#章节八:爬取知乎文章
作者:互联网
章节八:爬取知乎文章
目录你造吗,今天是个大喜的日子!来到这儿,就意味着你爬虫已经入门啦!
在这个重要又喜悦的日子里,我们就干三件事:回顾前路、项目实操、展望未来。
回顾前路,是为了复习1-7关所学的知识。项目实操,是通过写一个爬虫程序把所学的知识用起来。展望未来,是预告一下我们之后会遇到的风景。
马上开始吧~
1. 回顾前路
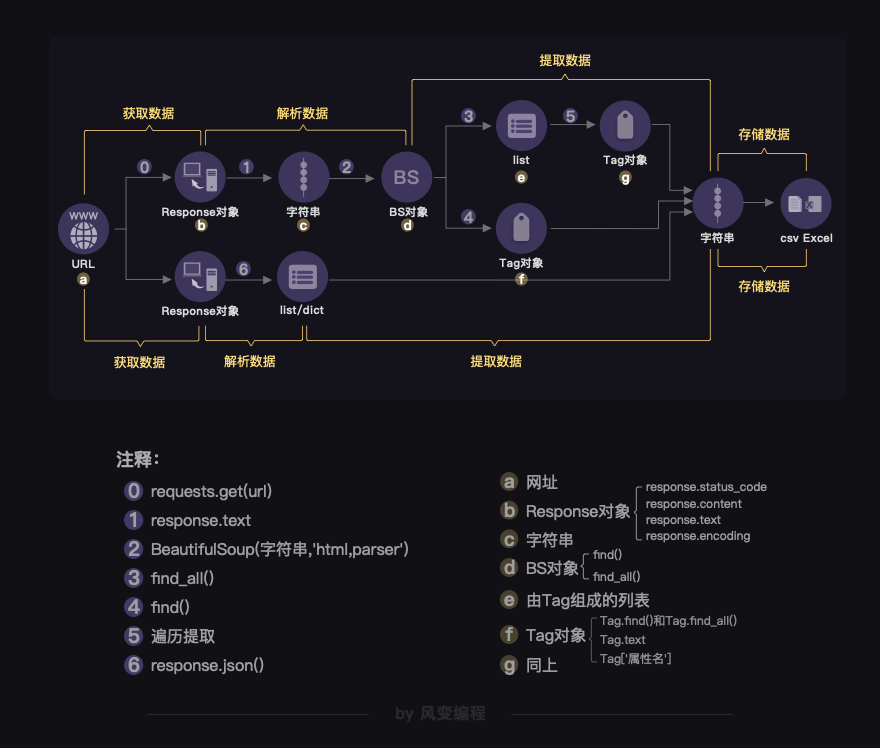
在前面,我们按关卡学了好多好多知识。而这么多的内容,我们用【项目实现】和【知识地图】两张图就能说清。
【项目实现】: 任何完成项目的过程,都是由以下三步构成的。
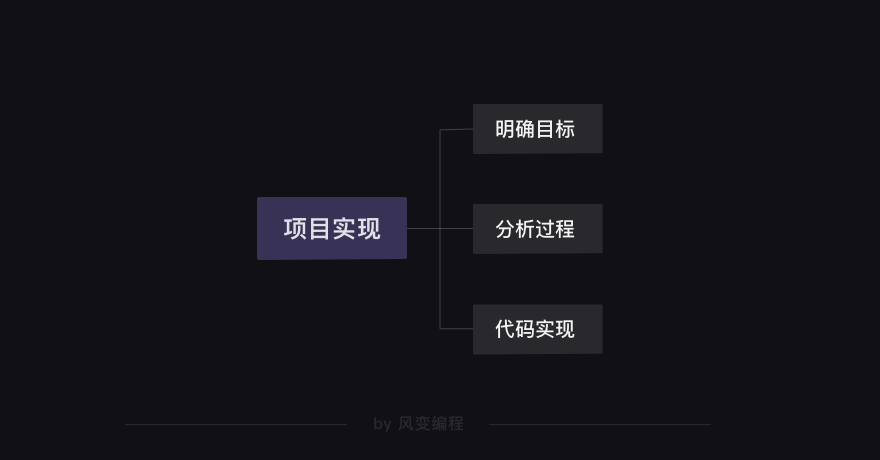
先需要明确自己的目标是什么,然后分析一下如何实现这个目标,最后就可以去写代码了。
当然,这不是一个线性的过程,而可能出现“代码实现”碰壁后然后折返“分析过程”,再“代码实现”的情形。
接下来是【知识地图】:前面6关所讲的爬虫原理,在本质上,是一个我们所操作的对象在不断转换的过程。
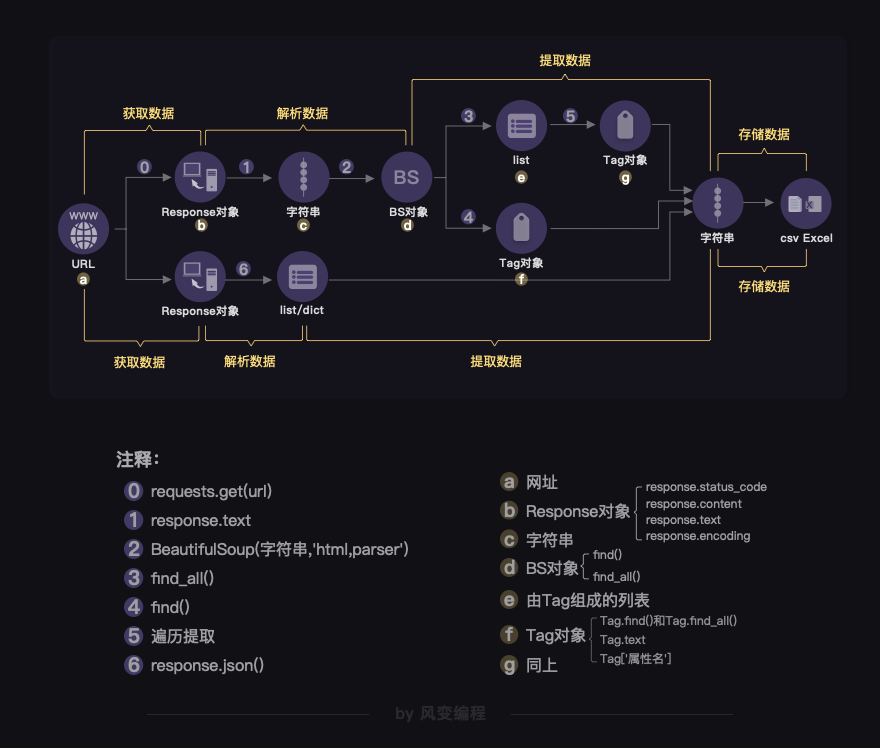
总体上来说,从Response对象开始,我们就分成了两条路径,一条路径是数据放在HTML里,所以我们用BeautifulSoup库去解析数据和提取数据;另一条,数据作为Json存储起来,所以我们用response.json()方法去解析,然后提取、存储数据。
你需要根据具体的情况,来确定自己应该选择哪一条路径。
也可以参考图片上的注释,帮助自己去回忆不同对象的方法和属性。不过,老师还是希望你能把这个图记在心里。
好啦,1-7关的内容就梳理完成啦~
接下来是项目实操,这是今天的重头戏。
2. 项目实操
我们会按照刚刚提过的项目三步骤来,首先是明确目标。
2.1 明确目标
为了让大家能把前面所学全都复习一遍,老师为大家准备了一个项目:爬取知乎大v张佳玮的文章“标题”、“摘要”、“链接”,并存储到本地文件。
之所以选这个项目,是为了让大家能把前面所学全都复习一遍。
知道目标后,就可以【分析过程】了。
2.2 分析过程
张佳玮的知乎文章URL在这里:https://www.zhihu.com/people/zhang-jia-wei/posts?page=1。
这是我做这个项目时,网站显示的内容。
点击右键——检查——Network,选All(而非XHR),然后刷新网页,点进去第0个请求:post?page=1,点Preview。
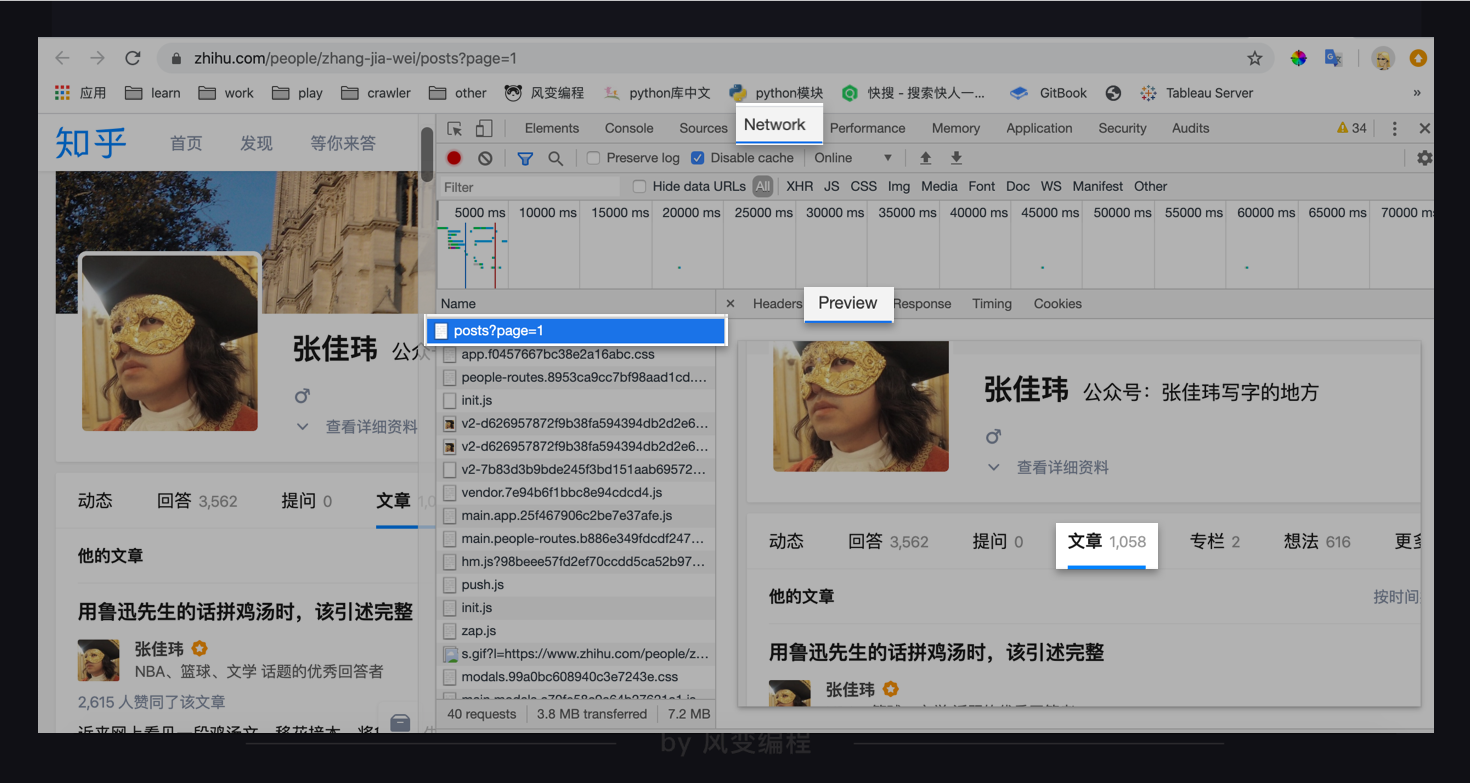
发现有文章标题,看来数据是放在HTML里。
那么,走的应该是【知识地图】里上面那条路径:
那好,就可以去观察一下网页源代码了,我们点回Elements。
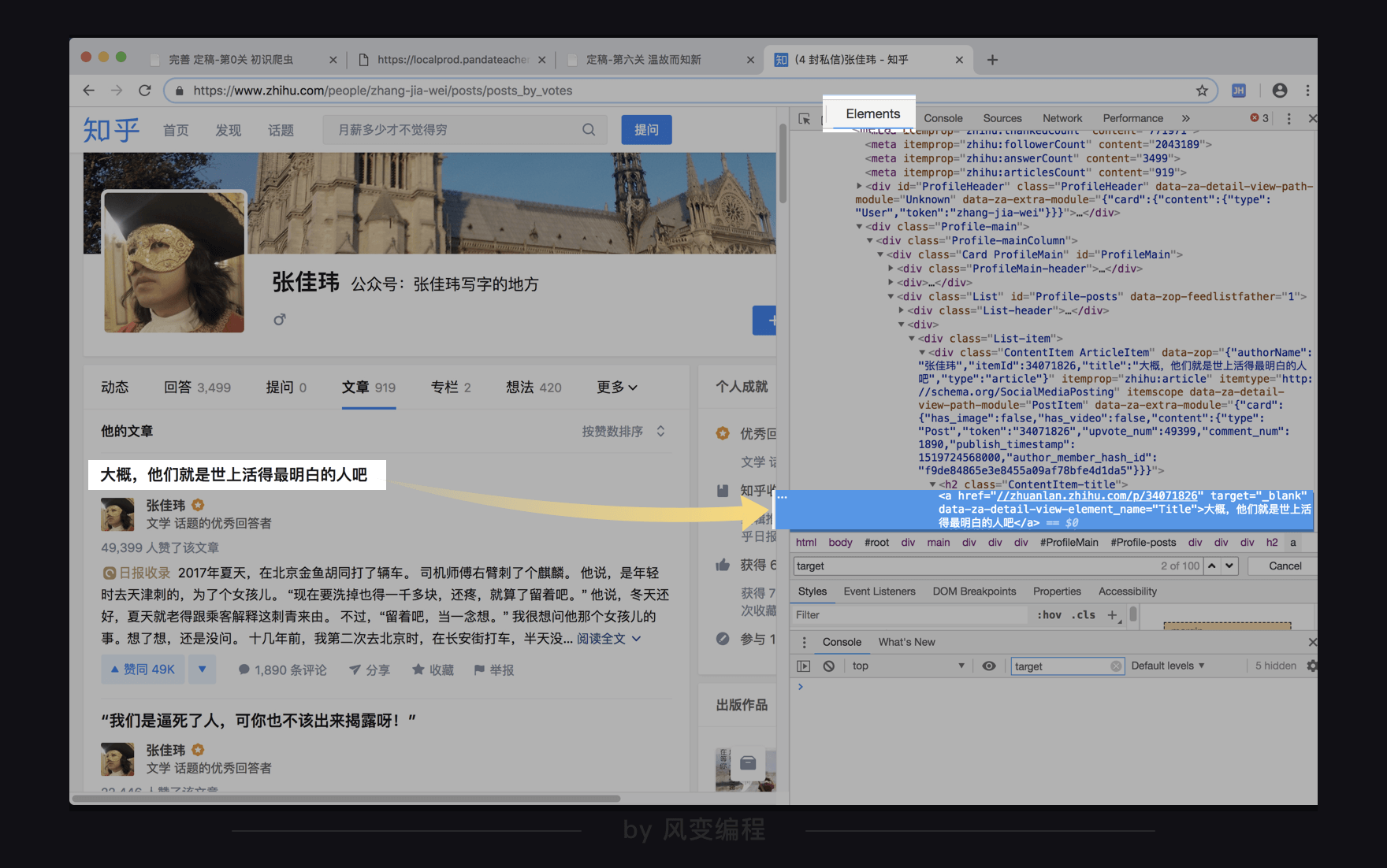
上图左边的文章标题对应的就是上图右边的a元素里面的文本“大概,他们就是世上活得最明白的人吧。”还可以看到在<a>标签里面,还有属性target="_blank",和data-za-detail-view-element_name="Title"。
对于target="_blank"属性,我们按下ctrl+f去搜索属性名target或属性值"_blank":
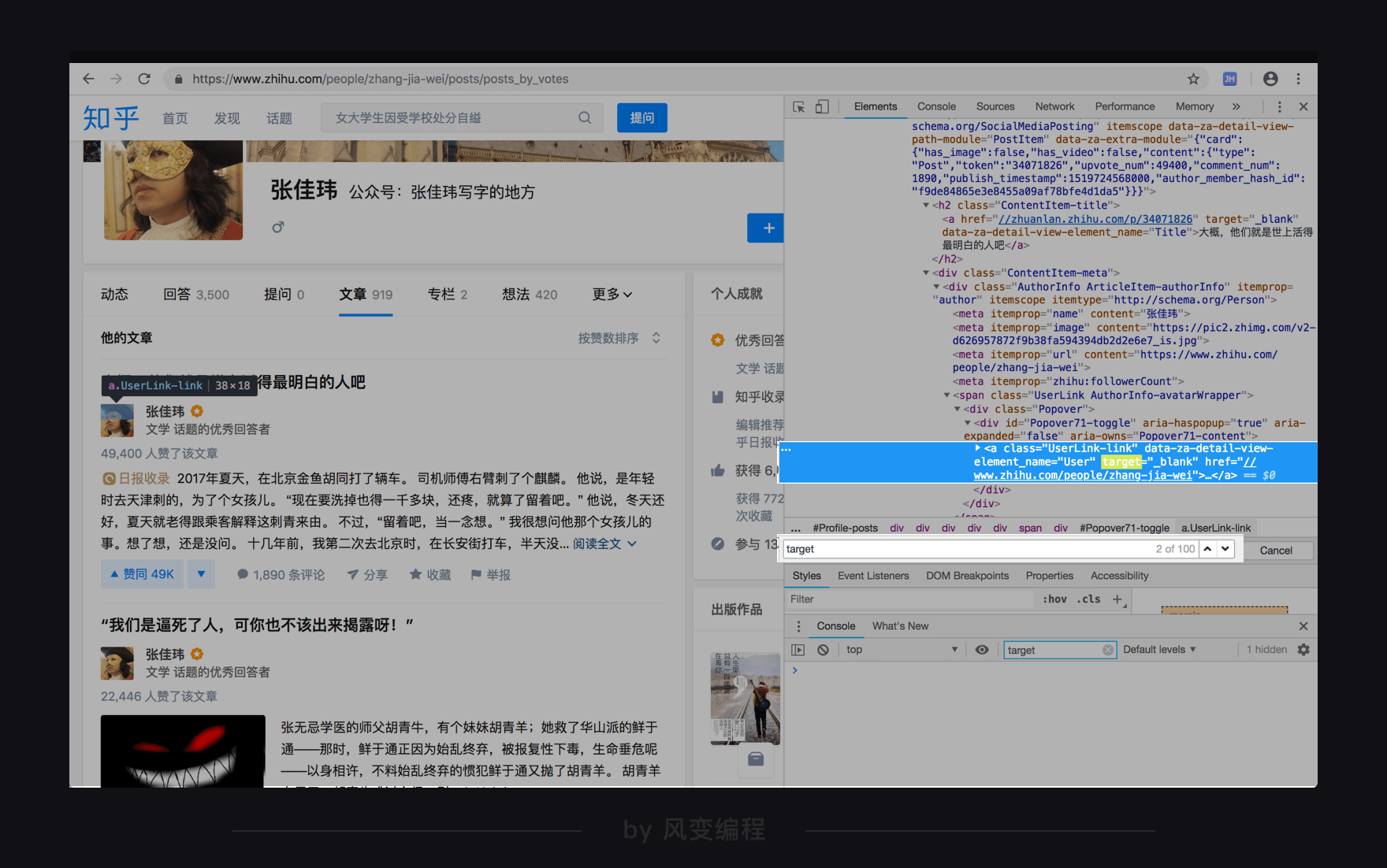
用上下箭头翻看一下搜索结果,发现这个target属性并不能帮我们精准地定位到文章标题,所以排除使用这个属性。
事实上超链接标签<a>的target属性指示的是在哪里打开跳转的目标网页,"_blank"表示每点击一次(超链接)打开一个新窗口。从搜索结果看,显然需要这个指示的不止文章标题。
而对于另一个属性data-za-detail-view-element_name="Title",属性值"Title"倒是在疯狂明示自己是个“标题”,但属性名如此freestyle,应该是由知乎的开发人员自定义命名,并不是html语法里标准的属性名,BeautifulSoup可能不识别。所以,我们不推荐使用。
有没有更好的选择呢?我们把视野稍微放宽(一点点):
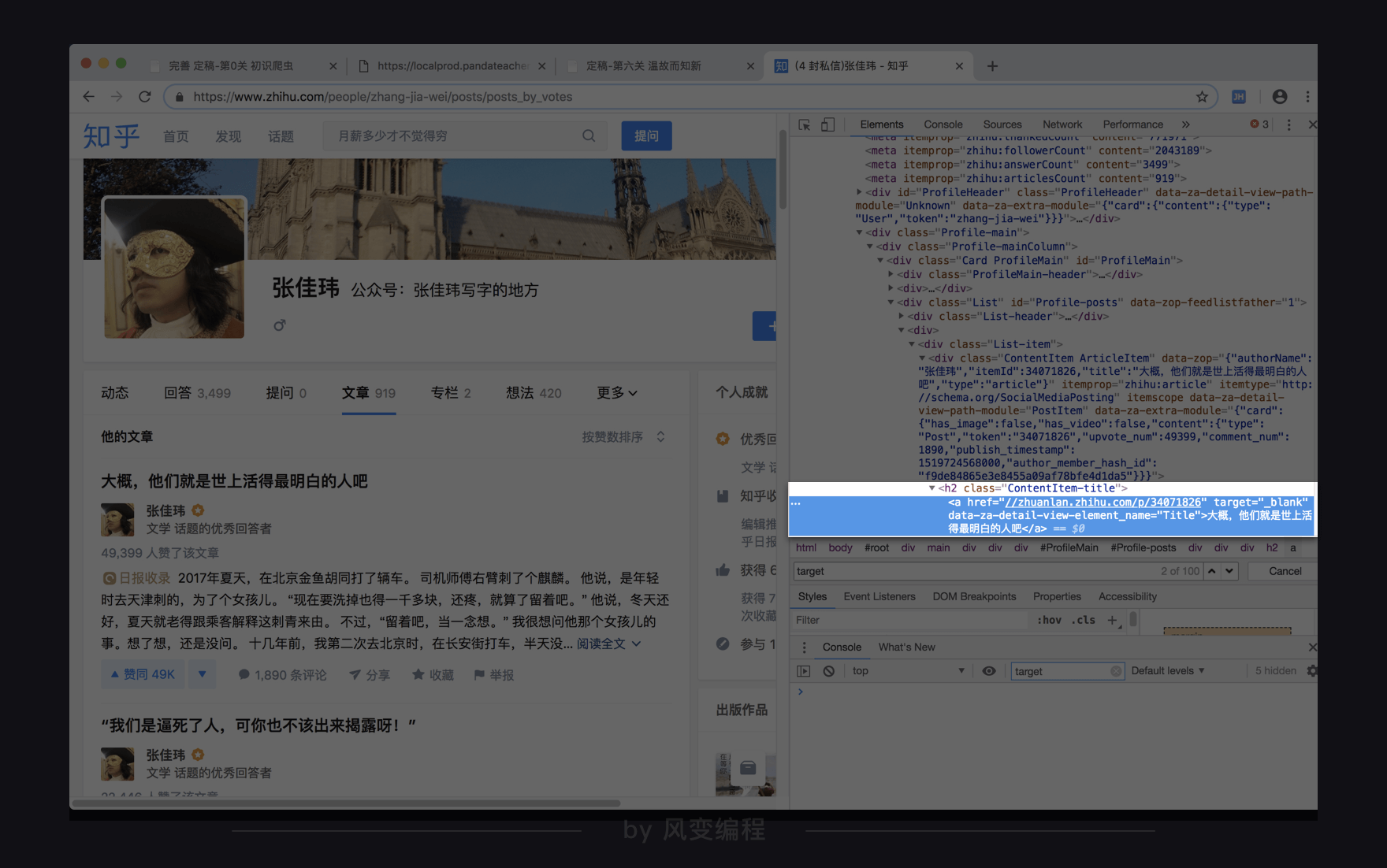
你会发现,这个<a>标签的上一个层级是<h2>标签,并且有属性class="ContentItem-title"。仍然用ctrl+f搜索属性值“ContentItem-title”,发现这个属性可以帮我们精准定位目标数据,可以用。
到这里,我们的思路也差不多清晰起来。
获取数据——用requests库;解析数据——用BeautifulSoup库;提取数据——用BeautifulSoup里的find_all()方法,翻页则要观察第一页,到最后一页的网址特征,写循环;存储数据——用csv或openpyxl模块都可以。基本思路就应该是这样。
好,这就结束了分析过程,接下来就是敲代码啦。
2.3 代码实现
别一上来就整个大的,我们先试着拿一页的文章标题,看看能不能成功。
请阅读下面的代码,然后点击运行:
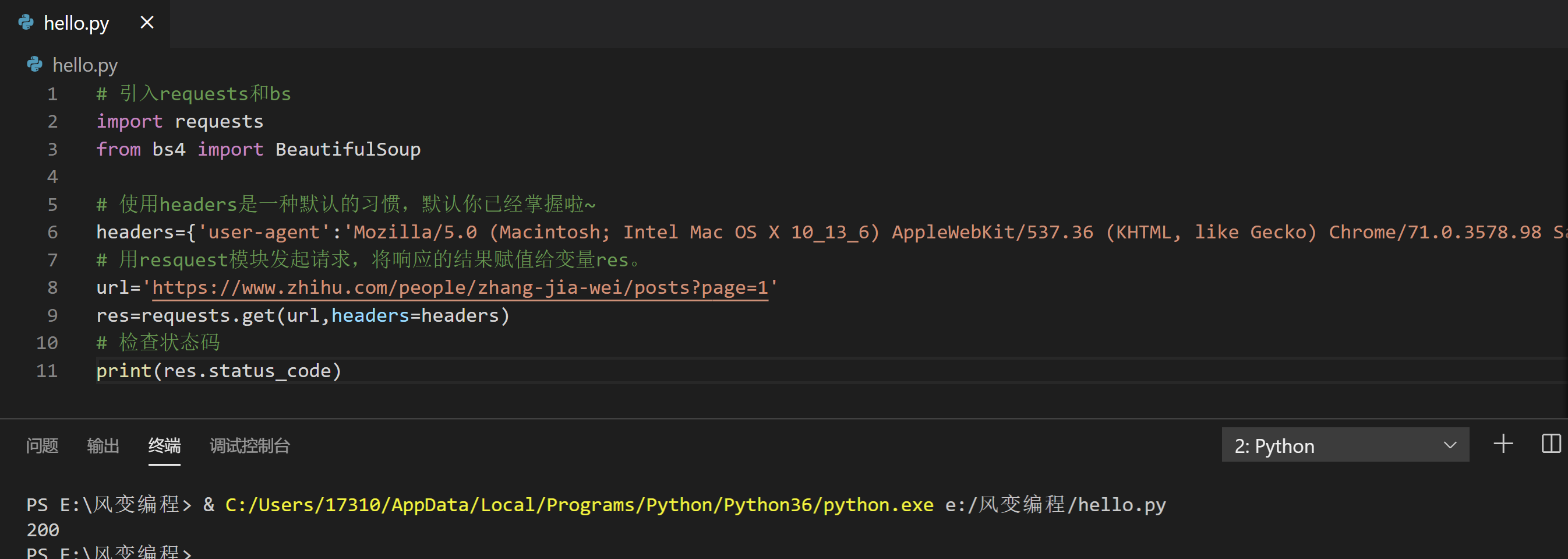
# 引入requests和bs
import requests
from bs4 import BeautifulSoup
# 使用headers是一种默认的习惯,默认你已经掌握啦~
headers={'user-agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
# 用resquest模块发起请求,将响应的结果赋值给变量res。
url='https://www.zhihu.com/people/zhang-jia-wei/posts?page=1'
res=requests.get(url,headers=headers)
# 检查状态码
print(res.status_code)
发现状态码显示200,表示请求成功,放心了,可以继续往下。
请阅读下面的代码,然后点击运行:
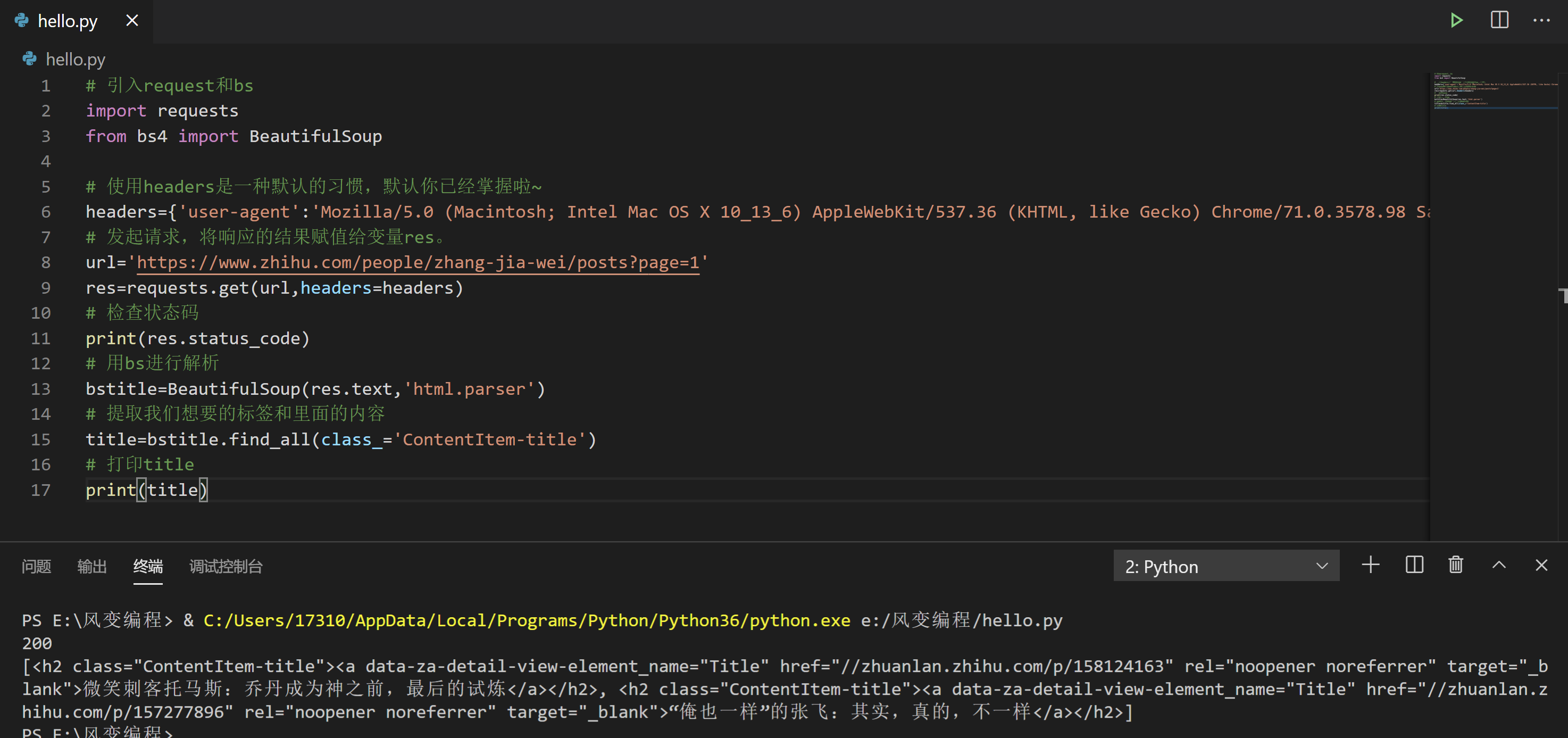
# 引入request和bs
import requests
from bs4 import BeautifulSoup
# 使用headers是一种默认的习惯,默认你已经掌握啦~
headers={'user-agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
# 发起请求,将响应的结果赋值给变量res。
url='https://www.zhihu.com/people/zhang-jia-wei/posts?page=1'
res=requests.get(url,headers=headers)
# 检查状态码
print(res.status_code)
# 用bs进行解析
bstitle=BeautifulSoup(res.text,'html.parser')
# 提取我们想要的标签和里面的内容
title=bstitle.find_all(class_='ContentItem-title')
# 打印title
print(title)
见鬼了,为啥只有两个文章标题?
看起来是碰壁了,但遇上问题别慌,先来做个排查,使用 res.text 打印一下网页源代码。请阅读下面的代码,然后点击运行。
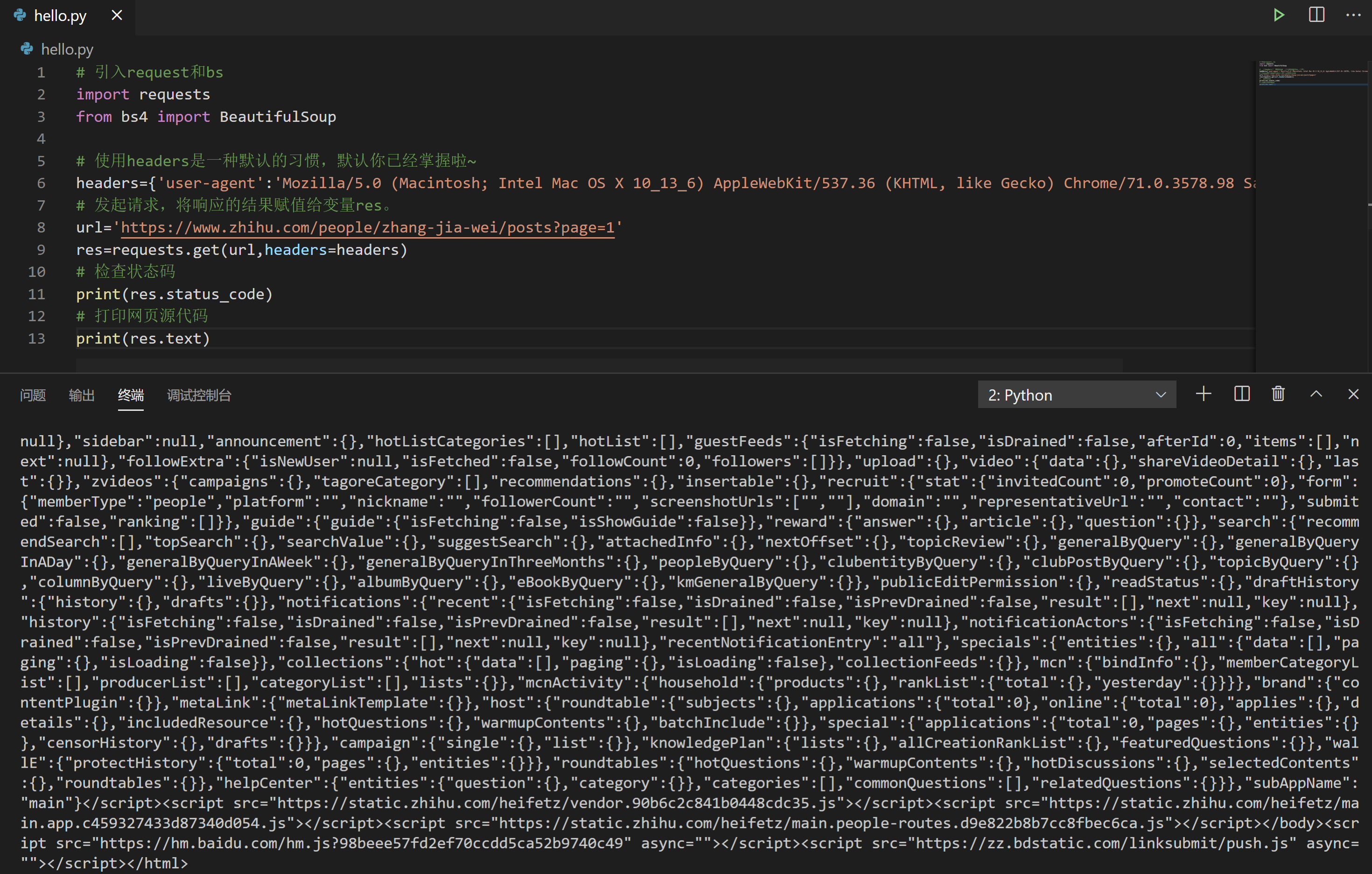
# 引入request和bs
import requests
from bs4 import BeautifulSoup
# 使用headers是一种默认的习惯,默认你已经掌握啦~
headers={'user-agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
# 发起请求,将响应的结果赋值给变量res。
url='https://www.zhihu.com/people/zhang-jia-wei/posts?page=1'
res=requests.get(url,headers=headers)
# 检查状态码
print(res.status_code)
# 打印网页源代码
print(res.text)
打出来之后,我们把第一页的最后一篇文章的标题“出走半生,关山万里,归来仍是少女心气”在这个网页源代码里面搜索,呵呵,是搜不到的。
标签:章节,10,知乎,res,爬取,headers,print,requests,data 来源: https://www.cnblogs.com/ywb123/p/16412694.html