atomic框架:LongAdder
作者:互联网
阿里《Java开发手册》最新嵩山版在20年8月3日发布,其中有一段内容如下:
【参考】volatile解决多线程内存不可见问题。对于一写多读,是可以解决变量同步问题,但是如果多写,同样无法解决线程安全问题。
说明:如果是count++操作,使用如下类实现:
AtomicInteger count = new AtomicInteger();
count.addAndGet(1);
如果是JDK8,推荐使用LongAdder对象,比AtomicLong性能更好(减少乐观锁的重试次数)。
以上内容共有两个重点:
- 类似于
count++这种非一写多读的场景不能使用volatile; - 如果是
JDK8推荐使用LongAdder而非AtomicLong来替代volatile,因为LongAdder的性能更好。
一、LongAdder简介
JDK8时,java.util.concurrent.atomic包中提供了一个新的原子类:LongAdder。根据Oracle官方文档的介绍,LongAdder在高并发的场景下会比它的前辈——AtomicLong具有更好的性能,代价是消耗更多的内存空间。
那么,问题来了:
为什么要引入
LongAdder?AtomicLong在高并发的场景下有什么问题吗?如果低并发环境下,LongAdder和AtomicLong性能差不多,那LongAdder是否就可以替代AtomicLong了?
1.1 为什么要引入LongAdder?
AtomicLong是利用了底层的CAS操作来提供并发性的,比如incrementAndGet或者addAndGet方法:
public final long incrementAndGet() {
return unsafe.getAndAddLong(this, valueOffset, 1L) + 1L;
}
public final long addAndGet(long delta) {
return unsafe.getAndAddLong(this, valueOffset, delta) + delta;
}
上述方法调用了Unsafe类的getAndAddLong方法,该方法内部是个native方法,它的逻辑是采用自旋的方式不断更新目标值,直到更新成功。
在并发量较低的环境下,线程冲突的概率比较小,自旋的次数不会很多。但是,高并发环境下,N个线程同时进行自旋操作,会出现大量失败并不断自旋的情况,此时AtomicLong的自旋会成为瓶颈。
这就是LongAdder引入的初衷——解决高并发环境下AtomicLong的自旋瓶颈问题。
二、原理
AtomicLong是多个线程针对单个热点值value进行原子操作。而LongAdder是每个线程拥有自己的槽,各个线程一般只对自己槽中的那个值进行CAS操作。
比如有三个ThreadA、ThreadB、ThreadC,每个线程对value增加10。
对于AtomicLong,最终结果的计算始终是下面这个形式:
\[value = 10 + 10 + 10 = 30 \]但是对于LongAdder来说,内部有一个base变量,一个Cell[]数组。
base变量:非竞态条件下,直接累加到该变量上
Cell[]数组:竞态条件下,累加个各个线程自己的槽Cell[i]中
最终结果的计算是下面这个形式:
2.1 LongAdder的内部结构
LongAdder只有一个空构造器,其本身也没有什么特殊的地方,所有复杂的逻辑都在它的父类Striped64中。
public LongAdder() {
}
来看下Striped64的内部结构,这个类实现一些核心操作,处理64位数据。
Striped64只有一个空构造器,初始化时,通过Unsafe获取到类字段的偏移量,以便后续CAS操作:
abstract class Striped64 extends Number {
Striped64() {
}
private static final sun.misc.Unsafe UNSAFE;
private static final long BASE;
private static final long CELLSBUSY;
private static final long PROBE;
static {
try {
UNSAFE = sun.misc.Unsafe.getUnsafe();
Class<?> sk = Striped64.class;
BASE = UNSAFE.objectFieldOffset
(sk.getDeclaredField("base"));
CELLSBUSY = UNSAFE.objectFieldOffset
(sk.getDeclaredField("cellsBusy"));
Class<?> tk = Thread.class;
PROBE = UNSAFE.objectFieldOffset
(tk.getDeclaredField("threadLocalRandomProbe"));
} catch (Exception e) {
throw new Error(e);
}
}
}
上面有个比较特殊的字段是threadLocalRandomProbe,可以把它看成是线程的hash值。这个后面我们会讲到。
Striped64定义了一个内部Cell类,这就是我们之前所说的槽,每个Cell对象存有一个value值,可以通过Unsafe来CAS操作它的值:
@sun.misc.Contended static final class Cell {
volatile long value;
Cell(long x) { value = x; }
final boolean cas(long cmp, long val) {
return UNSAFE.compareAndSwapLong(this, valueOffset, cmp, val);
}
// Unsafe mechanics
private static final sun.misc.Unsafe UNSAFE;
private static final long valueOffset;
static {
try {
UNSAFE = sun.misc.Unsafe.getUnsafe();
Class<?> ak = Cell.class;
valueOffset = UNSAFE.objectFieldOffset
(ak.getDeclaredField("value"));
} catch (Exception e) {
throw new Error(e);
}
}
}
其它的字段:
可以看到Cell[] 就是之前提到的槽数组,base就是非并发条件下的基数累计值。
/** CPU核数,用来决定槽数组的大小 */
static final int NCPU = Runtime.getRuntime().availableProcessors();
/** 槽数组,大小为2的幂次方 */
transient volatile Cell[] cells;
/**
* 基数,在两种情况下会使用:
* 1. 没有遇到并发竞争时,直接使用base累加数值;
* 2. 初始化cells数组时,必须要保证cells数组只被初始化一次(即只有一个线程能对cells初始化),
* 其他竞争失败的线程会将数值累加到base上
*/
transient volatile long base;
/**
* 锁标识
* cells初始化或扩容时,通过CAS操作将次标识设置为1-加锁状态;
* 初始化或扩容完毕时,将此标识设置为0-无锁状态
*/
transient volatile int cellsBusy;
2.2 LongAdder的核心方法
还是通过例子来看:
假设现在有一个LongAdder对象la,四个线程A、B、C、D同时对la进行累加操作。
LongAdder la = new LongAdder();
la.add(10);
① ThreadA调用add方法(假设此时没有并发):
public void add(long x) {
Cell[] as; long b, v; int m; Cell a;
//★三种情况,这里的cas只尝试一次,(在cells为空的情况下)失败就进去
//1.cells为空,cas(false||false)成功就不进去;
//2.cells为空且casBase失败(false||true),要进去初始化cells
//3.cells不为空(true||{true|false}),肯定要进去尝试优化
if ((as = cells) != null || !casBase(b = base, b + x)) {
boolean uncontended = true;//★初始化未争用标识
if (as == null || (m = as.length - 1) < 0 ||
//★获取当前线程的probe对应的cell,如果为空得初始化
(a = as[getProbe() & m]) == null ||
//★uncontended这个是对线程对应的cell的值进行加一操作的结果,
//冲突说明了什么?hash到同一个cell的多个线程同时操作cas,得进入下一个方法处理
!(uncontended = a.cas(v = a.value, v + x)))
longAccumulate(x, null, uncontended);
}
}
初始时Cell[]为null,base为0。所以ThreadA会调用casBase方法(定义在Striped64中),因为没有并发,CAS操作成功将base变为10:
/**
* CAS操作base值
*/
final boolean casBase(long cmp, long val) {
return UNSAFE.compareAndSwapLong(this, BASE, cmp, val);
}
可以看到,如果线程A、B、C、D线性执行,那casBase永远不会失败,也就永远不会进入到base方法的if块中,所有的值都会累积到base中。那么,如果任意线程有并发冲突,导致caseBase失败呢?失败就会进入if方法体。这个方法体会先再次判断Cell[] 槽数组有没初始化过,如果初始化过了,以后所有的CAS操作都只针对槽中的Cell;否则,进入longAccumulate方法。
整个add方法的逻辑如下图:
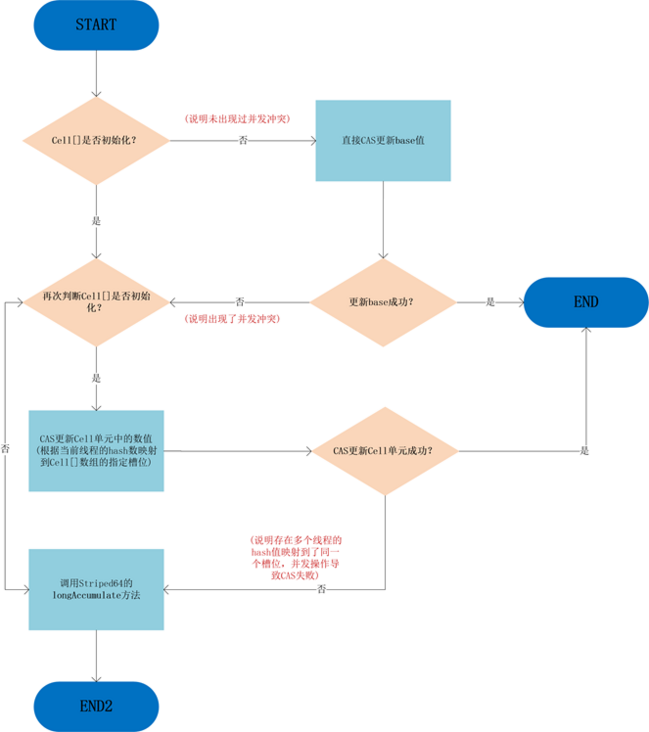
可以看到,只有从未出现过并发冲突的时候,base基数才会使用到,一旦出现了并发冲突,之后所有的操作都只针对
Cell[]数组中的单元Cell。
如果Cell[]数组未初始化,会调用父类的longAccumelate去初始化Cell[],如果Cell[]已经初始化但是冲突发生在Cell单元内,则也调用父类的longAccumelate,此时可能就需要对Cell[]扩容了。
这也是LongAdder设计的精妙之处:尽量减少热点冲突,不到最后万不得已,尽量将CAS操作延迟。
2.3 Striped64的核心方法
我们来看下Striped64的核心方法longAccumulate到底做了什么:
final void longAccumulate(long x, LongBinaryOperator fn, boolean wasUncontended) {
int h;
if ((h = getProbe()) == 0) {//第一次进入,如果hash为0,必须rehash
//初始化ThreadLocalRandom;
ThreadLocalRandom.current();
//将h设置为0x9e3779b9
h = getProbe();
//设置未竞争标记为true
wasUncontended = true;//设置hash到同一个cell上并尝试cas这个cell的value时产生的竞争,竞争改value
}
boolean collide = false; //修改cells起冲突了
for (;;) {
Cell[] as; Cell a; int n; long v;
// CASE1:cells已经初始化
if ((as = cells) != null && (n = as.length) > 0) {//cell为空或者数组非空,可以尝试累加
if ((a = as[(n - 1) & h]) == null) {//当前线程的hash值运算后映射得到的Cell单元为null,说明该Cell没有被使用
if (cellsBusy == 0) {//cellsbusy是个自旋锁,判断是否可以对cells数组进行操作
Cell r = new Cell(x); //创建Cell单元
if (cellsBusy == 0 && casCellsBusy()) {//获取该cell的自旋锁成功,成功后cellsBusy==1
boolean created = false;
try {//在有锁的情况下再检测一遍之前的判断
Cell[] rs; int m, j;//将Cell单元附到Cell[]数组上
if ((rs = cells) != null &&
(m = rs.length) > 0 &&
rs[j = (m - 1) & h] == null) {//再次检查是不是virgin
rs[j] = r; //将该插入的插入
created = true;
}
} finally {
cellsBusy = 0;//自旋锁放开,别人可以对cells数组进行修改操作了
}
if (created)//跳出
break;
continue;//没有获取锁,继续循环
}
}
collide = false;//有别的线程获取了这个cells数组的锁,不能改了,重置collide,继续下一个循环
} else if (!wasUncontended) //wasUncontended表示前一次CAS更新Cell单元是否成功
wasUncontended = true;//重新置为true,后面会重新计算线程的hash值
else if (a.cas(v = a.value, ((fn == null) ? v + x ://尝试CAS更新Cell单元值
fn.applyAsLong(v, x))))
break;
else if (n >= NCPU || cells != as)//当Cell数组的大小超过CPU核数后,永远不会再进行扩容
collide = false;//扩容标志,置为false,表示不会再进行扩容
else if (!collide)
collide = true;//上面全部处理失败,肯定有冲突,将冲突标志位设置为true
else if (cellsBusy == 0 && casCellsBusy()) {//尝试加锁进行扩容
try {
if (cells == as) { //有可能人家改了,又释放了锁,检查cells还是不是以前那个数组
Cell[] rs = new Cell[n << 1]; //扩容后的大小等于当前容量的2倍
for (int i = 0; i < n; ++i)
rs[i] = as[i];
cells = rs;
}
} finally {
cellsBusy = 0;
}
collide = false;
continue; //扩容完还得尝试累加value // Retry with expanded table
}
h = advanceProbe(h);//上面出问题的条件语句,都必须执行这里rehash
}
//CASE2:cells没有加锁且没有初始化,则尝试对它进行加锁,并初始化cells数组
else if (cellsBusy == 0 && cells == as && casCellsBusy()) {//未初始化且获取了cells的自旋锁就初始化
boolean init = false;
try { // Initialize table
//初始化cells数组,初始容量为2,并将x值通过hash&1,放到0个或第1个位置上
if (cells == as) {
Cell[] rs = new Cell[2];//初始化大小2(必须为2的幂次方)
rs[h & 1] = new Cell(x);//将其中初始化,并附初值x
cells = rs;
init = true;
}
} finally {
//解锁
cellsBusy = 0;
}
//如果init为true说明初始化成功,跳出循环
if (init)//初始化成功
break;
}
// CASE3:cells正在进行初始化,则尝试直接在基数base上进行累加操作
else if (casBase(v = base, ((fn == null) ? v + x :
fn.applyAsLong(v, x))))//最次的情况,只能在base上尝试累加了,也就退化成atomicLong类型了
break; // Fall back on using base
}
}
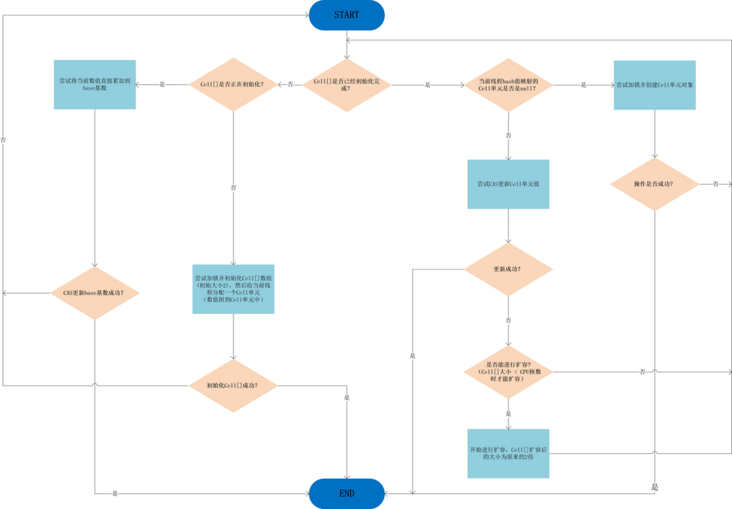
上述代码首先给当前线程分配一个hash值,然后进入一个自旋,这个自旋分为三个分支:
- CASE1:Cell[]数组已经初始化
- CASE2:Cell[]数组未初始化
- CASE3:Cell[]数组正在初始化中
2.3.1 CASE2:Cell[]数组未初始化
我们之前讨论了,初始时Cell[] 数组还没有初始化,所以会进入分支②(CASE2);
首先会将cellsBusy置为1-加锁状态
/**
* CAS操作cellsBusy值,将其置为1-加锁状态
*/
final boolean casCellsBusy() {
return UNSAFE.compareAndSwapInt(this, CELLSBUSY, 0, 1);
}
然后,初始化Cell[]数组(初始大小为2),根据当前线程的hash值计算映射的索引,并创建对应的Cell对象,Cell单元中的初始值x就是本次要累加的值。
2.3.2 CASE3:Cell[]数组正在初始化中
如果在初始化过程中,另一个线程ThreadB也进入了longAccumulate方法,就会进入分支③(CASE3);
可以看到,分支③直接操作base基数,将值累加到base上。
2.3.3 CASE1:Cell[]数组已经初始化
如果初始化完成后,其它线程也进入了longAccumulate方法,就会进入分支①(CASE1);
整个longAccumulate的流程图如下:
2.3.4 LongAdder的sum方法
最后,我们来看下LongAdder的sum方法:
/**
* 返回累加的和,就是”当前时刻“的计数值
*
* 此返回值可能不是绝对准确的,因为调用这个方法时还有其他线程可能正在进行计数累加,
* 方法的返回时刻和调用时刻不是同一个点,在有并发的情况下,这个值只是近似准确的计数值
*
* 高并发时,除非全局加锁,否则得不到程序运行中某个时刻绝对准确的值
*
*/
public long sum() {
Cell[] as = cells; Cell a;
long sum = base;
if (as != null) {
for (int i = 0; i < as.length; ++i) {
if ((a = as[i]) != null)
sum += a.value;
}
}
return sum;
}
需要注意的是,这个方法只能得到某个时刻的近似值,这也就是LongAdder并不能完全替代LongAtomic的原因之一。
三、测试
3.1 volatile线程安全测试
首先我们来测试volatile在多写环境下的线程安全情况,测试代码如下:
public class VolatileExample {
public static volatile int count = 0; // 计数器
public static final int size = 100000; // 循环测试次数
public static void main(String[] args) {
// ++ 方式 10w 次
Thread thread = new Thread(() -> {
for (int i = 1; i <= size; i++) {
count++;
}
});
thread.start();
// -- 10w 次
for (int i = 1; i <= size; i++) {
count--;
}
// 等所有线程执行完成
while (thread.isAlive()) {}
System.out.println(count); // 打印结果
}
}
我们把volatile修饰的count变量++10w次,在启动另一个线程--10w次,正常来说结果应该是0,但是我们执行的结果却为:
1063
结论:由以上结果可以看出volatile在多写环境下是非线程安全的,测试结果和《Java开发手册》相吻合。
3.2 LongAdder VS AtomicLong
接下来,我们使用Oracle官方的JMH(Java Microbenchmark Harness,JAVA微基准测试套件)来测试一下两者的性能,测试代码如下:
import org.openjdk.jmh.annotations.*;
import org.openjdk.jmh.infra.Blackhole;
import org.openjdk.jmh.runner.Runner;
import org.openjdk.jmh.runner.RunnerException;
import org.openjdk.jmh.runner.options.Options;
import org.openjdk.jmh.runner.options.OptionsBuilder;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.atomic.AtomicInteger;
import java.util.concurrent.atomic.LongAdder;
@BenchmarkMode(Mode.AverageTime) // 测试完成时间
@OutputTimeUnit(TimeUnit.NANOSECONDS)
@Warmup(iterations = 1, time = 1, timeUnit = TimeUnit.SECONDS) // 预热 1 轮,每次 1s
@Measurement(iterations = 5, time = 5, timeUnit = TimeUnit.SECONDS) // 测试 5 轮,每次 3s
@Fork(1) // fork 1 个线程
@State(Scope.Benchmark)
@Threads(1000) // 开启 1000 个并发线程
public class AlibabaAtomicTest {
public static void main(String[] args) throws RunnerException {
// 启动基准测试
Options opt = new OptionsBuilder()
.include(AlibabaAtomicTest.class.getSimpleName()) // 要导入的测试类
.build();
new Runner(opt).run(); // 执行测试
}
@Benchmark
public int atomicTest(Blackhole blackhole) throws InterruptedException {
AtomicInteger atomicInteger = new AtomicInteger();
for (int i = 0; i < 1024; i++) {
atomicInteger.addAndGet(1);
}
// 为了避免 JIT 忽略未被使用的结果
return atomicInteger.intValue();
}
@Benchmark
public int longAdderTest(Blackhole blackhole) throws InterruptedException {
LongAdder longAdder = new LongAdder();
for (int i = 0; i < 1024; i++) {
longAdder.add(1);
}
return longAdder.intValue();
}
}
程序执行的结果为:

从上述的数据可以看出,在开启了1000个线程之后,程序的LongAdder的性能比AtomicInteger快了约1.53 倍,你没看出是开了1000个线程,为什么要开这么多呢?这其实是为了模拟高并发高竞争的环境下二者的性能查询。
如果在低竞争下,比如我们开启100个线程,测试的结果如下:

LongAdder与AtomicLong比较
- LongAdder提供的API和AtomicLong比较接近,两者都能以原子的方式对long型变量进行增减。AtomicLong提供的功能其实更丰富。
- addAndGet 、decrementAndGet除了单纯的做自增自减外,还可以立即获取增减后的值,而LongAdder则需要做同步控制才能精确获取增减后的值。如果业务需求需要精确的控制计数,做计数比较,AtomicLong也更合适。
- 低并发、一般的业务场景下AtomicLong是足够了。如果并发量很多,存在大量写多读少的情况,那LongAdder可能更合适。
结论:从上面结果可以看出,在低竞争的并发环境下AtomicInteger的性能是要比LongAdder的性能好,而高竞争环境下LongAdder的性能比AtomicInteger好,当有1000个线程运行时,LongAdder的性能比AtomicInteger快了约1.53倍,所以各位要根据自己业务情况选择合适的类型来使用。
3.3 性能分析
为什么会出现上面的情况?这是因为AtomicInteger在高并发环境下会有多个线程去竞争一个原子变量,而始终只有一个线程能竞争成功,而其他线程会一直通过CAS自旋尝试获取此原子变量,因此会有一定的性能消耗;而LongAdder会将这个原子变量分离成一个Cell数组,每个线程通过Hash获取到自己数组,这样就减少了乐观锁的重试次数,从而在高竞争下获得优势;而在低竞争下表现的又不是很好,可能是因为自己本身机制的执行时间大于了锁竞争的自旋时间,因此在低竞争下表现性能不如AtomicInteger。
四、LongAdder的兄弟类
JDK1.8时,java.util.concurrent.atomic包中,除了新引入LongAdder外,还有引入了它的三个兄弟类:LongAccumulator、DoubleAdder、DoubleAccumulator

LongAccumulator
LongAccumulator是LongAdder的增强版。LongAdder只能针对数值的进行加减运算,而LongAccumulator提供了自定义的函数操作。其构造函数如下:
public LongAccumulator(LongBinaryOperator accumulatorFunction, long identity) {
this.function = accumulatorFunction;
base = this.identity = identity;
}
通过LongBinaryOperator,可以自定义对入参的任意操作,并返回结果(LongBinaryOperator接收2个long作为参数,并返回1个long)
LongAccumulator内部原理和LongAdder几乎完全一样,都是利用了父类Striped64的longAccumulate方法。
DoubleAdder和DoubleAccumulator
从名字也可以看出,DoubleAdder和DoubleAccumulator用于操作double原始类型。
与LongAdder的唯一区别就是,其内部会通过一些方法,将原始的double类型,转换为long类型,其余和LongAdder完全一样:
public void add(double x) {
Cell[] as; long b, v; int m; Cell a;
if ((as = cells) != null ||
!casBase(b = base,
Double.doubleToRawLongBits
(Double.longBitsToDouble(b) + x))) {
boolean uncontended = true;
if (as == null || (m = as.length - 1) < 0 ||
(a = as[getProbe() & m]) == null ||
!(uncontended = a.cas(v = a.value,
Double.doubleToRawLongBits
(Double.longBitsToDouble(v) + x))))
doubleAccumulate(x, null, uncontended);
}
}
五、总结
本文我们测试了volatile在多写情况下是非线程安全的,而在低竞争的并发环境下AtomicInteger的性能是要比LongAdder的性能好,而高竞争环境下LongAdder的性能比AtomicInteger好,因此我们在使用时要结合自身的业务情况来选择相应的类型。
标签:初始化,LongAdder,框架,cells,long,Cell,线程,atomic 来源: https://www.cnblogs.com/ciel717/p/16190545.html