Dubbo3 应用级服务发现
作者:互联网
https://dubbo.apache.org/zh/blog/2021/06/02/dubbo3-应用级服务发现/
本文介绍了 Dubbo3 应用级服务发现的实现原理 Wednesday, June 02, 20211 服务发现(Service Discovery) 概述
从 Internet 刚开始兴起,如何动态感知后端服务的地址变化就是一个必须要面对的问题,为此人们定义了 DNS 协议,基于此协议,调用方只需要记住由固定字符串组成的域名,就能轻松完成对后端服务的访问,而不用担心流量最终会访问到哪些机器 IP,因为有代理组件会基于 DNS 地址解析后的地址列表,将流量透明的、均匀的分发到不同的后端机器上。
在使用微服务构建复杂的分布式系统时,如何感知 backend 服务实例的动态上下线,也是微服务框架最需要关心并解决的问题之一。业界将这个问题称之为 - 微服务的地址发现(Service Discovery),业界比较有代表性的微服务框架如 SpringCloud、Microservices、Dubbo 等都抽象了强大的动态地址发现能力,并且为了满足微服务业务场景的需求,绝大多数框架的地址发现都是基于自己设计的一套机制来实现,因此在能力、灵活性上都要比传统 DNS 丰富得多。如 SpringCloud 中常用的 Eureka, Dubbo 中常用的 Zookeeper、Nacos 等,这些注册中心实现不止能够传递地址(IP + Port),还包括一些微服务的 Metadata 信息,如实例序列化类型、实例方法列表、各个方法级的定制化配置等。
下图是微服务中 Service Discovery 的基本工作原理图,微服务体系中的实例大概可分为三种角色:服务提供者(Provider)、服务消费者(Consumer)和注册中心(Registry)。而不同框架实现间最主要的区别就体现在注册中心数据的组织:地址如何组织、以什么粒度组织、除地址外还同步哪些数据?
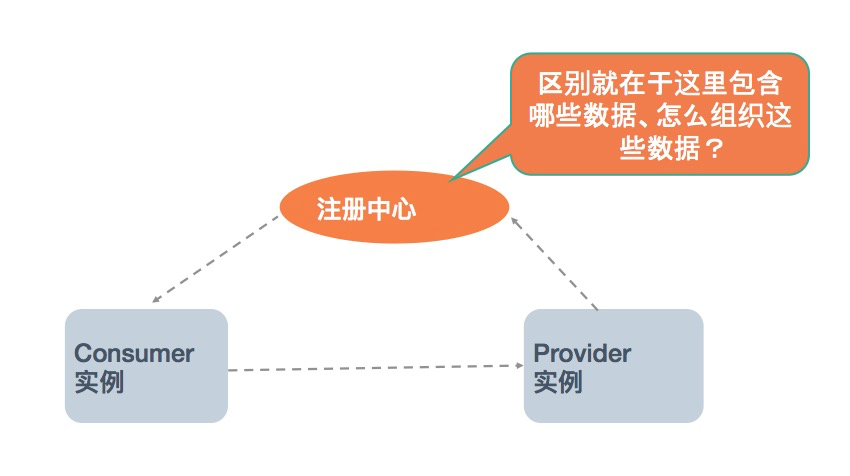
我们今天这篇文章就是围绕这三个角色展开,重点看下 Dubbo 中对于服务发现方案的设计,包括之前老的服务发现方案的优势和缺点,以及 Dubbo 3.0 中正在设计、开发中的全新的面向应用粒度的地址发现方案,我们期待这个新的方案能做到:
- 支持几十万/上百万级集群实例的地址发现
- 与不同的微服务体系(如 Spring Cloud)实现在地址发现层面的互通
2 Dubbo 地址发现机制解析
我们先以一个 DEMO 应用为例,来快速的看一下 Dubbo “接口粒度”服务发现与“应用粒度”服务发现体现出来的区别。这里我们重点关注 Provider 实例是如何向注册中心注册的,并且,为了体现注册中心数据量变化,我们观察的是两个 Provider 实例的场景。
应用 DEMO 提供的服务列表如下:
<dubbo:service interface="org.apache.dubbo.samples.basic.api.DemoService" ref="demoService"/>
<dubbo:service interface="org.apache.dubbo.samples.basic.api.GreetingService" ref="greetingService"/>
我们示例注册中心实现采用的是 Zookeeper ,启动 192.168.0.103 和 192.168.0.104 两个实例后,以下是两种模式下注册中心的实际数据
1. “接口粒度” 服务发现
192.168.0.103 实例注册的数据
dubbo://192.168.0.103:20880/org.apache.dubbo.samples.basic.api.DemoService?anyhost=true&application=demo-provider&default=true&deprecated=false&dubbo=2.0.2&dynamic=true&generic=false&interface=org.apache.dubbo.samples.basic.api.DemoService&methods=testVoid,sayHello&pid=995&release=2.7.7&side=provider×tamp=1596988171266
dubbo://192.168.0.103:20880/org.apache.dubbo.samples.basic.api.GreetingService?anyhost=true&application=demo-provider&default=true&deprecated=false&dubbo=2.0.2&dynamic=true&generic=false&interface=org.apache.dubbo.samples.basic.api.GreetingService&methods=greeting&pid=995&release=2.7.7&side=provider×tamp=1596988170816
192.168.0.104 实例注册的数据
dubbo://192.168.0.104:20880/org.apache.dubbo.samples.basic.api.DemoService?anyhost=true&application=demo-provider&default=true&deprecated=false&dubbo=2.0.2&dynamic=true&generic=false&interface=org.apache.dubbo.samples.basic.api.DemoService&methods=testVoid,sayHello&pid=995&release=2.7.7&side=provider×tamp=1596988171266
dubbo://192.168.0.104:20880/org.apache.dubbo.samples.basic.api.GreetingService?anyhost=true&application=demo-provider&default=true&deprecated=false&dubbo=2.0.2&dynamic=true&generic=false&interface=org.apache.dubbo.samples.basic.api.GreetingService&methods=greeting&pid=995&release=2.7.7&side=provider×tamp=1596988170816
2. “应用粒度” 服务发现
192.168.0.103 与 192.168.0.104 两个实例共享一份注册中心数据,如下:
{
"name": "demo-provider",
"id": "192.168.0.103:20880",
"address": "192.168.0.103",
"port": 20880,
"metadata": {
"dubbo.endpoints": "[{\"port\":20880,\"protocol\":\"dubbo\"}]",
"dubbo.metadata.storage-type": "local",
"dubbo.revision": "6785535733750099598"
},
"time": 1583461240877
}
{
"name": "demo-provider",
"id": "192.168.0.104:20880",
"address": "192.168.0.104",
"port": 20880,
"metadata": {
"dubbo.endpoints": "[{\"port\":20880,\"protocol\":\"dubbo\"}]",
"dubbo.metadata.storage-type": "local",
"dubbo.revision": "7829635812370099387"
},
"time": 1583461240877
}
对比以上两种不同粒度的服务发现模式,从 “接口粒度” 升级到 “应用粒度” 后我们可以总结出最大的区别是:注册中心数据量不再与接口数成正比,不论应用提供有多少接口,注册中心只有一条实例数据。
那么接下来我们详细看下这个变化给 Dubbo 带来了哪些好处。
3 Dubbo 应用级服务发现的意义
我们先说结论,应用级服务发现给 Dubbo 带来以下优势:
- 与业界主流微服务模型对齐,比如 SpringCloud、Kubernetes Native Service等。
- 提升性能与可伸缩性。注册中心数据的重新组织(减少),能最大幅度的减轻注册中心的存储、推送压力,进而减少 Dubbo Consumer 侧的地址计算压力;集群规模也开始变得可预测、可评估(与 RPC 接口数量无关,只与实例部署规模相关)。
3.1 对齐主流微服务模型
自动、透明的实例地址发现(负载均衡)是所有微服务框架需要解决的事情,这能让后端的部署结构对上游微服务透明,上游服务只需要从收到的地址列表中选取一个,发起调用就可以了。要实现以上目标,涉及两个关键点的自动同步:
- 实例地址,服务消费方需要知道地址以建立连接
- RPC 方法定义,服务消费方需要知道 RPC 服务的具体定义,不论服务类型是 rest 或 rmi 等。

对于 RPC 实例间借助注册中心的数据同步,REST 定义了一套非常有意思的成熟度模型,感兴趣的朋友可以参考这里的链接 https://www.martinfowler.com/articles/richardsonMaturityModel.html, 按照文章中的 4 级成熟度定义,Dubbo 当前基于接口粒度的模型可以对应到 L4 级别。
接下来,我们看看 Dubbo、SpringCloud 以及 Kubernetes 分别是怎么围绕自动化的实例地址发现这个目标设计的。
1. Spring Cloud
Spring Cloud 通过注册中心只同步了应用与实例地址,消费方可以基于实例地址与服务提供方建立连接,但是消费方对于如何发起 http 调用(SpringCloud 基于 rest 通信)一无所知,比如对方有哪些 http endpoint,需要传入哪些参数等。
RPC 服务这部分信息目前都是通过线下约定或离线的管理系统来协商的。这种架构的优缺点总结如下。 优势:部署结构清晰、地址推送量小; 缺点:地址订阅需要指定应用名, provider 应用变更(拆分)需消费端感知;RPC 调用无法全自动同步。

2. Dubbo
Dubbo 通过注册中心同时同步了实例地址和 RPC 方法,因此其能实现 RPC 过程的自动同步,面向 RPC 编程、面向 RPC 治理,对后端应用的拆分消费端无感知,其缺点则是地址推送数量变大,和 RPC 方法成正比。

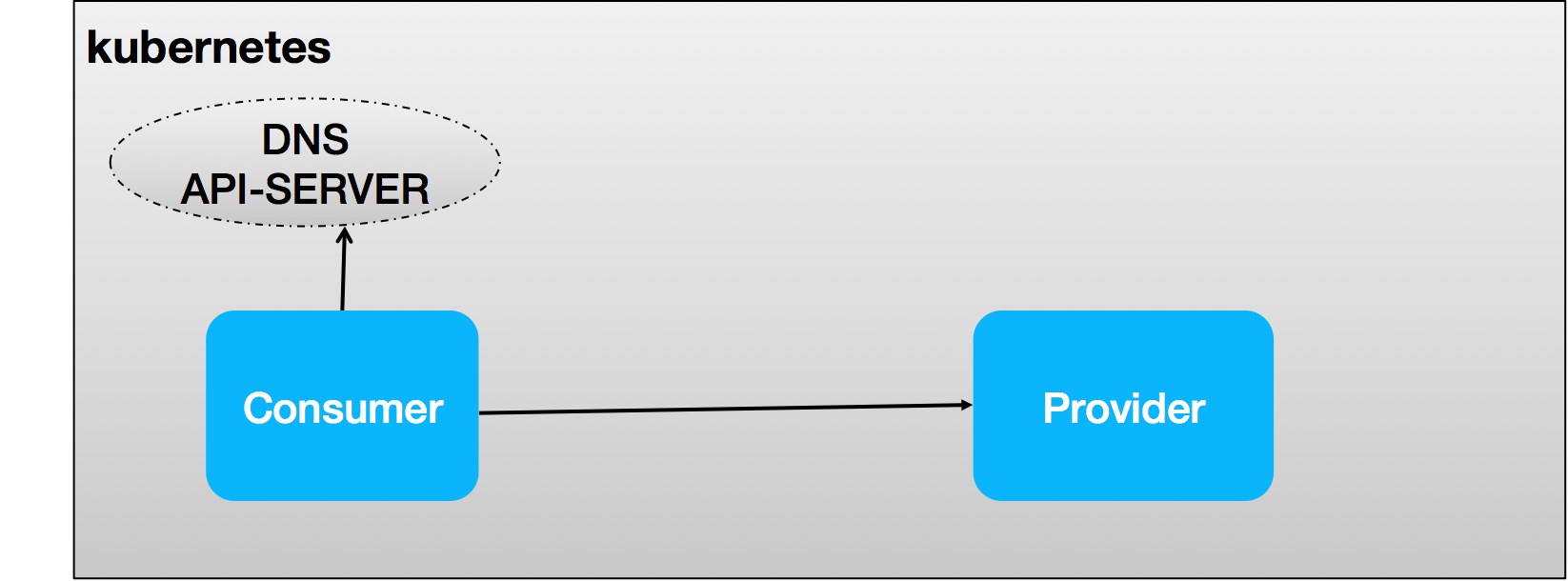
3. Dubbo + Kubernetes
Dubbo 要支持 Kubernetes native service,相比之前自建注册中心的服务发现体系来说,在工作机制上主要有两点变化:
- 服务注册由平台接管,provider 不再需要关心服务注册
- consumer 端服务发现将是 Dubbo 关注的重点,通过对接平台层的 API-Server、DNS 等,Dubbo client 可以通过一个 Service Name(通常对应到 Application Name)查询到一组 Endpoints(一组运行 provider 的 pod),通过将 Endpoints 映射到 Dubbo 内部地址列表,以驱动 Dubbo 内置的负载均衡机制工作。
Kubernetes Service 作为一个抽象概念,怎么映射到 Dubbo 是一个值得讨论的点
- Service Name - > Application Name,Dubbo 应用和 Kubernetes 服务一一对应,对于微服务运维和建设环节透明,与开发阶段解耦。
apiVersion: v1 kind: Service metadata: name: provider-app-name spec: selector: app: provider-app-name ports: - protocol: TCP port: targetPort: 9376
- Service Name - > Dubbo RPC Service,Kubernetes 要维护调度的服务与应用内建 RPC 服务绑定,维护的服务数量变多。
--- apiVersion: v1 kind: Service metadata: name: rpc-service-1 spec: selector: app: provider-app-name ports: ## ... --- apiVersion: v1 kind: Service metadata: name: rpc-service-2 spec: selector: app: provider-app-name ports: ## ... --- apiVersion: v1 kind: Service metadata: name: rpc-service-N spec: selector: app: provider-app-name ports: ## ...
结合以上几种不同微服务框架模型的分析,我们可以发现,Dubbo 与 SpringCloud、Kubernetes 等不同产品在微服务的抽象定义上还是存在很大不同的。SpringCloud 和 Kubernetes 在微服务的模型抽象上还是比较接近的,两者基本都只关心实例地址的同步,如果我们去关心其他的一些服务框架产品,会发现它们绝大多数也是这么设计的;
即 REST 成熟度模型中的 L3 级别。
对比起来 Dubbo 则相对是比较特殊的存在,更多的是从 RPC 服务的粒度去设计的。
对应 REST 成熟度模型中的 L4 级别。
如我们上面针对每种模型做了详细的分析,每种模型都有其优势和不足。而我们最初决定 Dubbo 要做出改变,往其他的微服务发现模型上的对齐,是我们最早在确定 Dubbo 的云原生方案时,我们发现要让 Dubbo 去支持 Kubernetes Native Service,模型对齐是一个基础条件;另一点是来自用户侧对 Dubbo 场景化的一些工程实践的需求,得益于 Dubbo 对多注册、多协议能力的支持,使得 Dubbo 联通不同的微服务体系成为可能,而服务发现模型的不一致成为其中的一个障碍,这部分的场景描述请参见以下文章:Dubbo 如何成为连接异构微服务体系的最佳服务开发框架
3.2 更大规模的微服务集群 - 解决性能瓶颈
这部分涉及到和注册中心、配置中心的交互,关于不同模型下注册中心数据的变化,之前原理部分我们简单分析过。为更直观的对比服务模型变更带来的推送效率提升,我们来通过一个示例看一下不同模型注册中心的对比:
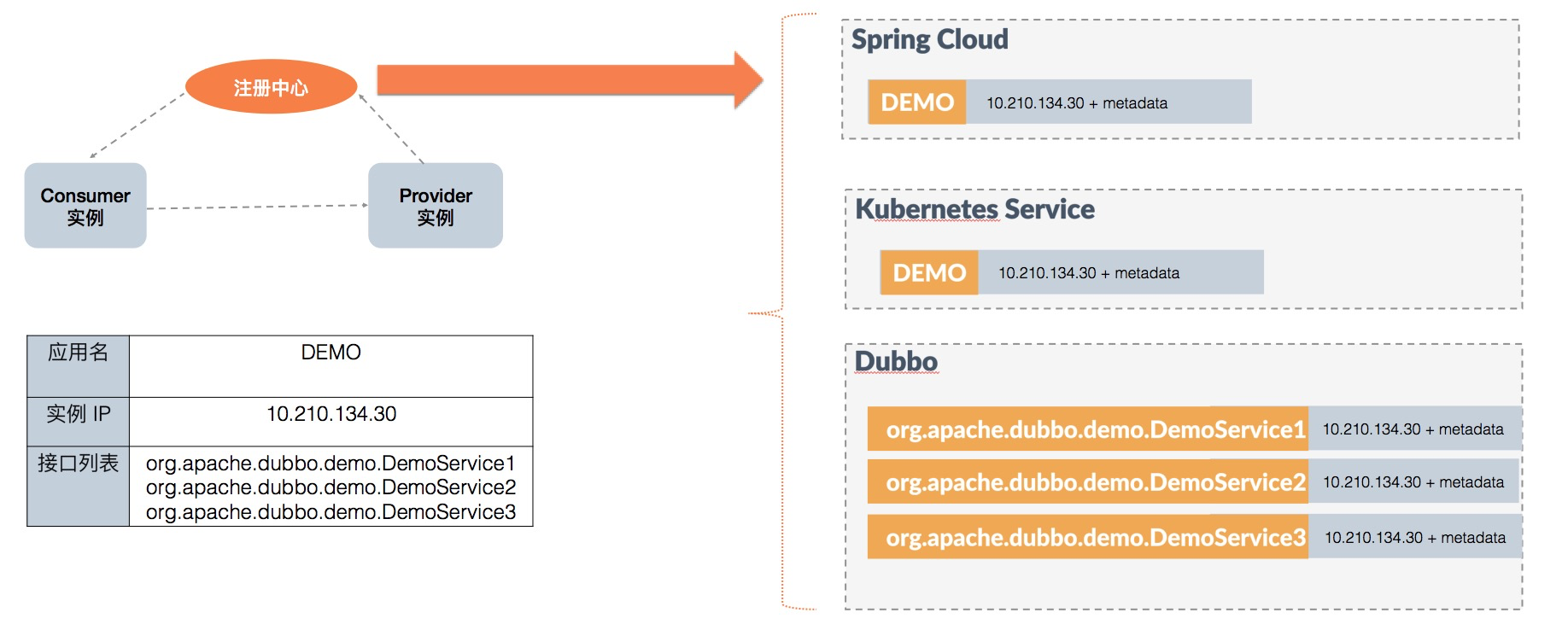
图中左边是微服务框架的一个典型工作流程,Provider 和 Consumer 通过注册中心实现自动化的地址通知。其中,Provider 实例的信息如图中表格所示: 应用 DEMO 包含三个接口 DemoService 1 2 3,当前实例的 ip 地址为 10.210.134.30。
- 对于 Spring Cloud 和 Kubernetes 模型,注册中心只会存储一条
DEMO - 10.210.134.30+metadata的数据; - 对于老的 Dubbo 模型,注册中心存储了三条接口粒度的数据,分别对应三个接口 DemoService 1 2 3,并且很多的址数据都是重复的;
可以总结出,基于应用粒度的模型所存储和推送的数据量是和应用、实例数成正比的,只有当我们的应用数增多或应用的实例数增长时,地址推送压力才会上涨。 而对于基于接口粒度的模型,数据量是和接口数量正相关的,鉴于一个应用通常发布多个接口的现状,这个数量级本身比应用粒度是要乘以倍数的;另外一个关键点在于,接口粒度导致的集群规模评估的不透明,相对于实例、应用增长都通常是在运维侧的规划之中,接口的定义更多的是业务侧的内部行为,往往可以绕过评估给集群带来压力。
以 Consumer 端服务订阅举例,根据我对社区部分 Dubbo 中大规模头部用户的粗略统计,根据受统计公司的实际场景,一个 Consumer 应用要消费(订阅)的 Provier 应用数量往往要超过 10 个,而具体到其要消费(订阅)的的接口数量则通常要达到 30 个,平均情况下 Consumer 订阅的 3 个接口来自同一个 Provider 应用,如此计算下来,如果以应用粒度为地址通知和选址基本单位,则平均地址推送和计算量将下降 60% 还要多, 而在极端情况下,也就是当 Consumer 端消费的接口更多的来自同一个应用时,这个地址推送与内存消耗的占用将会进一步得到降低,甚至可以超过 80% 以上。
一个典型的极端场景即是 Dubbo 体系中的网关型应用,有些网关应用消费(订阅)达 100+ 应用,而消费(订阅)的服务有 1000+ ,平均有 10 个接口来自同一个应用,如果我们把地址推送和计算的粒度改为应用,则地址推送量从原来的 n * 1000 变为 n * 100,地址数量降低可达近 90%。
4 应用级服务发现工作原理
4.1 设计原则
上面一节我们从服务模型及支撑大规模集群的角度分别给出了 Dubbo 往应用级服务发现靠拢的好处和原因,但这么做的同时接口粒度的服务治理能力还是要继续保留,这是 Dubbo 框架编程模型易用性、服务治理能力优势的基础。 以下是我认为我们做服务模型迁移仍要坚持的设计原则
- 新的服务发现模型要实现对原有 Dubbo 消费端开发者的无感知迁移,即 Dubbo 继续面向 RPC 服务编程、面向 RPC 服务治理,做到对用户侧完全无感知。
- 建立 Consumer 与 Provider 间的自动化 RPC 服务元数据协调机制,解决传统微服务模型无法同步 RPC 级接口配置的缺点。
4.2 基本原理详解
应用级服务发现作为一种新的服务发现机制,和以前 Dubbo 基于 RPC 服务粒度的服务发现在核心流程上基本上是一致的:即服务提供者往注册中心注册地址信息,服务消费者从注册中心拉取&订阅地址信息。
这里主要的不同有以下两点:
4.2.1 注册中心数据以“应用 - 实例列表”格式组织,不再包含 RPC 服务信息
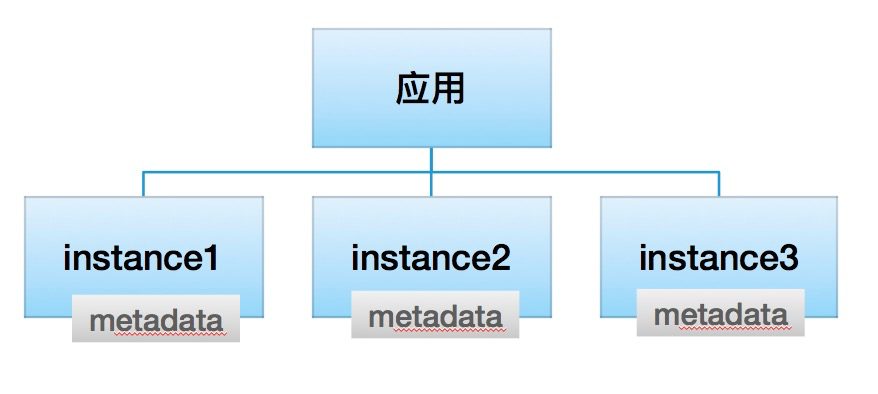
以下是每个 Instance metadata 的示例数据,总的原则是 metadata 只包含当前 instance 节点相关的信息,不涉及 RPC 服务粒度的信息。
总体信息概括如下:实例地址、实例各种环境标、metadata service 元数据、其他少量必要属性。
{
"name": "provider-app-name",
"id": "192.168.0.102:20880",
"address": "192.168.0.102",
"port": 20880,
"sslPort": null,
"payload": {
"id": null,
"name": "provider-app-name",
"metadata": {
"metadataService": "{\"dubbo\":{\"version\":\"1.0.0\",\"dubbo\":\"2.0.2\",\"release\":\"2.7.5\",\"port\":\"20881\"}}",
"endpoints": "[{\"port\":20880,\"protocol\":\"dubbo\"}]",
"storage-type": "local",
"revision": "6785535733750099598",
}
},
"registrationTimeUTC": 1583461240877,
"serviceType": "DYNAMIC",
"uriSpec": null
}
4.2.2 Client – Server 自行协商 RPC 方法信息
在注册中心不再同步 RPC 服务信息后,服务自省在服务消费端和提供端之间建立了一条内置的 RPC 服务信息协商机制,这也是“服务自省”这个名字的由来。服务端实例会暴露一个预定义的 MetadataService RPC 服务,消费端通过调用 MetadataService 获取每个实例 RPC 方法相关的配置信息。

当前 MetadataService 返回的数据格式如下,
[
"dubbo://192.168.0.102:20880/org.apache.dubbo.demo.DemoService?anyhost=true&application=demo-provider&deprecated=false&dubbo=2.0.2&dynamic=true&generic=false&interface=org.apache.dubbo.demo.DemoService&methods=sayHello&pid=9585&release=2.7.5&side=provider×tamp=1583469714314",
"dubbo://192.168.0.102:20880/org.apache.dubbo.demo.HelloService?anyhost=true&application=demo-provider&deprecated=false&dubbo=2.0.2&dynamic=true&generic=false&interface=org.apache.dubbo.demo.DemoService&methods=sayHello&pid=9585&release=2.7.5&side=provider×tamp=1583469714314",
"dubbo://192.168.0.102:20880/org.apache.dubbo.demo.WorldService?anyhost=true&application=demo-provider&deprecated=false&dubbo=2.0.2&dynamic=true&generic=false&interface=org.apache.dubbo.demo.DemoService&methods=sayHello&pid=9585&release=2.7.5&side=provider×tamp=1583469714314"
]
熟悉 Dubbo 基于 RPC 服务粒度的服务发现模型的开发者应该能看出来,服务自省机制机制将以前注册中心传递的 URL 一拆为二:
- 一部分和实例相关的数据继续保留在注册中心,如 ip、port、机器标识等。
- 另一部分和 RPC 方法相关的数据从注册中心移除,转而通过 MetadataService 暴露给消费端。
理想情况下是能达到数据按照实例、RPC 服务严格区分开来,但明显可以看到以上实现版本还存在一些数据冗余,有些数据也还未合理划分。尤其是 MetadataService 部分,其返回的数据还只是简单的 URL 列表组装,这些 URL其实是包含了全量的数据。
以下是服务自省的一个完整工作流程图,详细描述了服务注册、服务发现、MetadataService、RPC 调用间的协作流程。
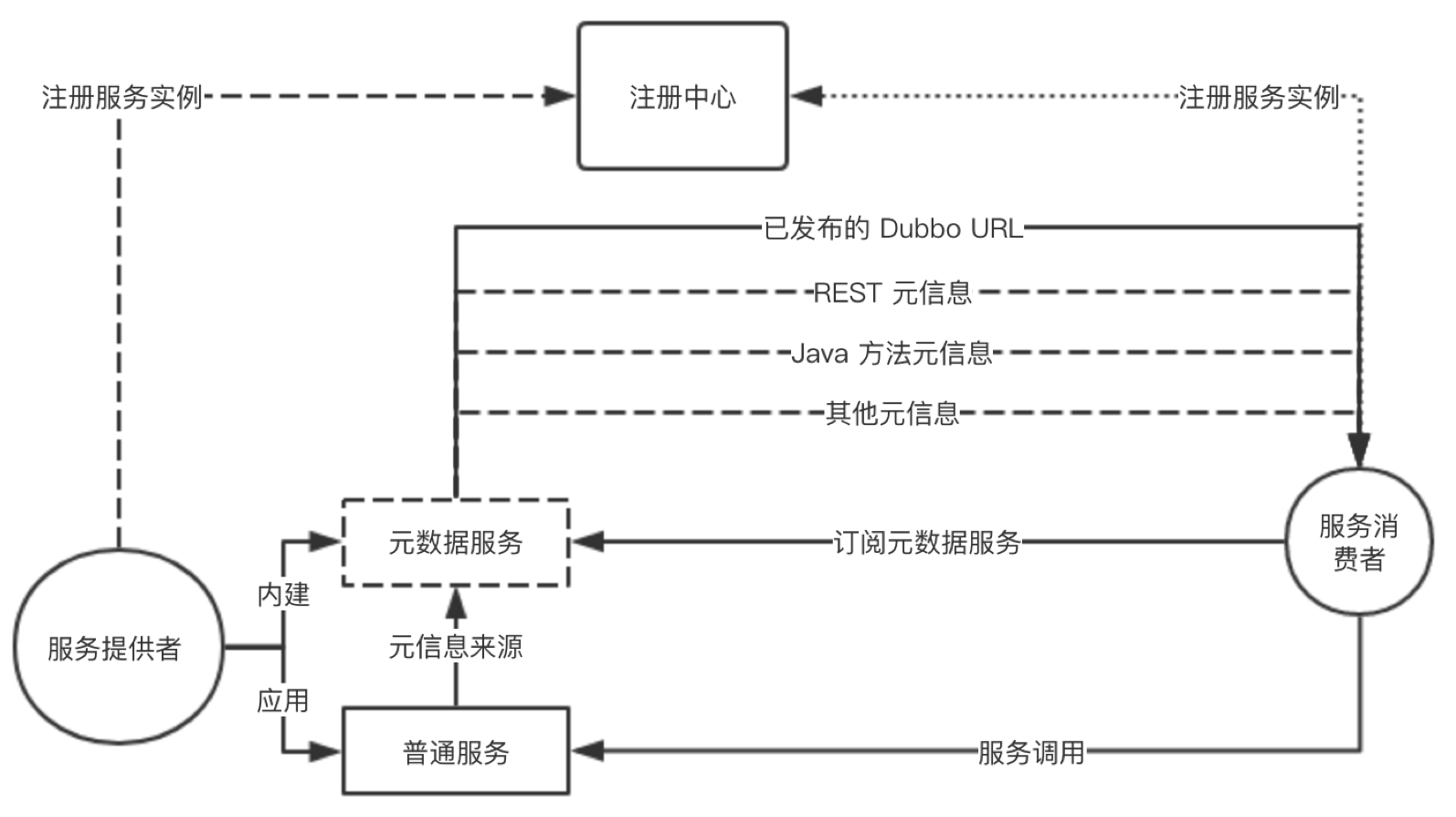
- 服务提供者启动,首先解析应用定义的“普通服务”并依次注册为 RPC 服务,紧接着注册内建的 MetadataService 服务,最后打开 TCP 监听端口。
- 启动完成后,将实例信息注册到注册中心(仅限 ip、port 等实例相关数据),提供者启动完成。
- 服务消费者启动,首先依据其要“消费的 provider 应用名”到注册中心查询地址列表,并完成订阅(以实现后续地址变更自动通知)。
- 消费端拿到地址列表后,紧接着对 MetadataService 发起调用,返回结果中包含了所有应用定义的“普通服务”及其相关配置信息。
- 至此,消费者可以接收外部流量,并对提供者发起 Dubbo RPC 调用
在以上流程中,我们只考虑了一切顺利的情况,但在更详细的设计或编码实现中,我们还需要严格约定一些异常场景下的框架行为。比如,如果消费者 MetadataService 调用失败,则在重试知道成功之前,消费者将不可以接收外部流量。
4.3 服务自省中的关键机制
4.3.1 元数据同步机制
Client 与 Server 间在收到地址推送后的配置同步是服务自省的关键环节,目前针对元数据同步有两种具体的可选方案,分别是:
- 内建 MetadataService。
- 独立的元数据中心,通过中心化的元数据集群协调数据。
1. 内建 MetadataService MetadataService 通过标准的 Dubbo 协议暴露,根据查询条件,会将内存中符合条件的“普通服务”配置返回给消费者。这一步发生在消费端选址和调用前。
2. 元数据中心 复用 2.7 版本中引入的元数据中心,provider 实例启动后,会尝试将内部的 RPC 服务组织成元数据的格式同步到元数据中心,而 consumer 则在每次收到注册中心推送更新后,主动查询元数据中心。
注意 consumer 端查询元数据中心的时机,是等到注册中心的地址更新通知之后。也就是通过注册中心下发的数据,我们能明确的知道何时某个实例的元数据被更新了,此时才需要去查元数据中心。

4.3.2 RPC 服务 < - > 应用映射关系
回顾上文讲到的注册中心关于“应用 - 实例列表”结构的数据组织形式,这个变动目前对开发者并不是完全透明的,业务开发侧会感知到查询/订阅地址列表的机制的变化。具体来说,相比以往我们基于 RPC 服务来检索地址,现在 consumer 需要通过指定 provider 应用名才能实现地址查询或订阅。
老的 Consumer 开发与配置示例:
<!-- 框架直接通过 RPC Service 1/2/N 去注册中心查询或订阅地址列表 -->
<dubbo:registry address="zookeeper://127.0.0.1:2181"/>
<dubbo:reference interface="RPC Service 1" />
<dubbo:reference interface="RPC Service 2" />
<dubbo:reference interface="RPC Service N" />
新的 Consumer 开发与配置示例:
<!-- 框架需要通过额外的 provided-by="provider-app-x" 才能在注册中心查询或订阅到地址列表 -->
<dubbo:registry address="zookeeper://127.0.0.1:2181?registry-type=service"/>
<dubbo:reference interface="RPC Service 1" provided-by="provider-app-x"/>
<dubbo:reference interface="RPC Service 2" provided-by="provider-app-x" />
<dubbo:reference interface="RPC Service N" provided-by="provider-app-y" />
以上指定 provider 应用名的方式是 Spring Cloud 当前的做法,需要 consumer 端的开发者显示指定其要消费的 provider 应用。
以上问题的根源在于注册中心不知道任何 RPC 服务相关的信息,因此只能通过应用名来查询。
为了使整个开发流程对老的 Dubbo 用户更透明,同时避免指定 provider 对可扩展性带来的影响(参见下方说明),我们设计了一套 RPC 服务到应用名的映射关系,以尝试在 consumer 端自动完成 RPC 服务到 provider 应用名的转换。
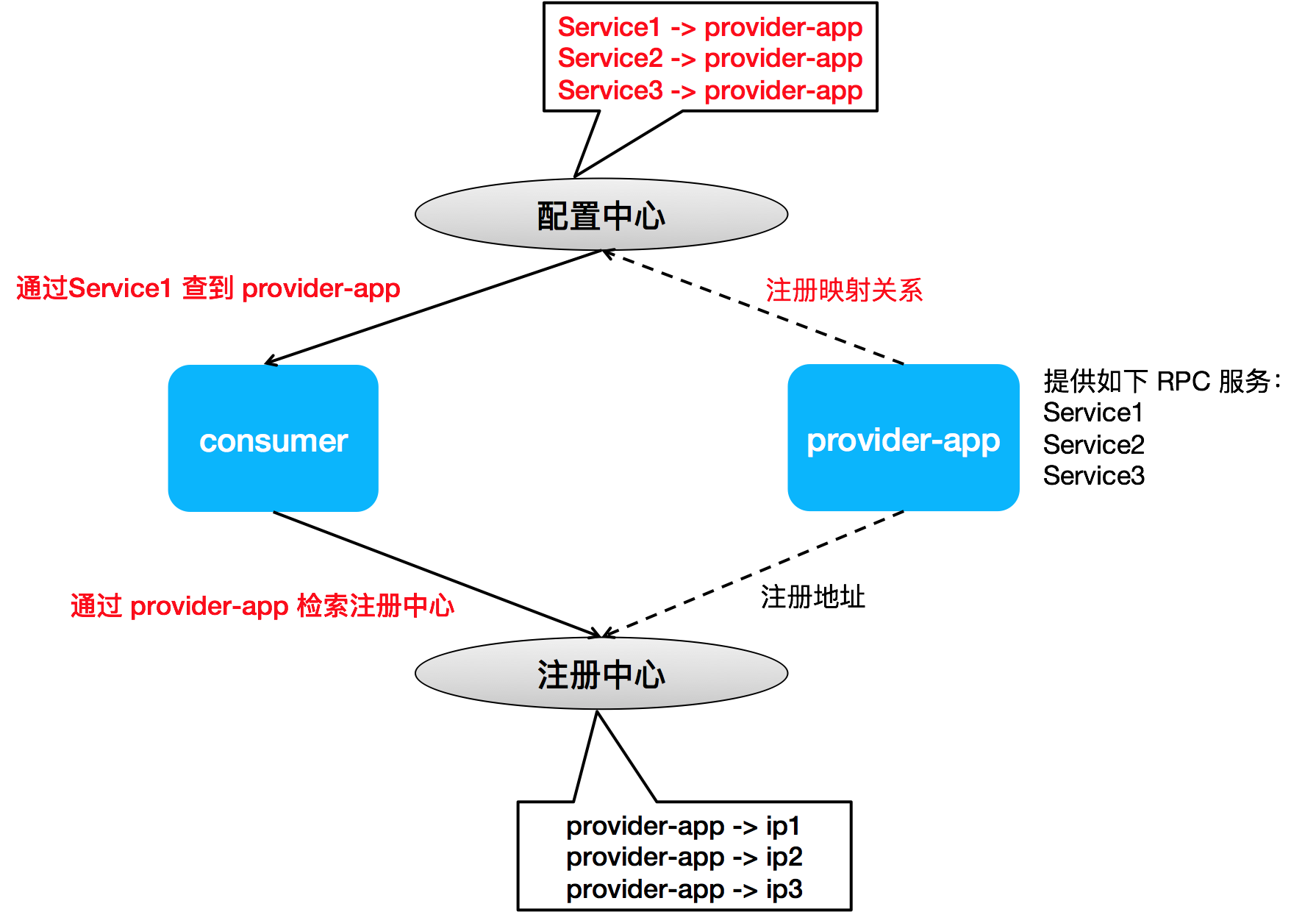
Dubbo 之所以选择建立一套“接口-应用”的映射关系,主要是考虑到 service - app 映射关系的不确定性。一个典型的场景即是应用/服务拆分,如上面提到的配置
<dubbo:reference interface="RPC Service 2" provided-by="provider-app-x" />,PC Service 2 是定义于 provider-app-x 中的一个服务,未来它随时可能会被开发者分拆到另外一个新的应用如 provider-app-x-1 中,这个拆分要被所有的 PC Service 2 消费方感知到,并对应用进行修改升级,如改为<dubbo:reference interface="RPC Service 2" provided-by="provider-app-x-1" />,这样的升级成本不可否认还是挺高的。 到底是 Dubbo 框架帮助开发者透明的解决这个问题,还是交由开发者自己去解决,当然这只是个策略选择问题,并且 Dubbo 2.7.5+ 版本目前是都提供了的。其实我个人更倾向于交由业务开发者通过组织上的约束来做,这样也可进一步降低 Dubbo 框架的复杂度,提升运行态的稳定性。
5 总结与展望
应用级服务发现机制是 Dubbo 面向云原生走出的重要一步,它帮 Dubbo 打通了与其他微服务体系之间在地址发现层面的鸿沟,也成为 Dubbo 适配 Kubernetes Native Service 等基础设施的基础。我们期望 Dubbo 在新模型基础上,能继续保留在编程易用性、服务治理能力等方面强大的优势。但是我们也应该看到应用粒度的模型一方面带来了新的复杂性,需要我们继续去优化与增强;另一方面,除了地址存储与推送之外,应用粒度在帮助 Dubbo 选址层面也有进一步挖掘的潜力。
本文介绍了 Dubbo3 应用级服务发现的实现原理 Wednesday, June 02, 20211 服务发现(Service Discovery) 概述
从 Internet 刚开始兴起,如何动态感知后端服务的地址变化就是一个必须要面对的问题,为此人们定义了 DNS 协议,基于此协议,调用方只需要记住由固定字符串组成的域名,就能轻松完成对后端服务的访问,而不用担心流量最终会访问到哪些机器 IP,因为有代理组件会基于 DNS 地址解析后的地址列表,将流量透明的、均匀的分发到不同的后端机器上。
在使用微服务构建复杂的分布式系统时,如何感知 backend 服务实例的动态上下线,也是微服务框架最需要关心并解决的问题之一。业界将这个问题称之为 - 微服务的地址发现(Service Discovery),业界比较有代表性的微服务框架如 SpringCloud、Microservices、Dubbo 等都抽象了强大的动态地址发现能力,并且为了满足微服务业务场景的需求,绝大多数框架的地址发现都是基于自己设计的一套机制来实现,因此在能力、灵活性上都要比传统 DNS 丰富得多。如 SpringCloud 中常用的 Eureka, Dubbo 中常用的 Zookeeper、Nacos 等,这些注册中心实现不止能够传递地址(IP + Port),还包括一些微服务的 Metadata 信息,如实例序列化类型、实例方法列表、各个方法级的定制化配置等。
下图是微服务中 Service Discovery 的基本工作原理图,微服务体系中的实例大概可分为三种角色:服务提供者(Provider)、服务消费者(Consumer)和注册中心(Registry)。而不同框架实现间最主要的区别就体现在注册中心数据的组织:地址如何组织、以什么粒度组织、除地址外还同步哪些数据?
我们今天这篇文章就是围绕这三个角色展开,重点看下 Dubbo 中对于服务发现方案的设计,包括之前老的服务发现方案的优势和缺点,以及 Dubbo 3.0 中正在设计、开发中的全新的面向应用粒度的地址发现方案,我们期待这个新的方案能做到:
- 支持几十万/上百万级集群实例的地址发现
- 与不同的微服务体系(如 Spring Cloud)实现在地址发现层面的互通
2 Dubbo 地址发现机制解析
我们先以一个 DEMO 应用为例,来快速的看一下 Dubbo “接口粒度”服务发现与“应用粒度”服务发现体现出来的区别。这里我们重点关注 Provider 实例是如何向注册中心注册的,并且,为了体现注册中心数据量变化,我们观察的是两个 Provider 实例的场景。
应用 DEMO 提供的服务列表如下:
<dubbo:service interface="org.apache.dubbo.samples.basic.api.DemoService" ref="demoService"/>
<dubbo:service interface="org.apache.dubbo.samples.basic.api.GreetingService" ref="greetingService"/>
我们示例注册中心实现采用的是 Zookeeper ,启动 192.168.0.103 和 192.168.0.104 两个实例后,以下是两种模式下注册中心的实际数据
1. “接口粒度” 服务发现
192.168.0.103 实例注册的数据
dubbo://192.168.0.103:20880/org.apache.dubbo.samples.basic.api.DemoService?anyhost=true&application=demo-provider&default=true&deprecated=false&dubbo=2.0.2&dynamic=true&generic=false&interface=org.apache.dubbo.samples.basic.api.DemoService&methods=testVoid,sayHello&pid=995&release=2.7.7&side=provider×tamp=1596988171266
dubbo://192.168.0.103:20880/org.apache.dubbo.samples.basic.api.GreetingService?anyhost=true&application=demo-provider&default=true&deprecated=false&dubbo=2.0.2&dynamic=true&generic=false&interface=org.apache.dubbo.samples.basic.api.GreetingService&methods=greeting&pid=995&release=2.7.7&side=provider×tamp=1596988170816
192.168.0.104 实例注册的数据
dubbo://192.168.0.104:20880/org.apache.dubbo.samples.basic.api.DemoService?anyhost=true&application=demo-provider&default=true&deprecated=false&dubbo=2.0.2&dynamic=true&generic=false&interface=org.apache.dubbo.samples.basic.api.DemoService&methods=testVoid,sayHello&pid=995&release=2.7.7&side=provider×tamp=1596988171266
dubbo://192.168.0.104:20880/org.apache.dubbo.samples.basic.api.GreetingService?anyhost=true&application=demo-provider&default=true&deprecated=false&dubbo=2.0.2&dynamic=true&generic=false&interface=org.apache.dubbo.samples.basic.api.GreetingService&methods=greeting&pid=995&release=2.7.7&side=provider×tamp=1596988170816
2. “应用粒度” 服务发现
192.168.0.103 与 192.168.0.104 两个实例共享一份注册中心数据,如下:
{
"name": "demo-provider",
"id": "192.168.0.103:20880",
"address": "192.168.0.103",
"port": 20880,
"metadata": {
"dubbo.endpoints": "[{\"port\":20880,\"protocol\":\"dubbo\"}]",
"dubbo.metadata.storage-type": "local",
"dubbo.revision": "6785535733750099598"
},
"time": 1583461240877
}
{
"name": "demo-provider",
"id": "192.168.0.104:20880",
"address": "192.168.0.104",
"port": 20880,
"metadata": {
"dubbo.endpoints": "[{\"port\":20880,\"protocol\":\"dubbo\"}]",
"dubbo.metadata.storage-type": "local",
"dubbo.revision": "7829635812370099387"
},
"time": 1583461240877
}
对比以上两种不同粒度的服务发现模式,从 “接口粒度” 升级到 “应用粒度” 后我们可以总结出最大的区别是:注册中心数据量不再与接口数成正比,不论应用提供有多少接口,注册中心只有一条实例数据。
那么接下来我们详细看下这个变化给 Dubbo 带来了哪些好处。
3 Dubbo 应用级服务发现的意义
我们先说结论,应用级服务发现给 Dubbo 带来以下优势:
- 与业界主流微服务模型对齐,比如 SpringCloud、Kubernetes Native Service等。
- 提升性能与可伸缩性。注册中心数据的重新组织(减少),能最大幅度的减轻注册中心的存储、推送压力,进而减少 Dubbo Consumer 侧的地址计算压力;集群规模也开始变得可预测、可评估(与 RPC 接口数量无关,只与实例部署规模相关)。
3.1 对齐主流微服务模型
自动、透明的实例地址发现(负载均衡)是所有微服务框架需要解决的事情,这能让后端的部署结构对上游微服务透明,上游服务只需要从收到的地址列表中选取一个,发起调用就可以了。要实现以上目标,涉及两个关键点的自动同步:
- 实例地址,服务消费方需要知道地址以建立连接
- RPC 方法定义,服务消费方需要知道 RPC 服务的具体定义,不论服务类型是 rest 或 rmi 等。
对于 RPC 实例间借助注册中心的数据同步,REST 定义了一套非常有意思的成熟度模型,感兴趣的朋友可以参考这里的链接 https://www.martinfowler.com/articles/richardsonMaturityModel.html, 按照文章中的 4 级成熟度定义,Dubbo 当前基于接口粒度的模型可以对应到 L4 级别。
接下来,我们看看 Dubbo、SpringCloud 以及 Kubernetes 分别是怎么围绕自动化的实例地址发现这个目标设计的。
1. Spring Cloud
Spring Cloud 通过注册中心只同步了应用与实例地址,消费方可以基于实例地址与服务提供方建立连接,但是消费方对于如何发起 http 调用(SpringCloud 基于 rest 通信)一无所知,比如对方有哪些 http endpoint,需要传入哪些参数等。
RPC 服务这部分信息目前都是通过线下约定或离线的管理系统来协商的。这种架构的优缺点总结如下。 优势:部署结构清晰、地址推送量小; 缺点:地址订阅需要指定应用名, provider 应用变更(拆分)需消费端感知;RPC 调用无法全自动同步。
2. Dubbo
Dubbo 通过注册中心同时同步了实例地址和 RPC 方法,因此其能实现 RPC 过程的自动同步,面向 RPC 编程、面向 RPC 治理,对后端应用的拆分消费端无感知,其缺点则是地址推送数量变大,和 RPC 方法成正比。
3. Dubbo + Kubernetes
Dubbo 要支持 Kubernetes native service,相比之前自建注册中心的服务发现体系来说,在工作机制上主要有两点变化:
- 服务注册由平台接管,provider 不再需要关心服务注册
- consumer 端服务发现将是 Dubbo 关注的重点,通过对接平台层的 API-Server、DNS 等,Dubbo client 可以通过一个 Service Name(通常对应到 Application Name)查询到一组 Endpoints(一组运行 provider 的 pod),通过将 Endpoints 映射到 Dubbo 内部地址列表,以驱动 Dubbo 内置的负载均衡机制工作。
Kubernetes Service 作为一个抽象概念,怎么映射到 Dubbo 是一个值得讨论的点
- Service Name - > Application Name,Dubbo 应用和 Kubernetes 服务一一对应,对于微服务运维和建设环节透明,与开发阶段解耦。
apiVersion: v1 kind: Service metadata: name: provider-app-name spec: selector: app: provider-app-name ports: - protocol: TCP port: targetPort: 9376
- Service Name - > Dubbo RPC Service,Kubernetes 要维护调度的服务与应用内建 RPC 服务绑定,维护的服务数量变多。
--- apiVersion: v1 kind: Service metadata: name: rpc-service-1 spec: selector: app: provider-app-name ports: ## ... --- apiVersion: v1 kind: Service metadata: name: rpc-service-2 spec: selector: app: provider-app-name ports: ## ... --- apiVersion: v1 kind: Service metadata: name: rpc-service-N spec: selector: app: provider-app-name ports: ## ...
结合以上几种不同微服务框架模型的分析,我们可以发现,Dubbo 与 SpringCloud、Kubernetes 等不同产品在微服务的抽象定义上还是存在很大不同的。SpringCloud 和 Kubernetes 在微服务的模型抽象上还是比较接近的,两者基本都只关心实例地址的同步,如果我们去关心其他的一些服务框架产品,会发现它们绝大多数也是这么设计的;
即 REST 成熟度模型中的 L3 级别。
对比起来 Dubbo 则相对是比较特殊的存在,更多的是从 RPC 服务的粒度去设计的。
对应 REST 成熟度模型中的 L4 级别。
如我们上面针对每种模型做了详细的分析,每种模型都有其优势和不足。而我们最初决定 Dubbo 要做出改变,往其他的微服务发现模型上的对齐,是我们最早在确定 Dubbo 的云原生方案时,我们发现要让 Dubbo 去支持 Kubernetes Native Service,模型对齐是一个基础条件;另一点是来自用户侧对 Dubbo 场景化的一些工程实践的需求,得益于 Dubbo 对多注册、多协议能力的支持,使得 Dubbo 联通不同的微服务体系成为可能,而服务发现模型的不一致成为其中的一个障碍,这部分的场景描述请参见以下文章:Dubbo 如何成为连接异构微服务体系的最佳服务开发框架
3.2 更大规模的微服务集群 - 解决性能瓶颈
这部分涉及到和注册中心、配置中心的交互,关于不同模型下注册中心数据的变化,之前原理部分我们简单分析过。为更直观的对比服务模型变更带来的推送效率提升,我们来通过一个示例看一下不同模型注册中心的对比:
图中左边是微服务框架的一个典型工作流程,Provider 和 Consumer 通过注册中心实现自动化的地址通知。其中,Provider 实例的信息如图中表格所示: 应用 DEMO 包含三个接口 DemoService 1 2 3,当前实例的 ip 地址为 10.210.134.30。
- 对于 Spring Cloud 和 Kubernetes 模型,注册中心只会存储一条
DEMO - 10.210.134.30+metadata的数据; - 对于老的 Dubbo 模型,注册中心存储了三条接口粒度的数据,分别对应三个接口 DemoService 1 2 3,并且很多的址数据都是重复的;
可以总结出,基于应用粒度的模型所存储和推送的数据量是和应用、实例数成正比的,只有当我们的应用数增多或应用的实例数增长时,地址推送压力才会上涨。 而对于基于接口粒度的模型,数据量是和接口数量正相关的,鉴于一个应用通常发布多个接口的现状,这个数量级本身比应用粒度是要乘以倍数的;另外一个关键点在于,接口粒度导致的集群规模评估的不透明,相对于实例、应用增长都通常是在运维侧的规划之中,接口的定义更多的是业务侧的内部行为,往往可以绕过评估给集群带来压力。
以 Consumer 端服务订阅举例,根据我对社区部分 Dubbo 中大规模头部用户的粗略统计,根据受统计公司的实际场景,一个 Consumer 应用要消费(订阅)的 Provier 应用数量往往要超过 10 个,而具体到其要消费(订阅)的的接口数量则通常要达到 30 个,平均情况下 Consumer 订阅的 3 个接口来自同一个 Provider 应用,如此计算下来,如果以应用粒度为地址通知和选址基本单位,则平均地址推送和计算量将下降 60% 还要多, 而在极端情况下,也就是当 Consumer 端消费的接口更多的来自同一个应用时,这个地址推送与内存消耗的占用将会进一步得到降低,甚至可以超过 80% 以上。
一个典型的极端场景即是 Dubbo 体系中的网关型应用,有些网关应用消费(订阅)达 100+ 应用,而消费(订阅)的服务有 1000+ ,平均有 10 个接口来自同一个应用,如果我们把地址推送和计算的粒度改为应用,则地址推送量从原来的 n * 1000 变为 n * 100,地址数量降低可达近 90%。
4 应用级服务发现工作原理
4.1 设计原则
上面一节我们从服务模型及支撑大规模集群的角度分别给出了 Dubbo 往应用级服务发现靠拢的好处和原因,但这么做的同时接口粒度的服务治理能力还是要继续保留,这是 Dubbo 框架编程模型易用性、服务治理能力优势的基础。 以下是我认为我们做服务模型迁移仍要坚持的设计原则
- 新的服务发现模型要实现对原有 Dubbo 消费端开发者的无感知迁移,即 Dubbo 继续面向 RPC 服务编程、面向 RPC 服务治理,做到对用户侧完全无感知。
- 建立 Consumer 与 Provider 间的自动化 RPC 服务元数据协调机制,解决传统微服务模型无法同步 RPC 级接口配置的缺点。
4.2 基本原理详解
应用级服务发现作为一种新的服务发现机制,和以前 Dubbo 基于 RPC 服务粒度的服务发现在核心流程上基本上是一致的:即服务提供者往注册中心注册地址信息,服务消费者从注册中心拉取&订阅地址信息。
这里主要的不同有以下两点:
4.2.1 注册中心数据以“应用 - 实例列表”格式组织,不再包含 RPC 服务信息
以下是每个 Instance metadata 的示例数据,总的原则是 metadata 只包含当前 instance 节点相关的信息,不涉及 RPC 服务粒度的信息。
总体信息概括如下:实例地址、实例各种环境标、metadata service 元数据、其他少量必要属性。
{
"name": "provider-app-name",
"id": "192.168.0.102:20880",
"address": "192.168.0.102",
"port": 20880,
"sslPort": null,
"payload": {
"id": null,
"name": "provider-app-name",
"metadata": {
"metadataService": "{\"dubbo\":{\"version\":\"1.0.0\",\"dubbo\":\"2.0.2\",\"release\":\"2.7.5\",\"port\":\"20881\"}}",
"endpoints": "[{\"port\":20880,\"protocol\":\"dubbo\"}]",
"storage-type": "local",
"revision": "6785535733750099598",
}
},
"registrationTimeUTC": 1583461240877,
"serviceType": "DYNAMIC",
"uriSpec": null
}
4.2.2 Client – Server 自行协商 RPC 方法信息
在注册中心不再同步 RPC 服务信息后,服务自省在服务消费端和提供端之间建立了一条内置的 RPC 服务信息协商机制,这也是“服务自省”这个名字的由来。服务端实例会暴露一个预定义的 MetadataService RPC 服务,消费端通过调用 MetadataService 获取每个实例 RPC 方法相关的配置信息。
当前 MetadataService 返回的数据格式如下,
[
"dubbo://192.168.0.102:20880/org.apache.dubbo.demo.DemoService?anyhost=true&application=demo-provider&deprecated=false&dubbo=2.0.2&dynamic=true&generic=false&interface=org.apache.dubbo.demo.DemoService&methods=sayHello&pid=9585&release=2.7.5&side=provider×tamp=1583469714314",
"dubbo://192.168.0.102:20880/org.apache.dubbo.demo.HelloService?anyhost=true&application=demo-provider&deprecated=false&dubbo=2.0.2&dynamic=true&generic=false&interface=org.apache.dubbo.demo.DemoService&methods=sayHello&pid=9585&release=2.7.5&side=provider×tamp=1583469714314",
"dubbo://192.168.0.102:20880/org.apache.dubbo.demo.WorldService?anyhost=true&application=demo-provider&deprecated=false&dubbo=2.0.2&dynamic=true&generic=false&interface=org.apache.dubbo.demo.DemoService&methods=sayHello&pid=9585&release=2.7.5&side=provider×tamp=1583469714314"
]
熟悉 Dubbo 基于 RPC 服务粒度的服务发现模型的开发者应该能看出来,服务自省机制机制将以前注册中心传递的 URL 一拆为二:
- 一部分和实例相关的数据继续保留在注册中心,如 ip、port、机器标识等。
- 另一部分和 RPC 方法相关的数据从注册中心移除,转而通过 MetadataService 暴露给消费端。
理想情况下是能达到数据按照实例、RPC 服务严格区分开来,但明显可以看到以上实现版本还存在一些数据冗余,有些数据也还未合理划分。尤其是 MetadataService 部分,其返回的数据还只是简单的 URL 列表组装,这些 URL其实是包含了全量的数据。
以下是服务自省的一个完整工作流程图,详细描述了服务注册、服务发现、MetadataService、RPC 调用间的协作流程。
- 服务提供者启动,首先解析应用定义的“普通服务”并依次注册为 RPC 服务,紧接着注册内建的 MetadataService 服务,最后打开 TCP 监听端口。
- 启动完成后,将实例信息注册到注册中心(仅限 ip、port 等实例相关数据),提供者启动完成。
- 服务消费者启动,首先依据其要“消费的 provider 应用名”到注册中心查询地址列表,并完成订阅(以实现后续地址变更自动通知)。
- 消费端拿到地址列表后,紧接着对 MetadataService 发起调用,返回结果中包含了所有应用定义的“普通服务”及其相关配置信息。
- 至此,消费者可以接收外部流量,并对提供者发起 Dubbo RPC 调用
在以上流程中,我们只考虑了一切顺利的情况,但在更详细的设计或编码实现中,我们还需要严格约定一些异常场景下的框架行为。比如,如果消费者 MetadataService 调用失败,则在重试知道成功之前,消费者将不可以接收外部流量。
4.3 服务自省中的关键机制
4.3.1 元数据同步机制
Client 与 Server 间在收到地址推送后的配置同步是服务自省的关键环节,目前针对元数据同步有两种具体的可选方案,分别是:
- 内建 MetadataService。
- 独立的元数据中心,通过中心化的元数据集群协调数据。
1. 内建 MetadataService MetadataService 通过标准的 Dubbo 协议暴露,根据查询条件,会将内存中符合条件的“普通服务”配置返回给消费者。这一步发生在消费端选址和调用前。
2. 元数据中心 复用 2.7 版本中引入的元数据中心,provider 实例启动后,会尝试将内部的 RPC 服务组织成元数据的格式同步到元数据中心,而 consumer 则在每次收到注册中心推送更新后,主动查询元数据中心。
注意 consumer 端查询元数据中心的时机,是等到注册中心的地址更新通知之后。也就是通过注册中心下发的数据,我们能明确的知道何时某个实例的元数据被更新了,此时才需要去查元数据中心。
4.3.2 RPC 服务 < - > 应用映射关系
回顾上文讲到的注册中心关于“应用 - 实例列表”结构的数据组织形式,这个变动目前对开发者并不是完全透明的,业务开发侧会感知到查询/订阅地址列表的机制的变化。具体来说,相比以往我们基于 RPC 服务来检索地址,现在 consumer 需要通过指定 provider 应用名才能实现地址查询或订阅。
老的 Consumer 开发与配置示例:
<!-- 框架直接通过 RPC Service 1/2/N 去注册中心查询或订阅地址列表 -->
<dubbo:registry address="zookeeper://127.0.0.1:2181"/>
<dubbo:reference interface="RPC Service 1" />
<dubbo:reference interface="RPC Service 2" />
<dubbo:reference interface="RPC Service N" />
新的 Consumer 开发与配置示例:
<!-- 框架需要通过额外的 provided-by="provider-app-x" 才能在注册中心查询或订阅到地址列表 -->
<dubbo:registry address="zookeeper://127.0.0.1:2181?registry-type=service"/>
<dubbo:reference interface="RPC Service 1" provided-by="provider-app-x"/>
<dubbo:reference interface="RPC Service 2" provided-by="provider-app-x" />
<dubbo:reference interface="RPC Service N" provided-by="provider-app-y" />
以上指定 provider 应用名的方式是 Spring Cloud 当前的做法,需要 consumer 端的开发者显示指定其要消费的 provider 应用。
以上问题的根源在于注册中心不知道任何 RPC 服务相关的信息,因此只能通过应用名来查询。
为了使整个开发流程对老的 Dubbo 用户更透明,同时避免指定 provider 对可扩展性带来的影响(参见下方说明),我们设计了一套 RPC 服务到应用名的映射关系,以尝试在 consumer 端自动完成 RPC 服务到 provider 应用名的转换。
Dubbo 之所以选择建立一套“接口-应用”的映射关系,主要是考虑到 service - app 映射关系的不确定性。一个典型的场景即是应用/服务拆分,如上面提到的配置
<dubbo:reference interface="RPC Service 2" provided-by="provider-app-x" />,PC Service 2 是定义于 provider-app-x 中的一个服务,未来它随时可能会被开发者分拆到另外一个新的应用如 provider-app-x-1 中,这个拆分要被所有的 PC Service 2 消费方感知到,并对应用进行修改升级,如改为<dubbo:reference interface="RPC Service 2" provided-by="provider-app-x-1" />,这样的升级成本不可否认还是挺高的。 到底是 Dubbo 框架帮助开发者透明的解决这个问题,还是交由开发者自己去解决,当然这只是个策略选择问题,并且 Dubbo 2.7.5+ 版本目前是都提供了的。其实我个人更倾向于交由业务开发者通过组织上的约束来做,这样也可进一步降低 Dubbo 框架的复杂度,提升运行态的稳定性。
5 总结与展望
应用级服务发现机制是 Dubbo 面向云原生走出的重要一步,它帮 Dubbo 打通了与其他微服务体系之间在地址发现层面的鸿沟,也成为 Dubbo 适配 Kubernetes Native Service 等基础设施的基础。我们期望 Dubbo 在新模型基础上,能继续保留在编程易用性、服务治理能力等方面强大的优势。但是我们也应该看到应用粒度的模型一方面带来了新的复杂性,需要我们继续去优化与增强;另一方面,除了地址存储与推送之外,应用粒度在帮助 Dubbo 选址层面也有进一步挖掘的潜力。
下一页→标签:dubbo,服务,Dubbo,地址,RPC,应用,provider,Dubbo3 来源: https://www.cnblogs.com/rsapaper/p/15596650.html