如何提高少样本学习中的参数有效性以及数据有效性
作者:互联网
©原创作者 | 康德

链接:
https://arxiv.org/abs/2110.06274
Github:
https://github.com/microsoft/LiST
本文提出一种在少样本学习情况下对大型预训练语言模型(PLMs)进行有效微调的方法-LiST。LiST比最近采用提示微调的方法有了显著的改进,主要使用了两个关键技术。
第一个是使用自训练来利用大量未标记的数据进行提示微调,以显著提高在少样本学习情况下的模型性能。本文将自训练与元学习结合起来,重新加权有噪声的伪提示标签。然而,传统的自训练方法需要对所有模型参数进行重复更新,开销较大。
因此,本文使用第二种技术进行轻量级微调,其中引入少量特定任务的适配器参数,这些参数在自训练期间进行微调,同时保持PLM编码器的冻结状态。这样就可以使多个下游任务共用同一套PLM编码器参数,从而大大减少模型的占用空间。
结合上述技术,LiST不仅提高了目标任务中少样本学习的模型性能,还减少了模型内存占用。本文对六个NLU任务进行了全面的研究,验证LiST的有效性。
结果表明,LiST性能比经典微调方法提高了35%;在每个任务不超过30个标记示例的情况下进行微调,比提示调整方法提高了6%,可训练参数的数量减少了96%。
01 Introduction
大型预训练语言模型(PLMs)已经在一些自然语言理解任务中取得了较好的性能。尽管这些大型语言模型取得了显著的成功,但它们面临着两个重大挑战。
第一个是PLMs需要大量的带标签数据进行训练,以获得最优结果。虽然GPT-3 等模型获得了令人印象深刻的少样本学习性能,但与完全监督的SOTA模型相比,它们有显著的性能差距。
例如,在SuperGLUE任务中,GPT-3的性能比完全调参的DeBERTa 差20个百分点。这对许多现实世界的任务提出了重大挑战,因为在这些任务中,很难获得大的标签数据。
第二个是大量的可调参数。就可训练参数而言,PLMs的规模一直在稳步增长,范围从数百万到数十亿个参数。这大大增加了微调大型PLMs所有参数的计算成本,以及整体模型占用空间的存储成本,其中每个任务都需要定制大型模型参数的副本。
为了解决上述挑战,考虑在现实世界中,对PLMs进行微调需要满足以下两个标准。
Few-shot: 假设每个任务域中的任务标签数量非常有限。
Light-weight: 对于每个新任务,微调应该有少量的可调参数,以降低总体存储成本和模型占用空间。
本文提出了两个关键技术用来提高少样本学习的能力以及高效的微调策略:
(a) 通过提示和未标记的数据进行自我训练。
第一种方法是利用来自目标域的大量未标记数据进行自训练,以提高在少样本学习下的模型适应性。研究给定提示以及少量的标注样本,迭代的优化一对教师-学生模型,可以提高自训练的性能。
由于教师模型在少样本学习的过程中会产生较多的噪声标签,因此需要通过元学习来为噪声样本重新赋权。
(b) 轻量级adapter-tuning。
传统的自训练非常昂贵,因为需要迭代地更新所有的模型参数。因此,在PLM中引入了少量的任务特定的适配器参数,这些参数用少量标签数据更新,同时保持大型PLM编码器的固定。
通过实验证明,带有自训练的轻量级调优性能可以匹配所有模型参数都被调优的设置。这可以有效地利用自训练,提高微调过程的参数效率,并降低微调模型的存储成本,因为在推理过程中,多个微调模型可以共享相同的PLM作为骨干。
本文在六个自然语言理解任务中进行了大量的实验,结果表明,LiST比传统的和最近的提示调优方法分别提高了35%和6%,每个下游任务只给出30个标记示例的情况下,可训练参数的数量减少了96%,证明了LiST的有效性。
图1显示各个方法的比较结果。


图1 LiST利用对未标记数据的提示微调来提高标签效率,以及利用适配器减少可调参数。上图显示RoBERTa-large
作为主干网络,以MNLI任务作为比较,红色虚线表示RoBERTa-large在完全监督下的表现(400k个训练标签)。下图显示每个方法的可调参数。
02 Background

03 Methodology
采用一个PLM作为学生和教师的共享编码器来进行自训练。共享的PLM编码器参数在训练的时候是冻结的。在教师和学生中引入可调适配器参数,这些参数在自训练过程中会进行迭代调优。
整个流程如图2所示,第一步通过少量的标注样本提示调优教师适配器;
第二步通过教师模型为
数据集

标注伪标签;
教师在少样本学习中会产生噪音伪标签,因此第三步采用meta-learning来重新分配伪标签样本的权重;
第四步用重新参数化的数据来训练学生适配器;
由于用伪标签训练的适配器非常不稳定,因此引入知识蒸馏预热,第五步将训练好的学生适配器作为新的教师适配器。
重复上面步骤6次。
在整个训练过程中,保持共享的学生和教师编码器参数不变,只更新相应的适配器参数。
3.1 轻量级提示适配器调优
为了微调少量参数,使得PLMs适应下游任务。适配器最近被提出,作为轻量级调优的一种方法。实验证明微调适配器的方法能够达到全监督的微调方法性能。
本文是第一个研究适配器在少样本提示微调中作用的文章。该论文研究了在少样本学习下适配器的不同设计和放置选择,并研究了在完全监督和完全可调参数空间下的性能差距。
适配器微调策略在原始的PLMs中引入新的参数,
提示微调更新PLMs所有参数
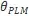
,提示适配器微调仅仅更新适配器的参数以及PLM语言模型的头部,而保持原始网络其他参数不变。
LiST中的适配器由两个全连接层组成,其中一个前馈神经网络层将输入映射到低维空间d,另一个前馈神经网络层将低维特征映射到原来的维度。
然而,这些新插入的参数可能会导致发散,从而使得在少样本学习下性能下降20%,为了解决这个问题,采用了一种跳跃连接设计,其中适配器用带有零均值小高斯噪声初始化。
适配器放在不同的位置也会对性能有影响,本文主要研究了将适配器放在嵌入层、中间层、输出层、以及注意力模块,如图3所示。

图3 几种不同的适配器位置选择
3.2 重新加权噪声提示标签

在自训练中,学生模型在迁移集上训练来模仿教师的预测。重新加权机制利用梯度作为代理来估计有噪声的伪标签的权重。
但是,由于随机初始化和伪标签中的噪声,在训练的早期,适配器参数的梯度并不稳定。适配器调优通常需要更大的学习速度,这进一步加剧了不稳定性问题。
元重新加权机制利用梯度作为代理来估计伪标签的权重。但是,由于随机初始化和伪标签中的噪声,在训练的早期,适配器参数的梯度并不稳定。适配器调优通常需要更大的学习速度,这进一步加剧了不稳定性问题。
因此,为了稳定适配器的调优,提出了一个通过知识蒸馏的warmup训练阶段。
首先通过知识蒸馏损失
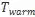
调优适配器参数,
然后通过重新加权更新继续自训练。
因为重新加权过程需要保留验证集,在知识蒸馏过程中,我们不使用标注数据,而只在非标签数据上使用教师模型和学生模型之间的一致性损失,如下所示:
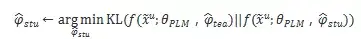
3.3 LITE自训练:总结
1、通过利用来自目标域的未标记数据,自训练有助于少样本学习模型有效适应目标任务。
2、带有提示的自训练通过弥合预训练和微调目标之间的差距来提高模型性能。
3、适配器通过微调少量的模型参数,同时保持PLM编码器的固定,从而降低总体存储成本和模型占用空间。
4、将上述策略与一种新颖的微调方法相结合,LiST在少样本学习中能有效利用标签数据,以及有效的微调参数。
04 Experiments
数据集:在六个数据集上进行实验,如下表所示。

表1 数据集摘要和任务描述。
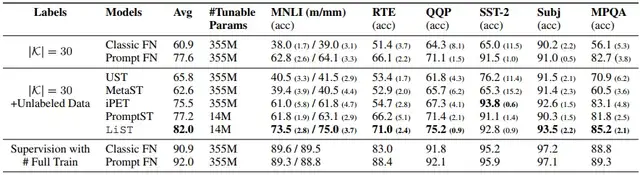
表2 以RoBERTa作为编码器,不同模型调优策略在不同任务上的性能比较。UST, MetaST, PromptST
和 iPET 使用非标签数据进行半监督学习,而Classic FN和Prompt FN使用标签数据。黑体显示最好的性能。
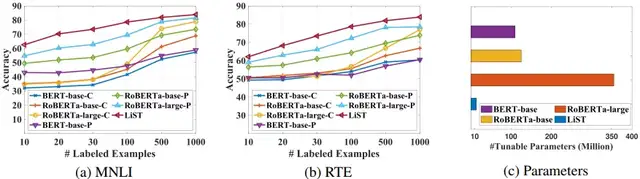
图4 使用不同大小的语言模型编码器,在MNLI和RTE上使用LiST进行经典调优(记作“C”)和提示调优(记作“P”)的性能比较。
图4比较不同的调优方法在不同数量的训练数据和不同大小的编码器的上的性能比较。
可以看到,与较小的模型相比,大型模型的数据效率更高。然而,在实践中使用大型的完全可调模型是昂贵的。
本文剩下内容还讨论了adapter的最佳插入位置、与其他轻量级参数高效模型调优策略的比较、适配器训练的稳定性等内容,有兴趣的小伙伴可以看看。
05 Conclusions
本文开发了一种新的方法LiST,用于在少样本学习下对大型语言模型进行轻量级调优。LiST使用自训练从目标域的大量未标记数据中学习。
为了降低存储和训练成本,LiST只对少量适配器参数进行调整,使用较少标注样本,同时保持大型编码器不变。
虽然适配器可以降低存储成本,但LiST并不能降低PLM主干的推理延迟。未来的工作是考虑结合模型压缩技术结合适配器来减少FLOPS和延迟。
本文是一篇多种技术叠加类的文章,使用了教师-学生模型、提示调优、适配器等技术,工作量比较大,收录于主流顶会应该没什么问题。
私信我领取目标检测与R-CNN/数据分析的应用/电商数据分析/数据分析在医疗领域的应用/NLP学员项目展示/中文NLP的介绍与实际应用/NLP系列直播课/NLP前沿模型训练营等干货学习资源。
标签:微调,训练,模型,适配器,样本,调优,参数,有效性 来源: https://www.cnblogs.com/NLPlunwenjiedu/p/15863364.html