深度学习(机器学习)的下一步如何发展?
作者:互联网
https://www.zhihu.com/question/47602063/answer/150845355
微软亚洲研究院机器学习组包含机器学习的各个主要方向,在理论、算法、应用等不同层面推动机器学习领域的学术前沿。该组目前的研究重点为深度学习、增强学习、分布式机器学习和图学习。其研究课题还包括排序学习、计算广告和云定价。在过去的十几年间,该组在顶级国际会议和期刊上发表了大量高质量论文,帮助微软的产品部门解决了很多复杂问题,并向开源社区贡献了微软分布式机器学习工具包(DMTK)和微软图引擎(Graph Engine),LightLDA、LightGBM等,并受到广泛关注。该组正在招贤纳士,诚邀各路英雄好汉加盟,共同逐鹿AI天下。联系我们。
————这里是正式回答的分割线————
要回答这个问题,先要从人工智能近年的进展开始说起。
从1956年达特茅斯会议上人工智能的诞生开始,到如今人工智能已经发展了61年,这期间人工智能历经风雨,经历了数次高潮也有数次低谷,每次高潮都是因为核心技术的提出引起了人们极大的兴趣,吸引了大量的资金的投入。但同时由于大家的期望值远远超过了技术所能够达到的高度,因此当人们发现巨大的资金和人才的投入不能达到预期成果的时候,人工智能的冬天也随之而来。幸运的是,现在我们正处于人工智能的第三次浪潮,并且目前看来,距离下一个冬天还是挺远的。从媒体的报道,大家可能都能了解到,人工智能在各个方向都取得了非常大的进展,不管是研究上、实践上,还是应用上。下面我们简单回顾一下人工智能近年来在各个方向取得的进展。
早在2012年,微软就在“21世纪的计算”大会上展示了一个同声传译的系统,这个系统其实相当复杂:当微软研究院创始人Rick Rashid用英文演讲的时候,这个系统首先需要将英文的语音识别成英文的文本,然后通过一个翻译系统把英文翻译成中文,然后再把中文文本合成成为中文的语音。整个复杂的过程都是通过深度学习的技术来支撑的。
在2015年底,发生了一件对计算机视觉领域而言非常重要的事情,就是微软亚洲研究院的研究员提出了一个新的基于CNN的深度模型叫做残差网络,这个残差网络深度高达152层,取得了当时图象识别比赛上面最好的成绩。到现在为止,深度残差网络在计算机视觉的研究中被广泛使用,并且被集成到微软还有其他大公司的产品中。
再到后来,2016年初,可能大家都知道,AlphaGo这个系统打败了围棋世界冠军李世石,这非常出乎人们的预料,特别是AI专家的预料,因为大家普遍认为,机器要在围棋上战胜人类可能还需要20年。在2016年下半年,微软宣布了另外一项AI上的进展,就是在日常对话的语音识别中,微软的技术已经达到了人类的水平,这也是非常了不起的,因为如果大家关注一下我们日常的讲话,就会发现,其中有很多停顿,并且带一些语气词,与朗诵或者新闻播音相差很大,这种日常对话识别要达到人类的水平是很不容易的。
从以上的简单回顾可以看出,人工智能的第三波浪潮和深度学习是分不开的。深度学习里最经典的模型是全连接的神经网络,就是每相临的两层之间节点之间是通过边全连接;再就是卷积神经网络,这个在计算机视觉里面用得非常多;再就是循环神经网络RNN,这个在对系列进行建模,例如自然语言处理或者语音信号里面用得很多,这些都是非常成功的深度神经网络的模型。还有一个非常重要的技术就是深度强化学习技术,这是深度学习和强化学习的结合,也是AlphaGo系统所采用的技术。
深度学习的成功主要归功于三大因素——大数据、大模型、大计算。现在可以利用的数据特别是人工标注的数据非常多,使得我们能够从数据中学到以前没法学习的东西。另外技术上的发展使得训练大模型成为了可能,例如上千层的深度神经网络,这个在四年以前都觉得不能想象的事情,现在都已经发展成为现实,并且在产品中都有了很广泛的使用。再就是大计算,从CPU到GPU,可获取的计算资源越来越丰富。
大数据、大模型、大计算是深度学习的三大支柱,因此这三个方向都是当前研究的热点,例如如何从更多更大的数据里面进行学习,如何训练更大更深的模型。非常深的模型,当前更成功的例子是在计算机视觉里面,但如何把这种更深的模型引入到自然语言处理里面,还需要研究,例如当前几个大公司的神经机器翻译模型,都是利用较深的RNN,但是还是远远达不到残差网络的深度。从大计算这个方面来讲,整个演变过程是从CPU到GPU到FPGA,再发展到现在有些公司定制自己专有芯片,国内的有一些创业公司,也都在做一些AI芯片,专门为AI来设计一些硬件。大计算另外一个角度就是深度学习的平台和系统,这个可以说是各大AI或者是互联网公司的着重发力的地方,例如微软的CNTK、DMTK,再比如TensorFlow、Torch,以及学术界的开源平台包括Theano、Caffe、MxNet等等。可以预计,在短期内,各大公司还会在这个领域做非常激烈的竞争,希望能够吸引第三方公司使用他们的平台和系统。
俗话说成也萧何败也萧何,大数据、大模型、大计算是深度学习成功的三大支柱因素,但他们同时也为深度学习的进一步发展和普及带来了一些制约因素。接下来,我会为大家介绍目前深度学习的五大挑战及其解决方案。
挑战1:标注数据代价昂贵
前沿1:从无标注的数据里学习
大家都知道,深度学习训练一个模型需要很多的人工标注的数据。例如在图象识别里面,经常我们可能需要上百万的人工标注的数据,在语音识别里面,我们可能需要成千上万小时的人工标注的数据,机器翻译更是需要数千万的双语句对做训练,在围棋里面DeepMind当初训练这个模型也用了数千万围棋高手走子的记录,这些都是大数据的体现。
但是,很多时候找专家来标注数据是非常昂贵的,并且对一些应用而言,很难找到大规模的标注的数据,例如一些疑难杂症,或者是一些比较稀有的应用场景。这里我们做一个粗略的分析,看看标注数据的代价有多高。比如说对机器翻译而言,现在如果我们请人工来翻译,一个单词的费用差不多是5—10美分之间,一个句子平均长度差不多是30个单词,如果我们需要标注一千万个双语句对,也就是我们需要找专家翻译一千万句话,这个标注的费用差不多是2200万美元。
大家可以看到数据标注的费用是非常非常高的,让一个创业公司或者一些刚刚涉足人工智能的公司拿这么大一笔资金来标注数据是很难或者是不太可行的。因此当前深度学习的一个前沿就是如何从无标注的数据里面进行学习。现在已经有相关的研究工作,包括最近比较火的生成式对抗网络,以及我们自己提出的对偶学习。

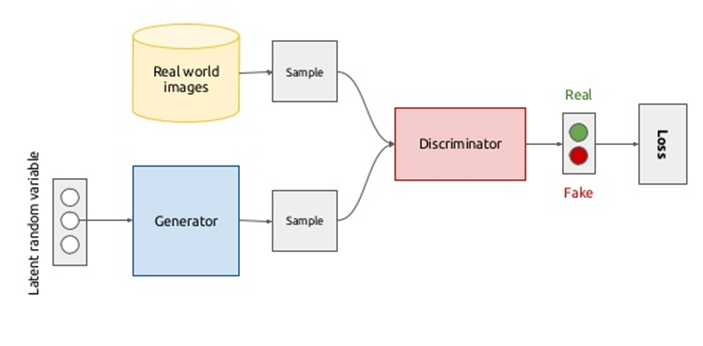
生成式对抗网络的主要目的是学到一个生成模型,这样它可以生成很多图像,这种图像看起来就像真实的自然图像一样。它解决这个问题的思路跟以前的方法不太一样,它是同时学习两个神经网络:一个神经网络生成图像,另外一个神经网络给图像进行分类,区分真实的图像和生成的图像。在生成式对抗网络里面,第一个神经网络也就是生成式神经网络,它的目的是希望生成的图像非常像自然界的真实图像,这样的话,那后面的第二个网络,也就是那个分类器没办法区分真实世界的图像和生成的图像;而第二个神经网络,也就是分类器,它的目的是希望能够正确的把生成的图像也就是假的图像和真实的自然界图像能够区分开。大家可以看到,这两个神经网络的目的其实是不一样的,他们一起进行训练,就可以得到一个很好的生成式神经网络。生成式对抗网络最初提出的时候,主要是对于图像的生成,现在很多人把他应用到各个不同的问题上,包括自然语言理解,比如说最近我们有一个工作,就是把这种思想应用到机器翻译里面,能够很大幅度的提高机器翻译的准确度。
针对如何从无标注的数据进行学习,我们组里面提出了一个新思路,叫做对偶学习。对偶学习的思路和前面生成式对抗学习会非常不一样。对偶学习的提出是受到一个现象的启发:我们发现很多人工智能的任务在结构上有对偶属性。比如说在机器翻译里面,我们把中文翻译成英文,这是一个任务,但是我们同样也需要把英文翻译成中文,这是一个对偶的任务。这种原任务和对偶任务之间,他们的输入和输出正好是反着来的。在语音处理里面,语音识别是把语音转化成文字,语音合成是把文字转化成语音,也是互为对偶的两个任务。在图像理解里面,看图说话,也就是给一张图生成一句描述性的语句,它的对偶任务是给一句话生成一张图,这两个任务一个是从图像到文本,另外一个是从文本到图像。在对话系统里面,回答问题和问题生成也是互为对偶的两个问题,前者是给定问题生成答案,后者是给定答案生成问题。在搜索引擎里面,给定检索词返回相关文档和给定文档或者广告返回关键词也是互为对偶的问题:搜索引擎最主要的任务是针对用户提交的检索词匹配一些文档,返回最相关的文档;当广告商提交一个广告之后,广告平台需要给他推荐一些关健词使得他的广告在用户搜索这些词能够展现出来被用户点击。
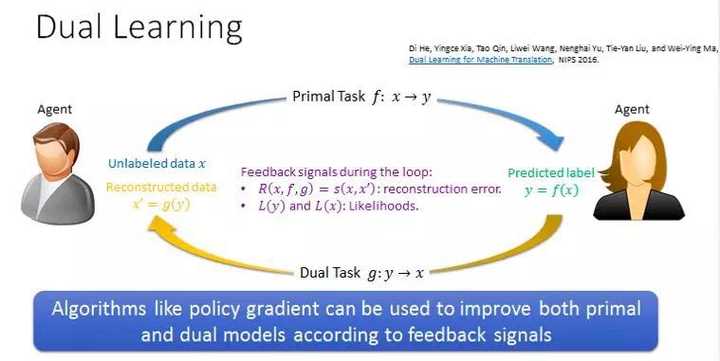
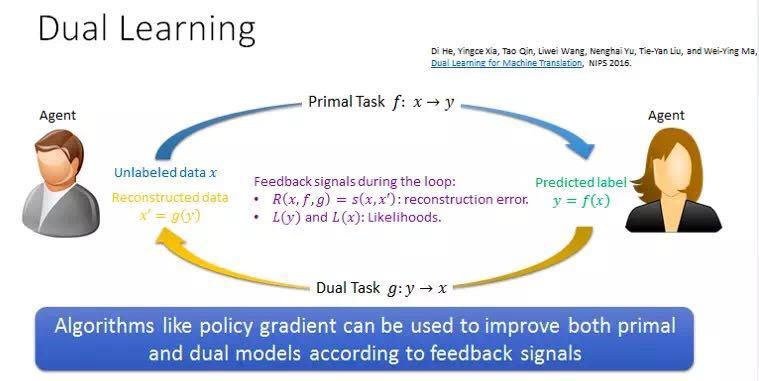
对偶学习试图把这种结构的对偶属性应用在机器学习里。其基本思想比较简单,我们以机器翻译为例子来说明。我们想把一个中文句子翻译成英文,我们可以先用一个中文到英文的翻译模型,把这个句子翻译成英文的句子,因为我们没有英文的标注,所以不知道这个英文的翻译是好还是坏以及有多好多坏。我们再利用从英文到中文的翻译模型,把这个英文的句子翻译成中文的句子,这样一来,我们就得到了一个新的中文句子。整个过程包含了正向翻译和反向翻译互为对偶的两个步骤。然后我们比较原始中文的句子和后来得到的中文句子,如果两个翻译模型都很好的话,这两个中文的句子应该比较相似,如果两个模型不好或者有一个模型不好的话,得到的两个中文句子就不相似。因此我们可以通过这种对偶过程从无标注的数据获得反馈信息,知道我们的模型工作的好还是不好,进而根据这些反馈信息来训练更新正向反向模型,从而达到从无标注数据学习的目的。
我们在机器翻译里面做了一些实验,发现通过对偶学习的过程,我们只需要用10%标注的数据(大概100万英法双语句对),再加上很多没有标注的数据,达到用100%标注数据(1200万英法双语句对)训练的模型的准确度。大家回想一下,我们前面有个粗略的估计,一千万个训练语料标注的费用差不多2200万美元,如果我们能把标注的人工费用从2200万美元降到200万美元,这会是一个非常好的结果,能够大大降低公司运营成本提高运营效率。
最近我们在对偶学习的研究上有一些新的进展,把对偶学习这种基本思想应用到其他的问题里面,像图像分类、图像生成,以及对自然语言的情感分析。我们发现这种结构的对偶属性可以从不同角度帮助机器学习,提高学习算法的准确度。
从无标注的数据进行学习,我们预计在未来三到五年还是非常重要的一个问题,并且对我们实际的应用也会有很大的帮助。很多问题以前是因为受限于没有标注的数据,没有办法用深度学习技术,如果我们能够从无标注的数据进行学习,那么很多应用很多问题里面都可以应用深度学习技术。
挑战2:大模型不方便在移动设备上使用
前沿2:降低模型大小
现在常见的模型,像图像分类里面,微软设计的深度残差网络,模型大小差不多都在500M以上。自然语言处理的一些模型,例如语言模型(language modeling)随着词表的增长而变大,可以有几G、几十G的大小,机器翻译的模型也都是500兆以上。当然500M的大小大家可能觉得没有多大,一个CPU服务器很容易就把这个模型给load进去使用。但是大家要注意到,很多时候深度学习的模型需要在一些移动设备上使用。比如说手机输入法,还有各种对图像做变换做处理做艺术效果的app,如果使用深度学习的话效果会非常好,但是这种模型由于它们的size太大,就不太适合在手机上应用。大家可以设想一下,如果一个手机的app需要加载一个500M甚至1G以上的模型恐怕不太容易被用户接受。
因此当前深度学习面临的第二个挑战就是如何把大模型变成小模型,这样可以在各种移动设备上使用。因为移动设备不仅仅是内存或者存储空间的限制,更多是因为能耗的限制,不允许我们用太大的模型。近两年来,有一些相应的工作,今天我主要介绍两种:第一种是针对计算机视觉里面的CNN模型,也就是卷积神经网络,做模型压缩;第二种是我们去年做的,针对一些序列模型或者类似自然语言处理的RNN模型如何做一个更巧妙的算法,使得它模型变小,并且同时精度没有损失。
- 通过模型压缩的技术缩减模型的大小
对卷积神经网络而言,近一两年有一些项目,主要是采用模型压缩的技术缩减模型的大小。模型压缩的技术,可以分为四类:
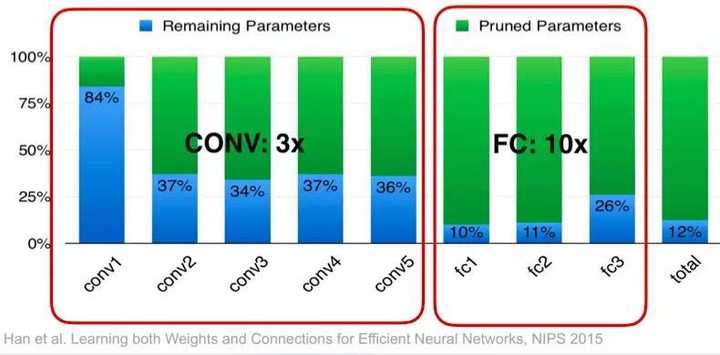
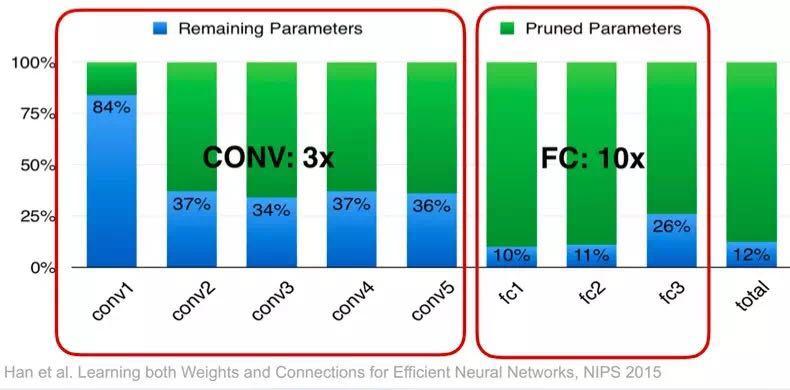
一个是叫剪枝,大家知道,神经网络主要是由一层一层的节点通过边连接,每个边上有些权重。剪枝的意思很简单,如果我们发现某些边上的权重很小,这样的边可能不重要,这些边就可以去掉。我们在把大模型训练完之后,看看哪些边的权重比较小,把这些边去掉,然后在保留的边上重新训练模型;
模型压缩的另外一种做法就是通过权值共享。假设相邻两层之间是全连接,每层有一千个节点,那么这两层之间有一千乘一千也就是一百万个权值(参数)。我们可以对一百万个权值做个聚类,看看哪些权值很接近,我们可以用每个类的均值来代替这些属于这一类的权值,这样很多边(如果他们聚在同一类)共享相同的权值。如果我们把一百万个数聚成一千类,就可以把参数的个数从一百万降到一千个,这也是一个非常重要的一个压缩模型大小的技术。
还有一个技术可以认为是权值共享的更进一步,叫量化。深度神经网络模型的参数都是用的浮点型的数表达,32bit长度的浮点型数。实际上没必要保留那么高的精度,我们可以通过量化,比如说就用0到255表达原来32个bit所表达的精度,通过牺牲精度来降低每一个权值所需要占用的空间。
这种量化的更极致的做法就是第四类的技术,叫二制神经网络。所谓二制神经网络,就是所有的权值不用浮点数表达了,就是一个二进制的数,要么是+1要么是-1,用二进制的方式来表达,这样原来一个32 bit权值现在只需要一个bit来表达,从而大大降低这个模型的尺寸。
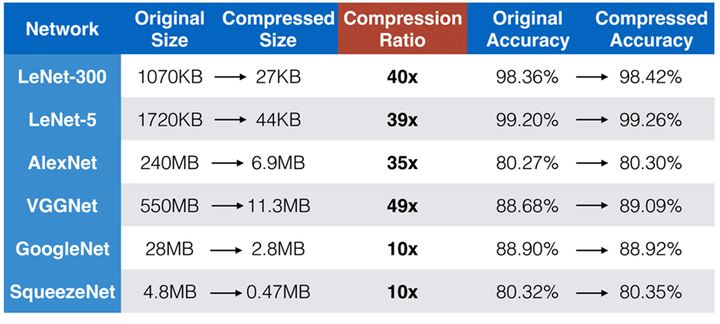
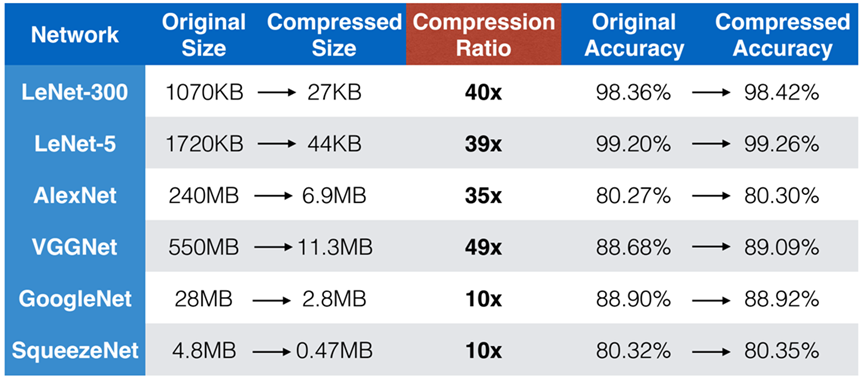
上面这张图显示了多种模型压缩的技术在不同卷积神经网络上的结果。我们可以看到,随着原始网络大小的不同,得到的压缩比是不一样的,特别是VGGNet,一个非常重要的卷积神经网络,能够把大小从原来的550M压缩到11M,并且让人惊奇的是,压缩后分类的准确率没有下降,反而略微有一点提高,这是非常了不起的。
- 通过设计更精巧的算法来降低模型大小
下面简单提一下我们组是如何对一些序列模型进行压缩,也就是对循环神经网络RNN做压缩,我们提了一种新的循环神经网络叫做LightRNN,它不是通过模型压缩的方式降低模型的大小,而是通过设计一种更精巧的算法来达到降低模型大小。
自然语言相关的应用中,模型之所以大,是因为我们需要把每一个词要做词嵌入(word embedding),把每一个单词表达成向量空间的一个向量。词嵌入的基本思想是,语义相似或相近的词在向量空间里面的向量也比较接近,这样就可以通过向量空间表达词之间的语义信息或者是相似性。因为通常我们的词表会很大,比如说在输入法里面,可能词表需要说上百万。如果我们词表有上百万的词,每个词如果是用一千维的一个向量来表达,这个大小就是差不多是一百万乘以一千再乘以4 Byte(用32位的浮点数来表达),词嵌入向量的总体大小差不多就有4G左右,所以整个RNN模型是非常大的。搜索引擎的词表有上千万的词,仅仅词嵌入向量这部分大小就有40G左右,考虑到输入的词嵌入和输出的词嵌入,整个词嵌入的大小有80G左右了,这么大的模型很难加载到GPU上训练模型和使用,更不用说放在移动设备上使用。
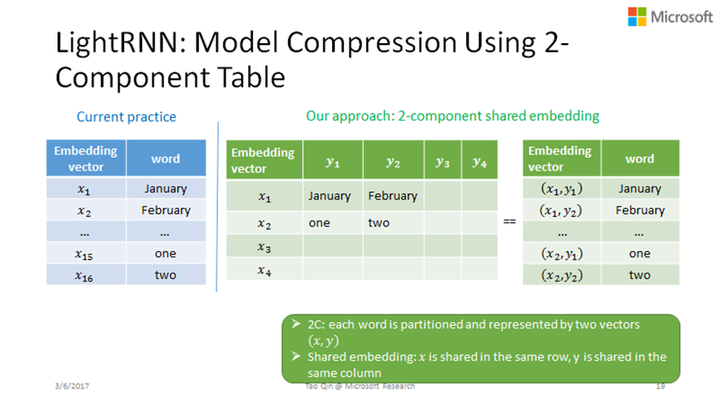
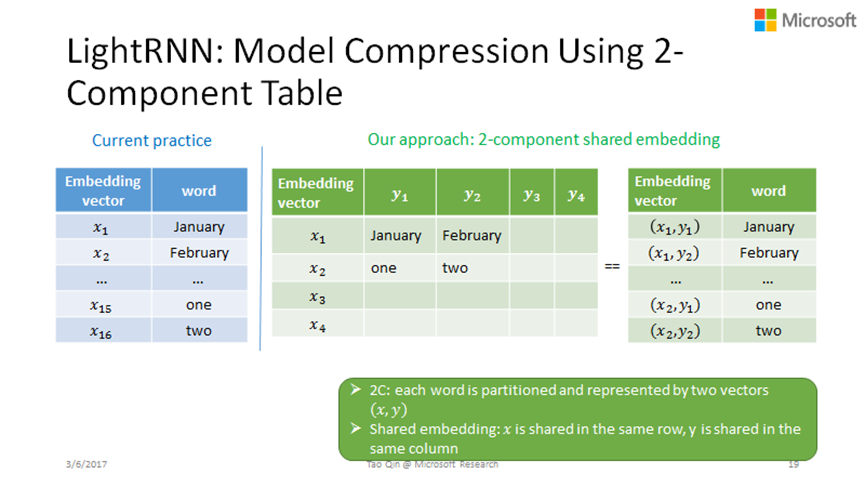
我们的算法的基本思想是:不是用一个向量来表达一个词,而是用两个向量表达一个词,一个行向量+一个列向量,不同的词之间共享行或列向量。我们用一个二维的表格来表达整个词表,假设这个二维的表格有一千行一千列,这个表格可以表达一百万个词;这个表格的每一行有一个行向量,每一列有一个列向量,这样整个二维表格只需要两千个向量。如果一个词(January)在第一行第一列的话,它就由行向量X1和列向量Y1来联合表达。考虑一个有一百万个词的词表,原来需要一百万个嵌入向量,通过这样一个二维或者是两个component的表格词嵌入,现在我们只需要一千个行向量和一千个列向量来进行表达,这样大大降低词嵌入向量模型的大小。
我们在很多公共的数据集上做测试,结果表明我们提出的LightRNN算法极大的减小了模型的尺寸,可以把原来语言模型的大小从4G降到40M左右,当这个模型只有40兆的时候,很容易使得我们在移动设备或者是GPU上使用。我们的方法使得深度模型在各种能耗比较低或者内存比较小的设备上的使用成为了可能。并且我们还发现,通过这样一种共享的二维词表的嵌入,我们得到的循环神经网络模型的精度并没有受到很大的影响,实际上LightRNN的精度反而略微有上升,和前面的卷积神经网络压缩的结果比较类似。
挑战3:大计算需要昂贵的物质、时间成本
前沿3:全新的硬件设计、算法设计、系统设计
大计算说起来容易,其实做起来非常不容易,非常不简单。我们微软亚洲研究院研究员提出深度残差网络,这种网络如果在ImageNet这样一个上百万的数据上进行训练的话,用四块现在最先进的GPU卡K80学习训练时间大概要三周。最近百度做的神经机器翻译系统,他们用了32块K40的GPU用了十天做训练,谷歌的机器翻译系统用了更多,用了96块K80的GPU训练了六天。大家可能都知道AlphaGo, 它也需要非常大量的计算资源。AlphaGo的模型包含一个策略神经网络,还有一个值网络,这两个都是卷积神经网络。它的策略网络用了50块GPU做训练,训练了3个周,值网络也是用了50块GPU,训练了一周,因此它整个的训练过程用了50块CPU四周时间,差不多一个月。大家可以想一想,如果训练一个模型就要等一个月,并且我们经常要调各种超参数,一组超参数得到的结果不好,换另外一组超参数,可能要尝试很多组超参数,如果我们没有大量的计算资源,一等就是一个月,这从产品的更新换代还有技术创新的角度而言,都不能接受。刚才说了只是AlphaGo训练的复杂度,其实它的测试,比如说比赛的时候,复杂度也非常高, AlphaGo的单机版和人下棋的时候,每次下棋需要用48块CPU 8块GPU,它的分布式版本就用的更多,每次需要用1200块CPU再加上176块GPU。大家可以想一想,地球上有几个公司能承受这么高昂的代价来做深度学习。
因此我们认为,深度学习所面临的第三个挑战是如何设计一些更高级的算法,更快的算法,更有效的算法。手段可能是通过一些全新的硬件设计或者是全新的算法设计,或者是全新的系统设计,使得这种训练能够大大的加速。如果我们还是这种训练动不动就要几十块GPU或者几百块GPU,要等几个星期或者是几个月的话,对工业界和学术界而言都不是好事,我们需要更快速更有效的训练方法。
挑战4:如何像人一样从小样本进行有效学习?
前沿4:数据+知识,深度学习与知识图谱、逻辑推理、符号学习相结合
现在的深度学习主要是从大数据进行学习,就是我给你很多标注的数据,使用深度学习算法学习得到一些模型。这种学习方式和人的智能是非常不一样的,人往往是从小样本进行学习。人对图像进行分类,如果人想知道一个图像是不是苹果,只需要很少几个样本就可以做到准确分类。两三岁小孩,开始认识世界的时候,他如果想知道什么样的动物是狗,我们给他看几张狗的图片,并且告诉他狗有什么特征,和其他动物像猫或者羊有什么区别的话,小孩可以很快很准确的识别狗。但是在ImageNet比赛里,像深度残差神经网络,一般来说一个类别大概需要上千张图片才能进行比较充分的训练,得到比较准确的结果。还有一个例子就是汽车驾驶,一般来说,通过在驾校的培训,也就是几十个小时的学习,几百公里的练习,大多数人就可以开车上路了,但是像现在的无人车可能已经行驶了上百万公里,还是达不到人的全自动驾驶的水平。原因在于,人经过有限的训练,结合规则和知识能够应付各种复杂的路况,但是当前的AI还没有逻辑思考、联想和推理的能力,必须靠大数据来覆盖各种可能的路况,但是各种可能的路况几乎是无穷的。
前面提到的小孩子认识世界的过程,很多时候,大人可以把一些经验或者是知识传授给他们,比如说苹果是圆形的,有红色的或者青的苹果,狗和猫的区别在什么地方。这种知识很容易通过语言进行传授,但是对于一个AI或者对于一个深度学习算法而言,如何把这种知识转化成实际模型的一部分,怎么把数据和知识结合起来,提高模型的训练的速度或者是识别的精度,这是一个很复杂的问题。
现在我们组有同事正在做这方面的尝试和努力,我们希望把深度学习、知识图谱、逻辑推理、符号学习等等结合起来,希望能够进一步推动人工智能的发展,使人工智能更接近人的智能。
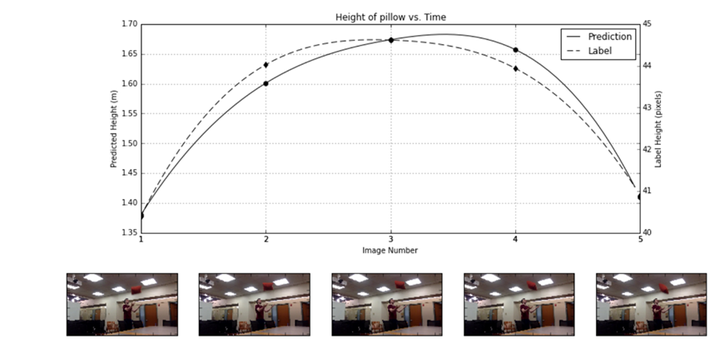
今年的人工智能国际顶级会议AAAI 2017的最佳论文奖,颁给了一个利用物理或者是一些领域的专业知识来帮助深度神经网络做无标注数据学习的项目。论文里的具体例子是上面这张图里面一个人扔枕头的过程,论文想解决的问题是从视频里检测这个枕头,并且跟踪这个枕头的运动轨迹。如果我们没有一些领域的知识,就需要大量的人工标注的数据,比如说把枕头标注出来,每帧图像的哪块区域是枕头,它的轨迹是什么样子的。实际上因为我们知道,枕头的运动轨迹应该是抛物线,二次型,结合这种物理知识,我们就不需要标注的数据,能够把这个枕头给检测出来,并且把它的轨迹准确的预测出来。这篇论文之所以获得了最佳论文奖,也是因为它把知识和数据结合起来,实现了从无标注数据进行学习的可能。
挑战5:如何从认知性的任务扩展到决策性任务?
前沿5:博弈机器学习
人的智能包含了很多方面,最基本的阶段是认知性智能,也就是对整个世界的认知。我们看到一幅图能知道里面有什么,我们听到一句话知道在说文字。现在对于图象识别、语音识别,AI已经差不多能达到人类的水平,当然可能是在某些特定的约束条件下,能够达到人类的水平。但是其实这种认知性的任务,对人类而言都是非常简单的,比如说一个三五岁的小孩子已经能做得很好了,现在AI所能做的这种事情或者能达到的水平,人其实也很容易做到,只是AI可能在速度上更快,并且规模上去之后成本更低,并且24小时都不需要休息。更有挑战的问题是,人工智能能不能做一些人类做不了或者是很难做好的事情。
像图象识别、语音识别这类认知性的任务,AI之所以做得好,是因为这些任务是静态的,所谓静态就是给定输入,预测结果不会随着时间改变。但是决策性问题,往往和环境有很复杂的交互,在某些场景里面,如何做最优决策,这些最优决策往往是动态的,会随着时间改变。
现在有人尝试把AI用到金融市场,例如如何用AI技术来分析股票,预测股票涨跌,对股票交易给出建议,甚至是代替人来进行股票交易,这类问题就是动态决策性问题。同样一支股票同样的价格,在一周前可能是值得买入,但是一周之后可能就要卖出了,同样一个事件或者是政治新闻比如说是在总统大选之前发生还是之后发生,对股票市场的影响也完全不一样。所以决策问题的一个难点就在于时变性。
决策性问题的第二个难点在于各种因素相互影响,牵一发而动全身。一支股票的涨跌会对其他股票产生影响,一个人的投资决策,特别是大的机构的投资决策,可能会对整个市场产生影响,这就和静态的认知性任务不一样的。在静态认知性任务我们的预测结果不会对问题(例如其他的图像或者语音)产生任何影响,但是在股票市场,任何一个决定,特别是大的机构的投资策略会对整个市场产生影响,对别的投资者产生影响,对将来会产生影响。无人驾驶某种程度上也是比较类似的,一辆无人车在路上怎么行驶,是由环境和很多车辆共同决定的,当我们通过AI来控制一辆车的时候,我们需要关注周围的车辆,因为我们要考虑到周围的车辆对于当前这个无人车的影响,以及我们无人车(如左转右转或者并线)对周围车辆的影响。
当前深度学习已经在静态任务里面取得了很大的成功,如何把这种成功延续和扩展到这种复杂的动态决策问题中,也是当前一个深度学习的挑战之一。我们认为,一个可能的思路是博弈机器学习。在博弈机器学习里,通过观察环境和其他个体的行为,对每个个体构建不同的个性化行为模型,AI就可以三思而后行,选择一个最优策略,该策略会自适应环境的变化和其他个体的行为的改变。
最后,我们做一个简单的总结,在我们看来,当前深度学习的前沿(也是面临的挑战)有以下几个方面,一个是如何从大量的无标注的数据进行学习,二是如何得到一些比较小的模型使得深度学习技术能够在移动设备和各种场所里面得到更广泛的应用,三是如何设计更快更高效的深度学习算法,四是如何把数据和知识结合起来,五是如何把深度学习的成功从一些静态的任务扩展到复杂的动态决策性任务上去。实际上深度学习还有其他一些前沿研究方向,例如如何自主学习(自主学习超参数、网络结构等)以及如何实现通用人工智能等等,限于时间,不能一一介绍。感兴趣的知友们可以自行查阅相关论文。
————更新的分割线————
2017.03.10 21:23更新
看到知友@ 雾雨魔理沙 的提问“ 你好,请问Dual Network跟Auto Encoder有什么相似/不同点? ”,秦涛博士刚刚做出了补充回答。
回复较长,请包涵。
简而言之,Autoencoder的做法和对偶学习很类似。Autoencoder的encoder可以看作对偶学习里的正向模型,decoder可以看作对偶学习里的反向模型。在我们看来,对偶学习的思想更广泛一些(可能大多数做研究的人喜欢拔高自己的工作^_^),autoencoder可以看作对偶学习的一个special case:
- 1.对偶学习中的两个任务可以是实际的物理世界的AI任务例如语音识vs语音合成以及中翻英vs英翻中,也可以是虚拟的任务如Autoencoder里的encoder和decoder。autoencoder学习完成后实际有用的是encoder,这个encoder可以用来降维,它的输出也可以其他分类器的输入;而decoder一般在学习完成后一般没有实际用处。如果两个task都是物理世界的任务,那么对偶学习到的两个模型都是实际用处,例如中翻英的模型和英翻中的模型。
- 2.对偶学习可以推广到多于两个任务,例如中翻英+英翻法+法翻中,图像转文本+文本转语音+语音转图像,只要这些任务能够形成闭环提供反馈,对偶学习就可以应用。
- 3.对偶学习可以从无标注数据学习也可以从标注数据学习,其基本思想在于联合概率P(x,y)有两种计算方式,分别涉及到了正向和反向模型,这样两个计算方式的结果应该相等
我们可以利用这个概率等式正则化从标注数据学习的过程,具体如下图所示,我们把这种做法叫做对偶监督学习 (dual supervised learning)。
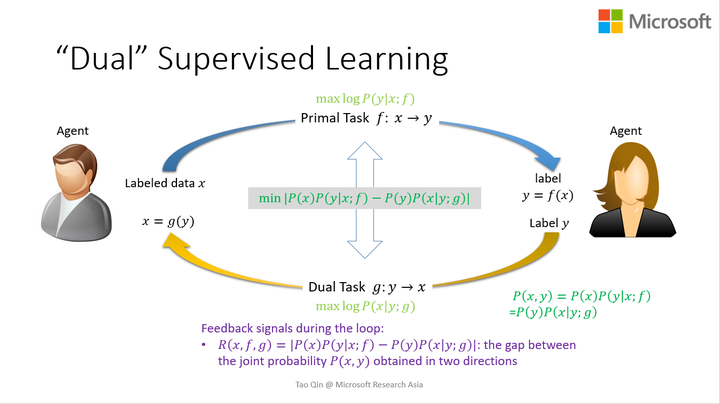
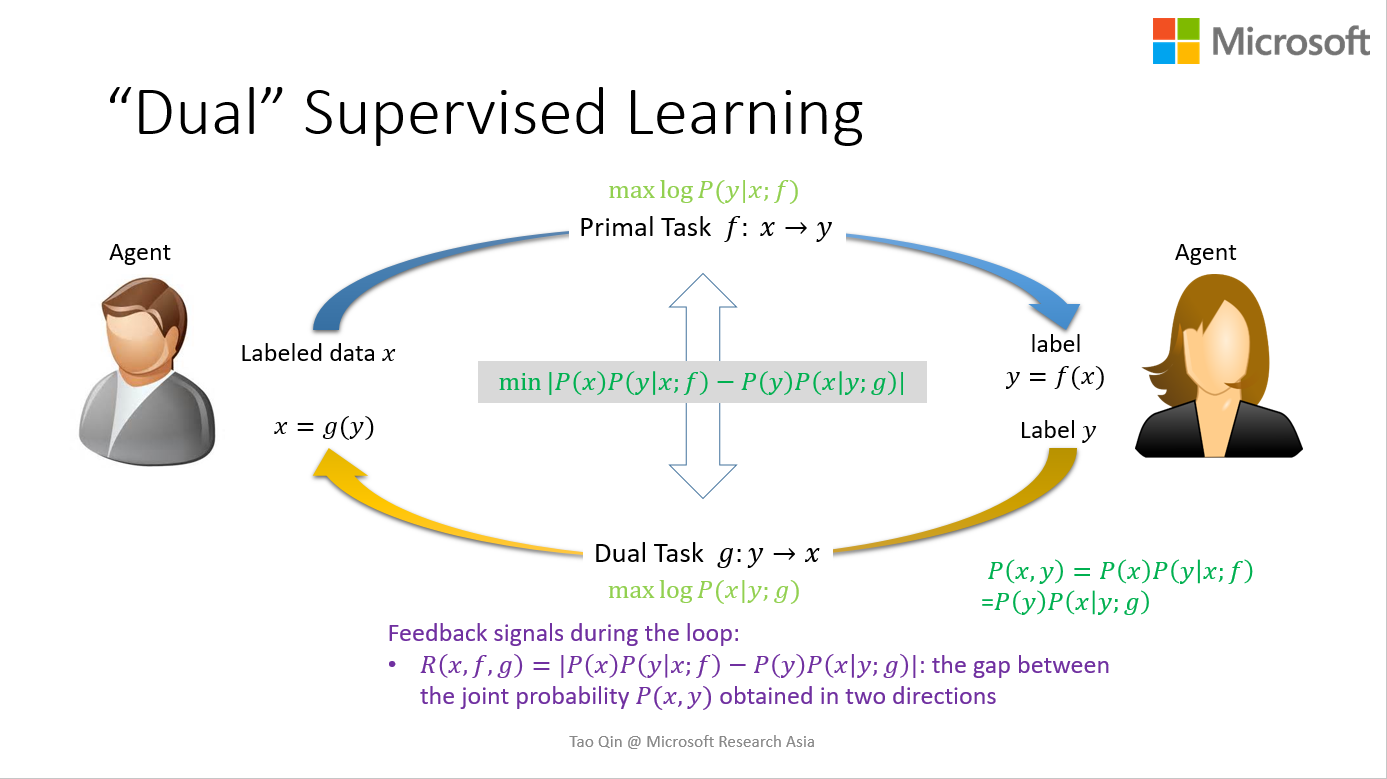
- 4.对偶学习可以用来在训练过程中提高两个模型,也可以用在测试过程中。举个例子,给定一个中文的句子x, 神经机器翻译中标准的测试是找的一个能最大化概率P(y|x;f)的英文句子y做为x的翻译。当我们有了正向和反向两个模型后,我们可以找一个能同时最大化两个概率, P(y|x;f)和P(x|y;g)P(y)/P(x), 或者这两个概率的线性组合的英文句子y作为x的翻译。在这里,我们只是利用结构对偶属性改进测试的过程,并没有影响模型的训练,我们把这种做法就做对偶测试(dual inference)。
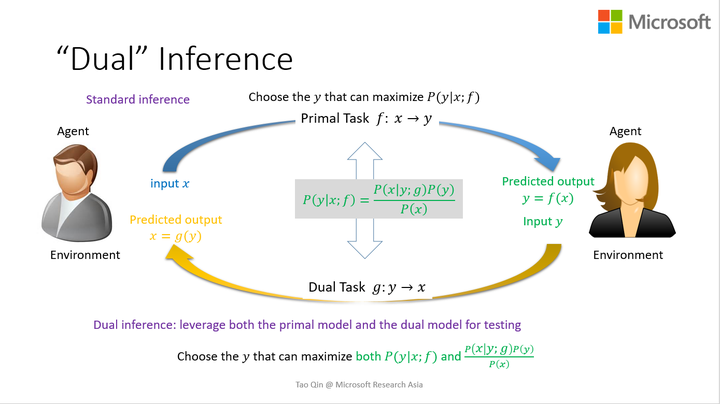
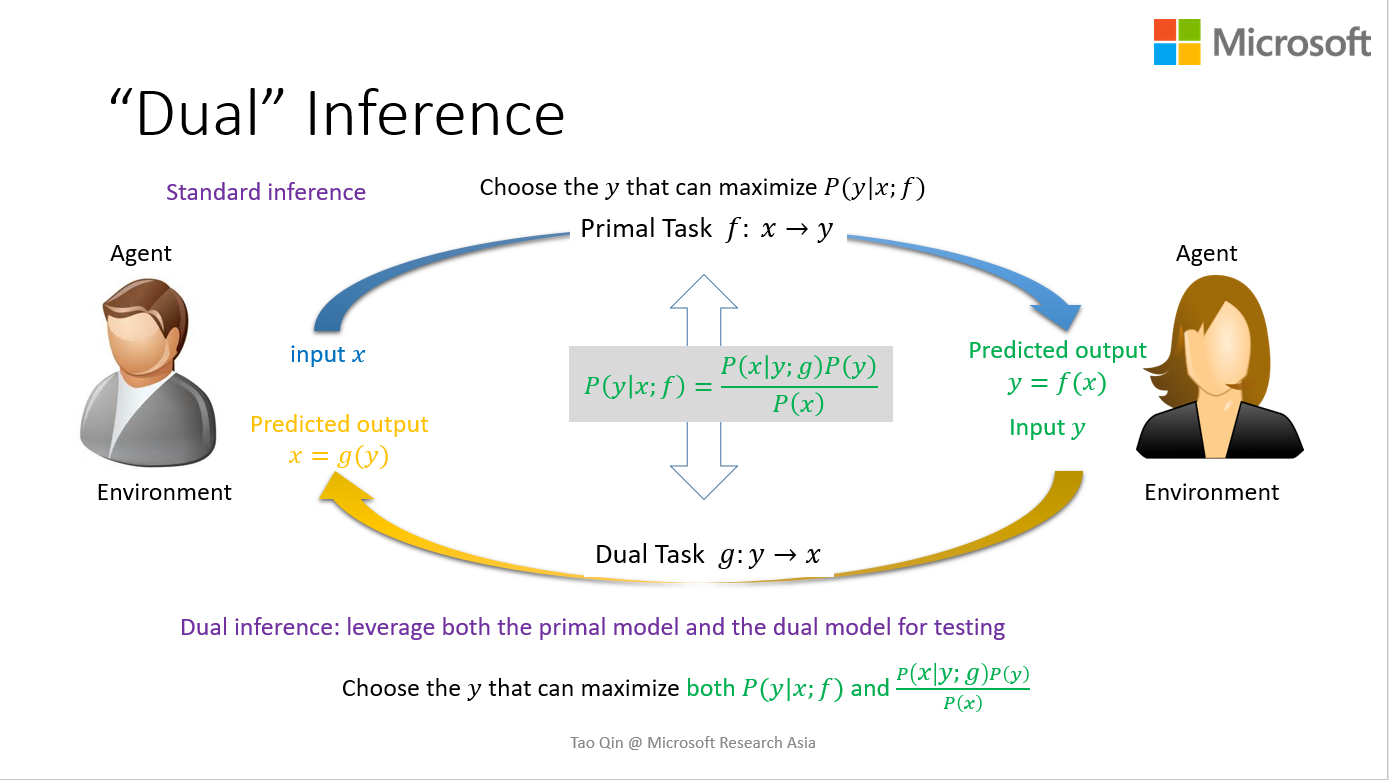
2017.03.13 22:00更新
回复:@彭也 "请问模型压缩之后,Accuracy反倒有提高应该如何解释?可否认为压缩的过程减少了模型本身的“噪音”,类似数据前处理?"
模型压缩后accuracy反而提高,正如你所说,一个可能的解释是降噪,就是把模型里的噪声去除。对于LightRNN,我在另外一篇文章“LightRNN:深度学习之以小见大”里做了一些解释,摘抄如下:
有读者可能会好奇,为什么在减小模型的同时,LightRNN还能达到更好的精度。原因在于共享嵌入。标准RNN假设每个词都有一个独立的向量表达;LightRNN中很多词会共享行或者列向量,二维词表的行列向量都是从数据里学习得到的,并且哪些词在同一行或同一列也是学习得到的,因此LightRNN能够发现词表中的一些语义。如下表所示,通过训练,LightRNN把很多有语义关联的词放在同一行,如832行都是地名,852行都是数字,861行都是数字+单位,872行都是被动分词,877行都是动词第三人称单数形式,等等。也就是说,LightRNN的二维词表的共享行列向量比标准RNN的独立向量更能发现词之间的语义关联。其次,通过让有语义关联的词共享行或列向量,可以使低频的词的向量表达得到更充分的训练。例如44kg这个词在语料库里出现的次数较少,在标准RNN里它的嵌入向量学习不充分,而在LightRNN里,这个词的行向量由同一行的所有词共同训练,它的列向量也由同一列的所有词共同训练,相当于增加了这个词的训练数据,因此能够提高语言模型的精度。


回复:@M Troy “您好,个人的一点愚见:对偶学习可以应用在机器翻译中的一点原因是两个语言互相翻译的任务,信息量基本是对等的。那么如果应用在“图像识别vs图像生成”中,如何解决信息量不对等的问题?”
总结得很对,目前对偶无监督学习更适合信息(语义)几乎无损的正反任务,因为如果某个方向的映射有信息损失(如图像识别),那么反向就很难重建原始的输入(如图像生成)。对偶监督学习则没有这个问题,对信息有损的正反向任务也能使用,我们有一个这样的工作已完成,过一段时间会放到网上。我们正在研究如何把对偶无监督学习应用到有损的任务上,如“图像识别vs图像生成”,现在只有一些初步的不成熟的想法。
回复:刘飞 “一些主要文献”
Goodfellow, Ian, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio, Generative adversarial nets, NIPS 2014.
Xiang Li, Tao Qin, Jian Yang, and Tie-Yan Liu, LightRNN: Memory and Computation-Efficient Recurrent Neural Networks, NIPS 2016.
Han, Song, Huizi Mao, and William J. Dally, Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding, ICLR 2016. Di He, Yingce Xia, Tao Qin, Liwei Wang, Nenghai Yu, Tie-Yan Liu, and Wei-Ying Ma, Dual Learning for Machine Translation, NIPS 2016.
Stewart, Russell, and Stefano Ermon, Label-free supervision of neural networks with physics and domain knowledge, AAAI 2017.
标签:机器,模型,学习,神经网络,深度,标注,对偶 来源: https://www.cnblogs.com/dhcn/p/15756286.html