数据不均衡问题
作者:互联网
非均衡数据处理--如何评价?
什么是非均衡数据?
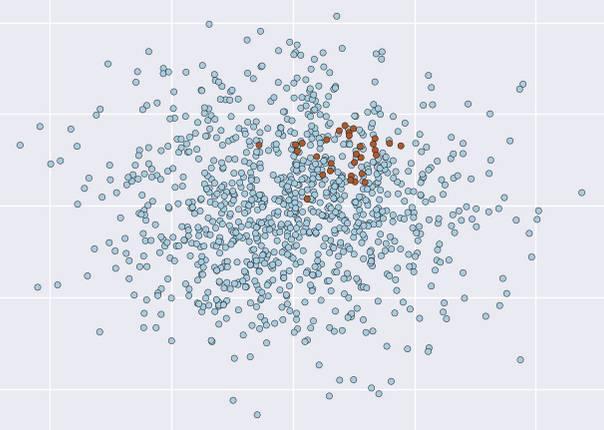
这个问题很直观, 就是样本中数据的不同类别的样本的比例相差很大, 一般可以达到 9:1 或者更高。 这种情况其实蛮常见的, 譬如去医院看病的人,最后当场死亡的比例(大部分人还是能活着走出医院的, 所以要对医生好点)。 或者搞大数据的人员中男女比例。再或者, 生长线上的正品和次品。 如下图就是, 两种样本非常不成比例, 就失衡了(Imbalanced/unbalanced) 。
为什么非均衡是个大问题?
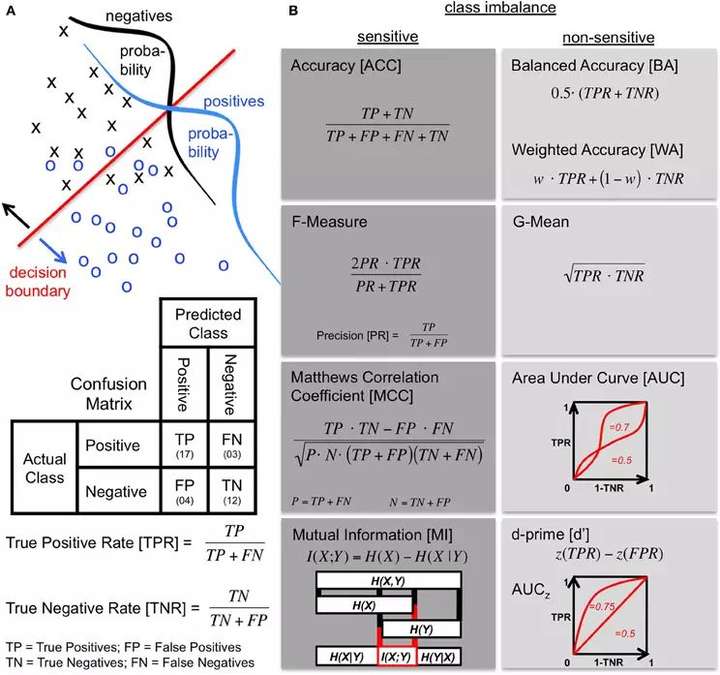
主要的原因就是非均衡影响到了分类算法的效果。是怎么影响的呢? 首先我们看一下如何评价一个分类算法。 一般来说会用到Confusion Matrix。
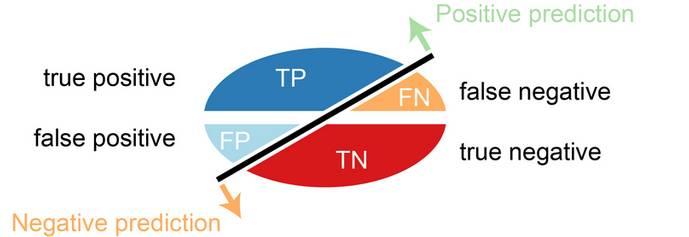
一般来说,一个分类器要正确率高。 那么正确率(Accuracy,ACC)是什么呢?

但是如果是非均衡的情况下, 如果选择绝对分类器(absolute classifier), 简单全部判别成主要(Major)的类别, 那么 (TP+TN)/ (P + N) = P / (P + N) > 90% 。
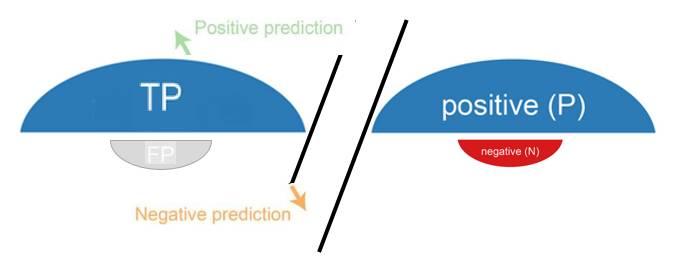
另外一个原因, 因为目前大部分分类器是按平衡数据的正确率来进行优化的, 那么很容易忽视较小(Minor)的类别, 使得分类器对Minor失效。
因此两个问题放在我们面前了:
1): 如何评价非均衡数据分类效果。
2): 如何学习到一个适合分类器。
非均衡数据分类的评价?
有个最早在自信号处理领域发明, 但是生物医学领域发扬光大的标准叫受试者操作特征曲线 Receiver operating characteristic (ROC) curve的标准。受试者, 一听就像药物测试的对象。 对的,这正是前面提到在生物医药领域, 非均衡情况特别普遍, 这也是ROC curve标准广泛应用的原因吧。
ROC 曲线是坐标系上的曲线, X轴是FPR (Specificity), Y轴是TPR(Sensitivity / Recall)。
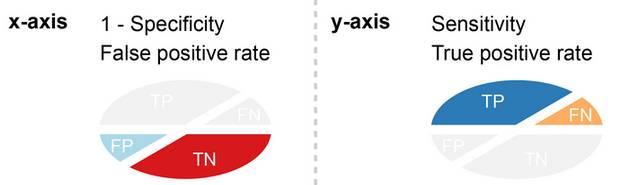
一般情况下, 这个曲线采用描点法(4个点)来确定这个曲线。 而这个曲线下面和X轴的面积,就叫Area Under Curve(AUC)。 AUC是衡量分类器好坏的标准。
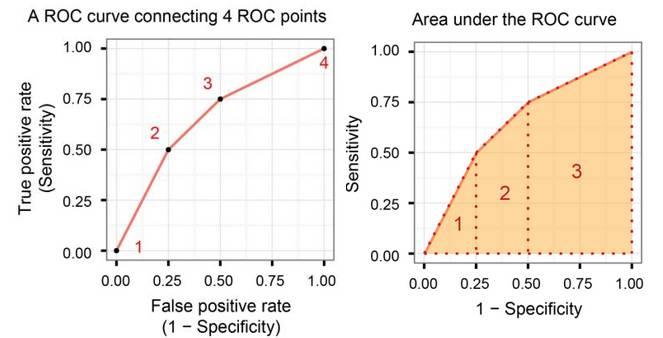
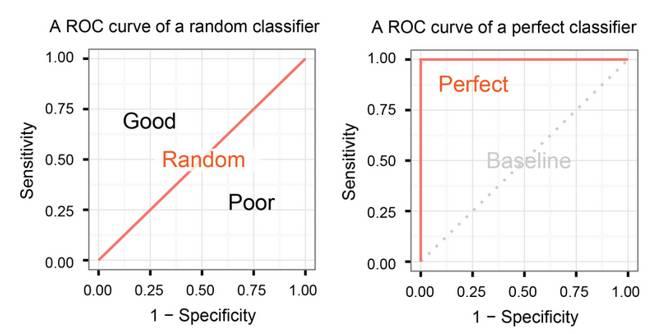
为什么ROC有效呢?因为我们选择一个随机分类器(random classifier), 这是比较一个分类器好坏的最好办法。 因为比随机分类器稍好的叫弱分类器(weak classifier), 要好很多的叫强分类器(strong classifier)。ROC在随机分类器情况下,刚好是对角线。
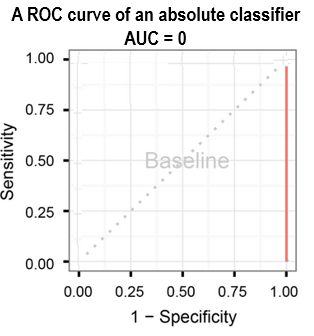
ROC 曲线在absolute classifier把全部数据分到major类别时候, 不存在Accuracy的问题。 因为AUC=0, 是很差的情况。
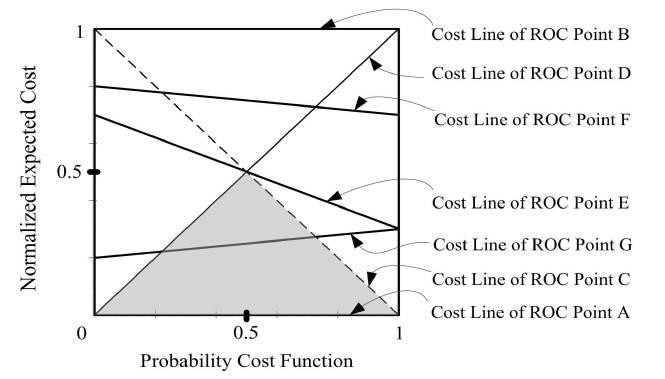
因此, 把ACC受到非均衡影响的叫imbalance sensitive的标准, 而把AUC这类的叫imbalance non-sensitive标准。 所以要选这non-sensitive的标准来衡量非均衡数据。 和ACC相关的F-Measure, 或者相关系数Correlation Coefficient(CC), 以及决策树用的Mutual Information(MI)这些都是sensitive的,不推荐使用。 而G-Mean, AUC, 以及基于ROC衍生的PCF-EC图(Probility Cost Function - Expected Cost)等是non-sensitive的比较推荐。
大致情况,如下图所示, 更多细节就不在这里展开了。
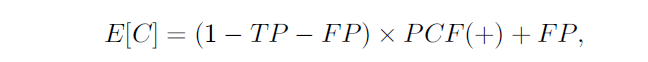
根据Chris Chen的提醒, 加入“Cumulative Gains Curve and lift chart” 和 “Area Under Lift, AUL”:
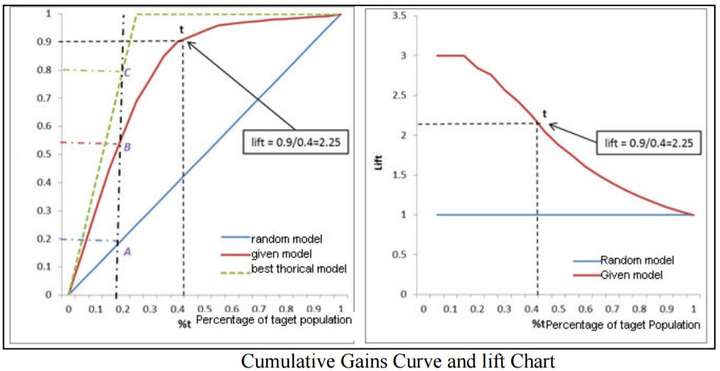
小结, 这样我们总结了如何评价非均衡数据分类的情况, 该选用non-sensitive的标准。 但是如何学习的问题?后续会继续介绍, 主要有三种方式:
- 通过sampling技术,生成均衡的样本
- 调整算法,允许算法改变权重weight变得cost-sensitive。
- 采用集成学习思想, 将major类进行横向划分,形成小的均衡的样本集群。
标签:分类器,AUC,ROC,问题,sensitive,非均衡,均衡,数据,classifier 来源: https://www.cnblogs.com/yumoye/p/10535026.html