数据结构--图的基础知识
作者:互联网
图
定义
图(Graph), 又V和E两个非空集合构成,表示为G = (V,E);
其中,V表示的是图G中的顶点的又穷非空集合;E表示的是图G中的两个顶点之间连接的边的有穷集合;
V(G),E(G)通常分别表示G的顶点集,边集;
ps: 一个图,可以没有边,也就是E(G)可以为空,但是V(G)不能
图的基本术语
无向边: 若顶点vi到vj之间的边没有方向,则称这条边为无向边(Edge),用无序偶对(vi,vj)来表示。
无向图: 如果图中任意两个顶点之间的边都是无向边,则称该图为无向图(Undirected graphs)。
有向边: 若从顶点vi到vj的边有方向,则称这条边为有向边,也称为弧(Arc)。用有序偶来表示,vi称为弧尾(Tail),vj称为弧头(Head)。
有向图: 如果图中任意两个顶点之间的边都是有向边,则称该图为有向图(Directed graphs)。
无向边用小括号“()”表示,而有向边则是用尖括号“<>”表示。
简单图: 在图中,若不存在顶点到其自身的边,且同一条边不重复出现,则称这样的图为简单图。
无向完全图: 在无向图中,如果任意两个顶点之间都存在边,则称该图为无向完全图。
含有n个顶点的无向完全图有n(n-1)/2条边。
有向完全图: 在有向图中,如果任意两个顶点之间都存在方向互为相反的两条弧,则称该图为有向完全图。
含有n个顶点的有向完全图有n×(n-1)条边。
对于具有n个顶点和e条边数的图,无向图,有向图。
稀疏图与稠密图: 有很少条边或弧的图称为稀疏图,反之称为稠密图。这里稀疏和稠密是模糊的概念,都是相对而言的。
权: 有些图的边或弧具有与它相关的数字,这种与图的边或弧相关的数叫做权(Weight)。这些权可以表示从一个顶点到另一个顶点的距离或耗费。
网: 带权的图通常称为网(Network)。
子图: 设有两个图G=(V,{E})和G'=(V',{E'}),如果V'∈V且E'∈E,则称G'为G的子图(Sub-graph)。
邻接点: 对于无向图G=(V,{E}),如果边(v,v')∈E,则称顶点v和v'互为邻接点(Adjacent),即v和v'相邻接。
边(v,v')依附(incident)于顶点v和v',或者说(v,v')与顶点v和v'相关联。
度: 顶点v的度(Degree)是和v相关联的边的数目,记为TD(v)。
对于有向图G=(V,{E}),如果弧∈E,则称顶点v邻接到顶点v',顶点v'邻接自顶点v。弧和顶点v,v'相关联。以顶点v为
头弧的数目称为v的入度(InDegree),记为ID(v);以v为尾的弧的数目称为v的出度(OutDegree),记为OD(v);顶点v的度为TD(v)=ID(v)+OD(v)。
路径: 无向图G=(V,{E})中从顶点v到顶点v'的路径(Path)是一个顶点序列。如果G是有向图,则路径也是有向的。
路径的长度是路径上的边或弧的数目。
回路: 第一个顶点和最后一个顶点相同的路径称为回路或环(Cycle)。
简单路径: 序列中顶点不重复出现的路径称为简单路径。
简单回路: 除了第一个顶点和最后一个顶点之外,其余顶点不重复出现的回路,称为简单回路或简单环。
连通: 在无向图G中,如果从顶点v到顶点v'有路径,则称v和v'是连通的。
连通图: 如果对于图中任意两个顶点vi、vj∈V,vi和vj都是连通的,则称G是连通图(Connected Graph)。
连通分量: 无向图中的极大连通子图称为连通分量。连通分量的概念强调:
- 要是子图;
- 子图要是连通的;
- 连通子图含有极大顶点数;
- 具有极大顶点数的连通子图包含依附于这些顶点的所有边。
强连通图: 在有向图G中,如果对于每一对vi、vj∈V、vi≠vj,从vi到vj和从vj到vi都存在路径,则称G是强连通图。
强连通分量: 有向图中的极大强连通子图称做有向图的强连通分量。
连通图的生成树: 所谓的一个连通图的生成树是一个极小的连通子图,它含有图中全部的n个顶点,但只有足以构成一棵树的n-1条边。
如果一个图有n个顶点和小于n-1条边,则是非连通图,如果它多于n-1边条,必定构成一个环,因为这条边使得它依附的那两个顶点之间有了第二条路径。
有向树: 如果一个有向图恰有一个顶点的入度为0,其余顶点的入度均为1,则是一个有向树。
对有向树的理解比较容易,所谓入度为0其实就相当于树中的根结点,其余顶点入度为1就是说树的非根结点的双亲只有一个。
有向图的生成森林: 一个有向图的生成森林由若干棵有向树组成,含有图中全部顶点,但只有足以构成若干棵不相交的有向树的弧。
图的存储结构
由千图的结构比较复杂,任意两个顶点之间都可能存在联系,因此无法以数据元素在存储区
中的物理位置来表示元素之间的关系,即图没有顺序存储结构,但可以借助
二维数组来表示元素之间的关系,即邻接矩阵表示法。另一方面,由于图的任意两个顶点间都可能存在关系,因此,
用链式存储表示图是很自然的事,图的链式存储有多种,有邻接表、十字链表和邻接多重表,应
根据实际需要的不同选择不同的存储结构。
邻接矩阵表示法

由图解:顶点之间关联就对应二维数组上就赋值1,反之就为0;
对于网,有边的位置,赋值其权,其余为 ∞;
使用邻接矩阵表示法,除了需要用二维数组表示元素之前的关系时,还需要用一个一维数组来表示每个顶点所包含的数据;
// 对于网和普通的图,主要是多了一个权,所以这里以网结构来展开
const int MVNum = 100; // 最大顶点数
const int MaxInt = 32767; // 最大值, ∞
// 定义一个结构体
typedef struct {
ElemType vexs[MVNum]; // 顶点表
int arcs[MVNum][MVNum]; // 邻接矩阵
int vexNum, arcNum; // 图的当前点数和边数
}AMGraph;
创建一个无向网
//
Status CreateUDN(AMGraph &G) {
//
cin>>G.vexNum>>G.arcNum; // 输入中的顶点数,和边数
for(int i = 0; i < G.vexNum; i++) {
cin>>G.vexs[i]; // 这里对顶点元素数据赋值
}
for(int i = 0; i < G.vexNum; i++) {
for(int j = 0; j < G.vexNum; j++) {
G.arcs[i][j] = MaxInt; // 对邻接矩阵初始化
}
}
for(int i = 0; i < G.arcNum; i++) {
int v1,v2; // 顶点
int w; // 权重
cin>>v1>>v2>>w;
// 获取v1,v2顶点在邻接矩阵中的位置
int _v1 = locateVex(G,v1);
int _v2 = lovateVex(G,v2);
G.arcs[_v1][_v2] = w; //设置权重
G.arcs[_v2][_v1] = G.arcs[_v1][_v2]; // 这是无向网的特别处理
}
return OK;
}
邻接矩阵表示的优劣
(1)优点
-
便于判断两个顶点之间是否有边, 即根据
A[i][j] = 0或1来判断。 -
便于计算各个顶点的度。对千无向图,邻接矩阵第凶于元素之和就是顶点l的度;对于有向图,第i行 元素之和就是顶点 i 的出度,第i 列元素之和就是顶点l 的入度。
(2) 缺点
-
不便千增加和删除顶点。
-
不便千统计边的数目,需要扫描邻接矩阵所有元素才能统计完毕。
-
空间复杂度高。如果是有向图,n个顶点需要n2个单元存储边。如果是无向图,因其邻接矩阵是对称的,所以对规模较大的邻接矩阵可以采用压缩存储的方法,仅存储下三角(或上三角)的元素,这样需要n(n-1)/2个单元即可。但无论以何种方式存储,邻接矩阵表示法的空间复杂度均为0(心,这对千稀疏图而言尤其浪费空间。
邻接表表示法
采用链式存储的结构,每个顶点构建一个单链表,其中表头存放顶点信息,其余结点存放相关边的信息;

- data, info 为数据域
- firstarc,nextarc 为链域
- adjvex 邻接域
表头结点采用顺序存储的结构存储,以便可以随机访问任一顶点的边链表
//
const int MaxInt = 100;
// 边结点
typedef struct ArcNode{
int adjvex; // 改变所指向的顶点的位置
struct ArcNode * nextarc; // 指向下一条边
int info; // 和边相关的信息
}ArcNode;
// 顶点信息
typedef struct VNode {
int data; // 数据域
ArcNode * firstarc; // 指向第一条依附该顶点的边的指针
}VNode, AdjList[MVNum];
//
typedef struct {
AdjList vertices; //邻接表
int vexNum, arcNum; // 图的当前顶点,边数
}ALGraph;
采用邻接表创建一个无向图
//
status CreateUDG(ALGraph & G) {
cin>>G.vexNum>>G.arcNum;
// 对每一个链表进行赋值初始化
for(int i = 0; i<G.vexNum; i++) {
cin>>G.vertices[i].data; // 输入头结点信息
G.vertices[i].firstarc = NULL;
}
for(int i = 0; i < G.arcNum; i++) {
cin>>v1>>v2;
int _v1 = locateVex(G,v1);
int _v2 = lovateVex(G,v2);
// 动态开辟空间,创建一个边结点
ArcNode * p1 = new ArcNode; //
p1->adjvex = _v2; // 邻接点序号为_v2
p1->nextarc = G.vertices[_v1].firstarc;
G.vertices[_v1].firstarc = p1;
// 对称结点
ArcNode * p2 = new ArcNode;
p2->adjvex = _v1;
p2->nextarc = G.vertices[_v2].firstarc;
G.vertices[_v2].firstarc = p2;
}
return OK;
}
ps:,一个图的邻接矩阵表示是唯一的,但其邻接表表示不唯一,这是因为邻接表表示中,各边表结点的链接次序取决于建立邻接表的算法,以及边的轮入次序
邻接表表示法的优缺点
(1) 优点
-
便于增加和删除顶点。
-
便于统计边的数目, 按顶点表 顺 序扫描 所 有边表可得到边的数目。
-
空间效率高。对于一个具有n个顶点e条边的图 G, 若 G 是无向图,则在其邻接表表示中有 n 个顶点表结点和 2e 个边表结点;若 G 是有向图,则在它的邻接表表示或逆邻接表表示中均有 n 个顶点表结点和e个边表结点。因此,邻接表或逆邻接表表示的空间复杂度为 O(n + e), 适合表示稀疏图。对于稠密图,考虑到邻接表中要附加链域,因此常采取邻接矩阵表示法。
(2) 缺点
-
不便于判断顶点之间是否有边,要判定 Vi和vj之间是否有边,就需扫描第i个边表,最坏情况下要耗费 O(n)时间。
-
不便于计算有向图各个顶点的度。对于无向图,在邻接表表示中顶点Vi的度是第i个边表中的结点个数。 在有向图的邻接表中,第 i 个边表上的结点个数是顶点 Vi的出度,但求 Vj的入度较困难,需遍历各顶点的边表。若有向图采用逆邻接表表示(就是边表尾入度),则与邻接表表示相反,求顶点的入度容易,而求顶点的出度较难。
十字链表
十字链表 (Orthogonal List) 是有向图的另一种链式存储结构。可以看成是将有向图的邻接表和逆邻接表结合起来得到的一种链表。 在十字链表中,对应于有向图中每一条弧有一个结点,对应于每个顶点也有一个结点。

- 尾域 (tailvex) 和头域 (headvex) 分别指示弧尾和弧头这两个顶点在图中的位置;
- 链域 hlink 指向弧头相同的下一条弧,而链域 tlink 指向弧尾相同的下一条弧;
- info域指向该弧的相关信息。弧头相同的弧在同一链表上,弧尾相同的弧也在同一链表上;
- data 域存储和顶点相关的信息,如顶点的名称等;
- firstin 和 firstout为两个链域,分别指向以该顶点为弧头或弧尾的第一个弧结点。
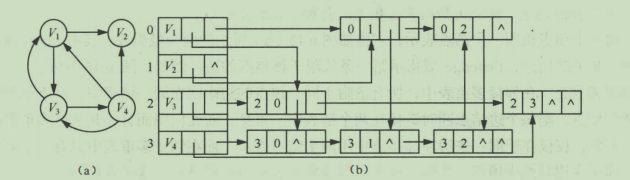
ps: 此图弧结点省略了info
有向图的十字链表存储表示
//
const int MAX_VERTEX_NUM = 20;
typedef struct ArcBox {
int tailvext, headvex; // 该弧头尾顶点的位置, 这里特指顶点在顺序存储中的索引值
struct ArcBox * hlink, * tlink; // 弧头,弧尾相同的链域
int info; // 信息
}ArcBox;
typedef struct VexNode {
int data;
ArcBox * firstin, * firstout; // 入弧,出弧
}VexNode;
typedef struct {
VexNode xlist[MAX_VERTEX_NUM]; //
int vexnum,arcnum; // 有向图当前顶点数,和弧数
}OLGraph;
邻接多重表
邻接多重表 (Adjacency Multilist) 是无向图的另一种链式存储结构。虽然邻接表是无向图的
一种很有效的存储结构,在邻接表中容易求得顶点和边的各种信息。但是,在邻接表中每一条边
(Vi, Vj )有两个结点,分别在第i个和第j个链表中,这给某些图的操作带来不便。

- mark 为标志域,可用以标记该条边是否被搜索过;
- ivex 和 jvex为该边依附的两个顶点在图中的位置;
- ilink 指向下一条依附于顶点 ivex 的边;
- jlink 指向下一条依附于顶点jvex的边,info为指向和边相关的各种信息的指针域;
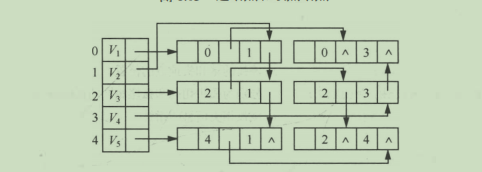
无向图的邻接多重表存储表示
const int MAX_VERTEX_NUM = 20;
typedef enum{unvisited, visited} VisitIf;
typedef struct EBox {
VisitIf mark; // 访问标记
int ivex, jvex; // 该边依附的两个顶点的位置
struct EBox * ilink, *jlink; // 分别指向依附这两个顶点的下一条边
int info;
}EBox;
typedef struct VexBox {
int data;
EBox * firstedge; // 指向第一条依附该顶点的边
}VexBox;
typedef struct {
VexBox adjmulist[MAX_VERTEX_NUM];
int vexNum, arcNum;
}AMLGraph;
图的基本操作
CreateGraph{&G,V,VR}
初始条件:V是图的顶点集,VR是图中弧的集合。
操作结果:按V和VR的定义构造图G。
DestroyGraph { &G}
初始条件:图G存在。
操作结果:销毁图G。
Locat eVex{G,u}
初始条件:图G存在,u和G中顶点有相同特征。
操作结果:若G中存在顶点 u, 则返回该顶点在图中的位置;否则返回其他信息。
GetVex{G,v}
初始条件:图G存在,v是G中某个顶点。
操作结果:返回v的值
PutVex(&G,v,value);
初始条件:图G存在,v是G中某个顶点。
操作结果:对 v赋值value。
FirstAdjVex(G,v)
初始条件:图G存在,v是G中某个顶点。
操作结果:返回 v的第一 个邻接顶点。若v在G中没有邻接顶点,则返回 “空” 。
NextAdjVex(G,v,w)
初始条件:图G存在,v是G中某个顶点,w是v的邻接顶点。
操作结果:返回v的(相对千w的)下一 个邻接顶点。若w是v的最后一 个邻接点,则返回 “空” 。
InsertVex(&G,v)
初始条件:图G存在,v和图中顶点有相同特征。
操作结果:在图G中增添新顶点v。
DeleteVex(&G,v)
初始条件:图G存在,v是G中某个顶点。
操作结果:删除 G中顶点v及其相关的弧。
InsertArc(&G,v,w)
初始条件:图G存在,v和w是G中两个顶点。
操作结果:在G中增添弧<v, w>, 若G是无向图,则还增添对称弧<w, v>。
Dele七eArc(&G,v,w)
初始条件:图G存在,v和w是G中两个顶点。
操作结果:在G中删除弧<v, w>, 若G是无向图,则还删除对称弧<w, v>。
DFSTraverse(G)
初始条件:图G存在。
操作结果:对图进行深度优先遍历,在遍历过程中对每个顶点访问一次。
BFSTraverse(G)
初始条件:图G存在。
操作结果:对图进行广度优先遍历,在遍历过程中对每个顶点访问一次
标签:结点,有向图,--,连通,基础知识,int,邻接,顶点,数据结构 来源: https://www.cnblogs.com/longyuan-ly/p/15868591.html