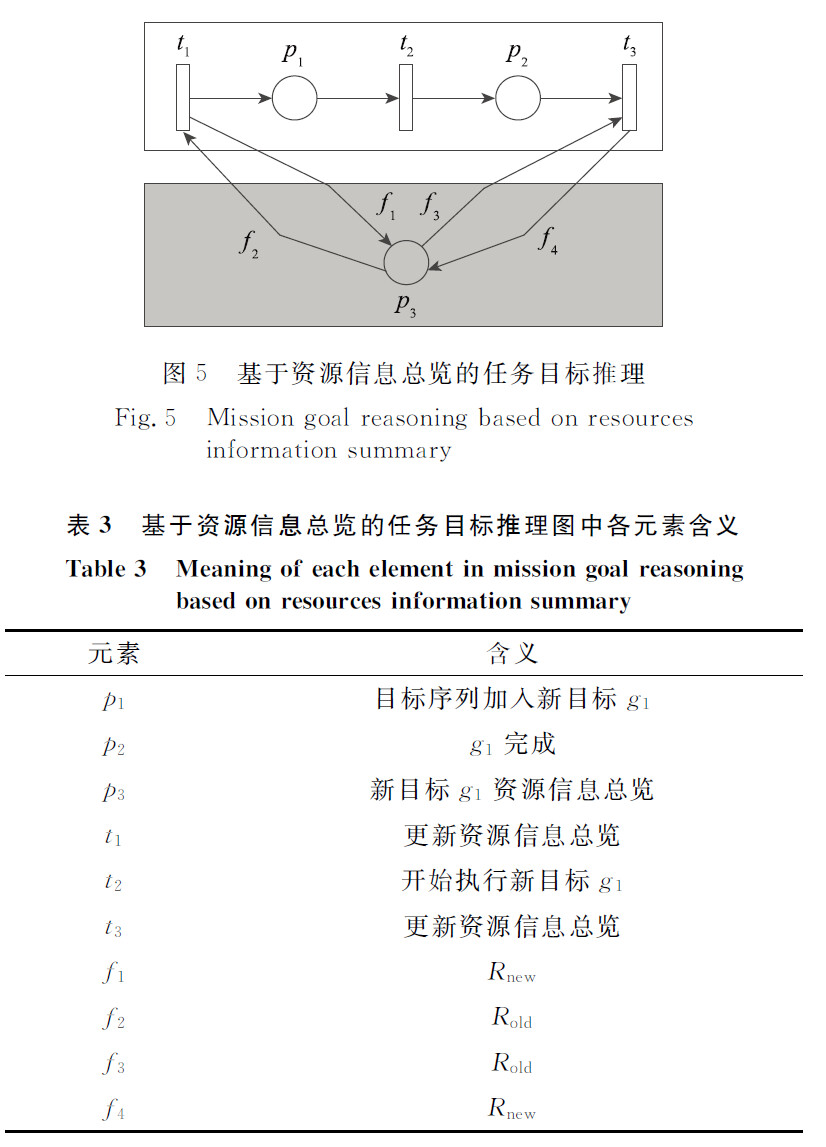
阅读笔记: 首先 有向弧 指向 资源信息总览的库所 则一定是 R_new,因为是要更新资源;而返回回去的时候则是把原资源返回回去,所以是 R_old。 另外第一次更新,会先更新新目标的资源消耗量(第一类),同时判断执行该目标的安全性;接着执行完该目标后再次更新,此时更新执行该目标后的资源消耗总量(第二类)。 中间执行该目标的过程很好理解,不知道这里想的对不对。 图五的中的计划执行前会先获取计划的资源消耗信息来更新资源信息总览,随后再执行计划,计划结束后又会再次更新。
正效应规划建模
-
正效应:对于拥有相同触发条件的多个目标,我们只需只执行一次对应的计划。
- 可以避免大量的重复工作、资源消耗
- 正效应推理是对目标的触发条件判断是否已经满足
-
正效应推理模型
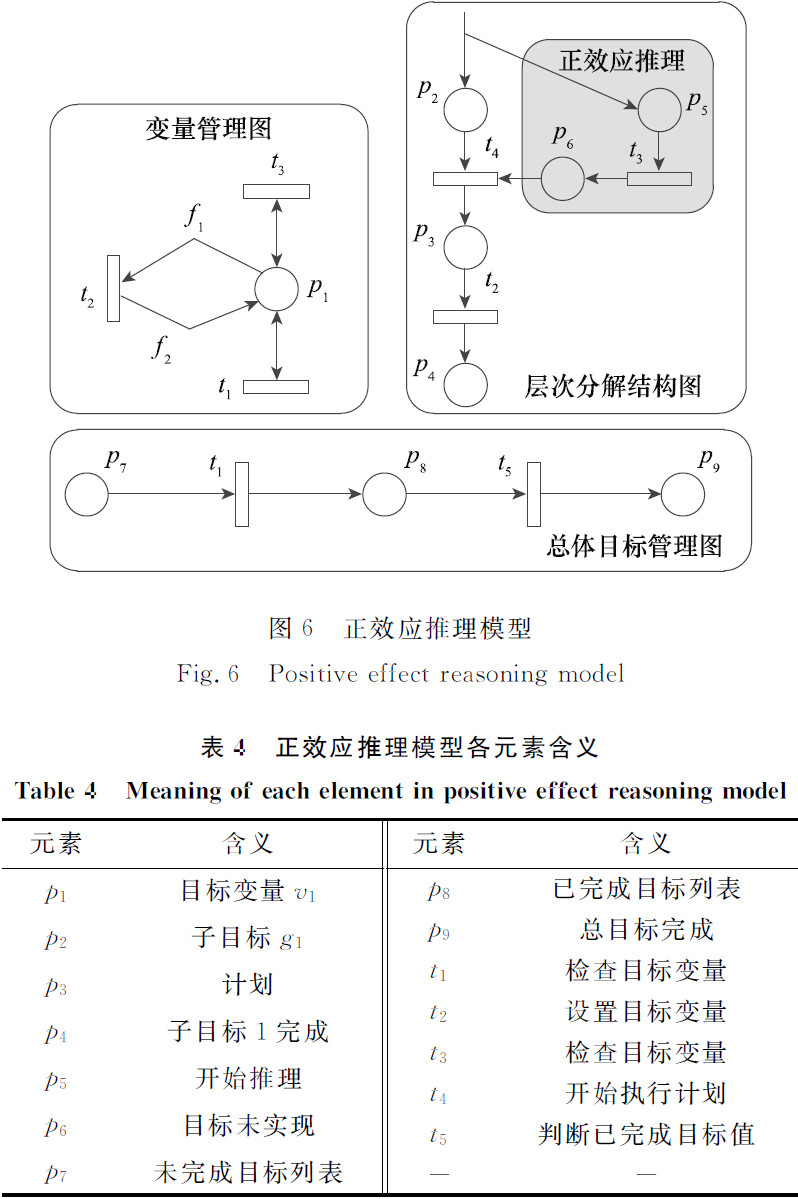
阅读笔记: 对于一个子目标,先传递给 P2,P5 托肯,P5 开始的正效应推理判断此时目标是否已经达成了。此推理过程会触发 变量管理图中的变迁 t3,如果目标未达成,则 P6 获得 托肯,接着开始执行计划。开始执行后,会通过触发变迁 t2,来给P1设置目标效果值,接着会触发 t1,用来更新总体目标,P7 中的这一个新的满足条件的托肯便会移入 P8,当 P7 中所有托肯移入 P8,则会触发 t5,最终到达 P9,总目标达成。
负效应规划建模
-
负效应:对于3个及3个以上的目标,目标的触发条件之间存在着因果、阻碍关系。通过负效应推理,正确安排事件的执行顺序。
- 达到目标的完全实现,避免资源浪费
- 本文负效应推理的实现基于
保护托肯
-
负效应推理模型
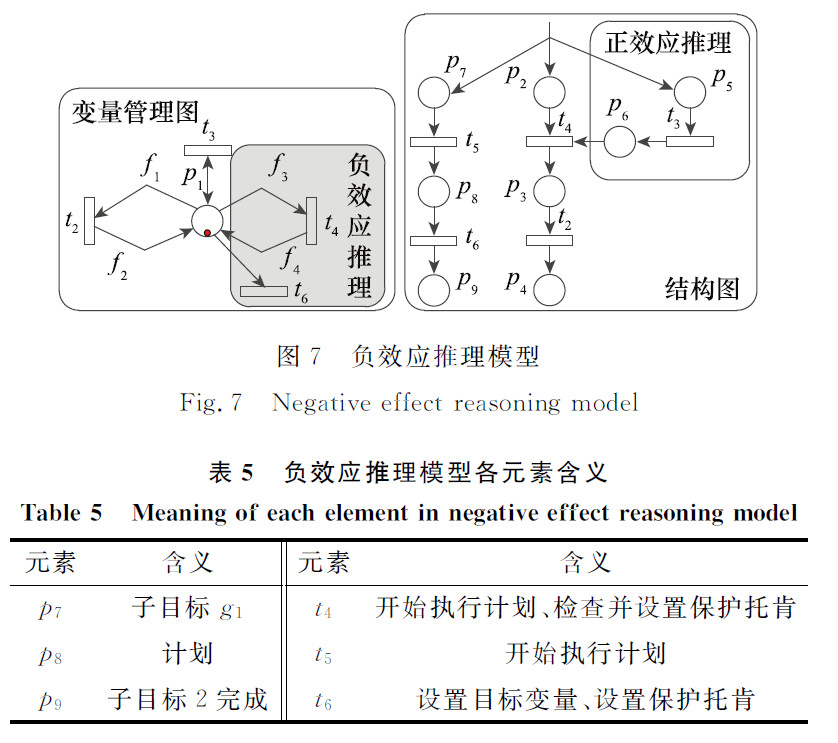
阅读笔记:
当一个目标执行时,会对库所 P1 添加保护托肯。只有当该目标执行完成后,才会移除保护托肯。 当有保护托肯时,别的目标无法更改库所 P1 值
方案的验证
无人机侦察战术规划
- 侦查任务层次分解结构图
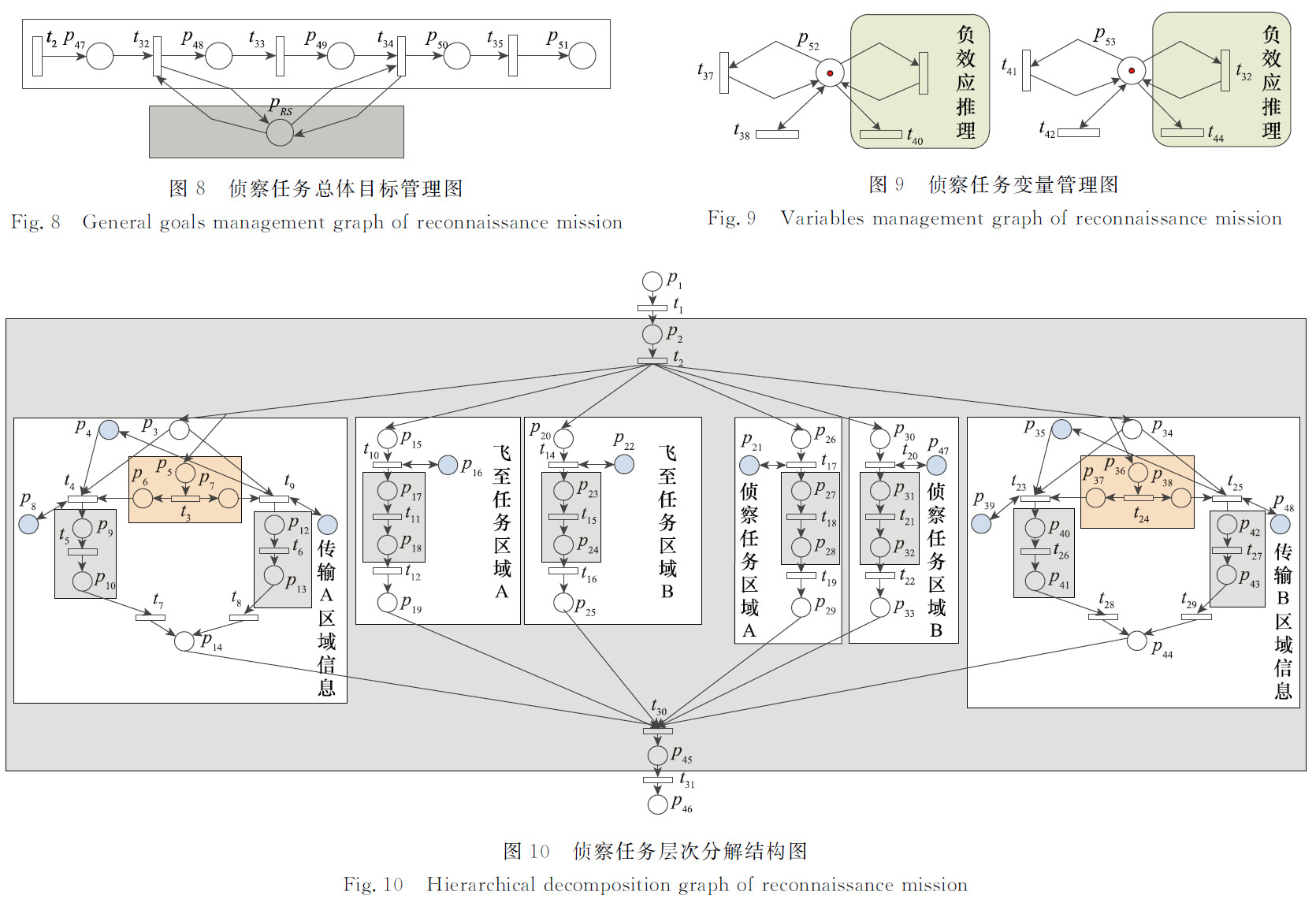

流程分析(照搬阅读笔记的):
1、首先总目标下分为很多个小目标,对于这些小目标有依次执行的顺序,①飞至区域 X,一定在传输 X 区域信息之前 ②飞至一个区域时不能飞往另一个区域(保护托肯)③飞至一个区域时可以传输另一个区域的信息(如果去过的话)
2、在准备开始执行一个子目标时,会先触发相关变迁,随后 t32 触发,会将获取到的消耗量信息更新给资源信息总览(同时判断执行安全性),以及添加保护托肯(飞往任务),这些变迁是 t32 关联的
3、在结束一个子目标后,与(2)相同,应该也会触发相关的变迁,随后将 t34 触发,更新资源信息总览、设置保护托肯,当然还会触发 t37 来更新消耗类资源
4、传输信息的任务进去时会先执行正效应推理,来判断是否已完成,以防浪费资源,但这里不存在正效应
5、本任务中的负效应主要是飞至任务区域A和侦查任务区域A时不能飞往任务区域B,在结束侦查A的任务后会移除保护托肯,而在开始飞往一个区域的任务执行时会添加保护托肯
6、总体上,每完成一个子目标,P50 就会获得一个托肯,当获得 6 个托肯时,就会触发一系列表示最终任务完成的变迁和库所
PS:
1、橙色部分是正效应推理 2、传输区域的任务部分,目标下有两个计划,一个计划是传输工作,另一个是直接返回基地 一般会优先执行传输计划,无论是飞往B地(保护托肯制约),还是未执行飞往B地(因为根据燃油消耗量选择最优计划)
个人总结
-
文章方面
- 在阅读图表的时候,文章没有对所有标记都写上含义,导致有些地方可能是个人理解,难免会产生偏差
- 在负效应规划建模方法里,有一句话个人觉得可能是写错了
图7中,P2库所与P7库所表示的子目标g1与g2同属于一个计划 - 文章脉络清晰,对现存问题和改进方案,包括方案具体缓解都进行了详细的分析,配以图表;同时应用相关案例对方案进行了验证;最终进行总结,并提出研究缺陷
不能表达任务执行的时间因素和 未来研究方向将分层及时延概念引入结构图。
-
个人方面
- 作为第一次阅读学术论文,确实存在大量的前置概念不了解,尤其是离散数学只有算法图论的一些概念,没有系统学过。借此补上了相关知识点
Petri Net基础、部分离散数学的符号意义 - 对学术论文写作有了大致的了解,包括其框架、内容等
- 增加了对Petri网的相关研究的了解
- 作为第一次阅读学术论文,确实存在大量的前置概念不了解,尤其是离散数学只有算法图论的一些概念,没有系统学过。借此补上了相关知识点
标签:托肯,子目标,目标,着色,计划,Petri,无人机,资源 来源: https://www.cnblogs.com/yramvj/p/16505457.html