GNN dataset 划分
作者:互联网
训练集、测试集、验证集的划分
fixed or random


fixed split:对dataset只划分一次
random split: 对dataset进行random split,但是对不同的random seed得到的performance做一个求平均。
graph is special
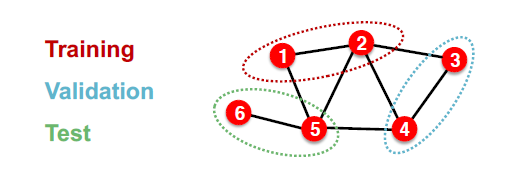
对于graph的划分不想documents或者image一样,因为不同的节点之间具有边进行相连,直接进行划分一个最大的问题就是存在message leakage。
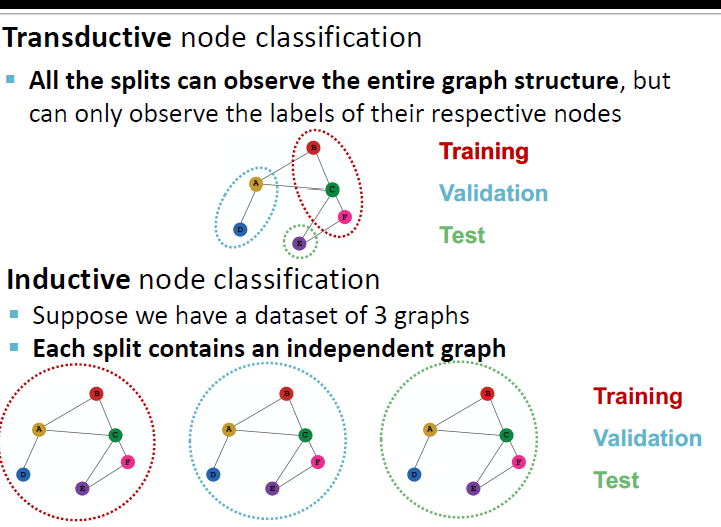
Transductive
特点:训练、验证、测试数据都只是用简单将节点进行进行划分,计算的时候都是使用了整张图。
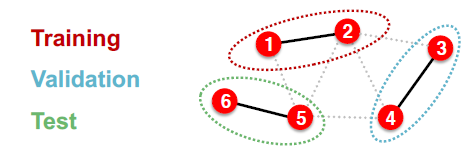
Inductive
将一张图split成多个子图,每一个子图都是相互独立的,不存在message leakage问题。

因为transductive setting作用在一张图上所以它无法用于graph tasks。
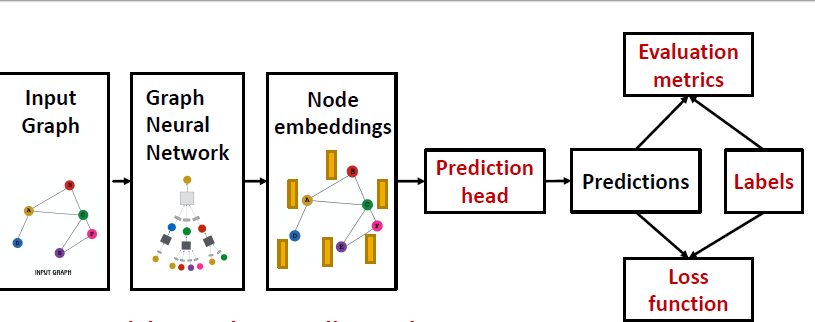
GCN与GraphSage
GCN就是transductive setting,而graphSage是inductive 方式。
三种任务
Node classification
在GCN中,虽然我们只对了一部分节点进行训练,也就是半监督学习,但实际上我们用到的还是整张图结构和features。在graphSage中,使用的inductive方式进行分类。

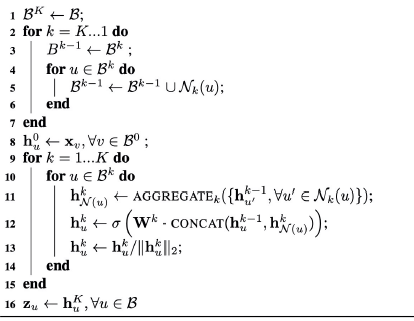
对于每一个minibatch实际上就是一个新的子图。
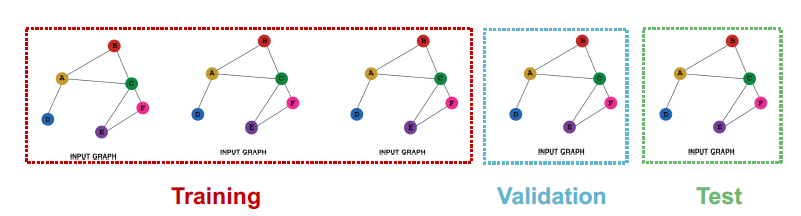
graph classification
一样的理论,但是只有inductive才可以做graph classification,因为它是作用的不同的子图上的。
Link Prediction
inductive
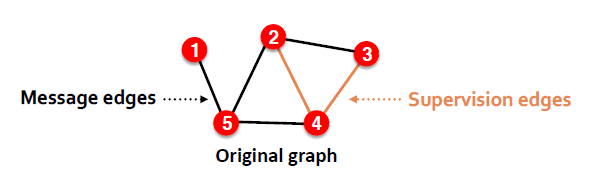
它将边分为message edges和Supervision edges,GNN用message edges来计算,用supervision edges做predict。

inductive 方式,我们会在不同的图上做train、validation、test。
Transductive
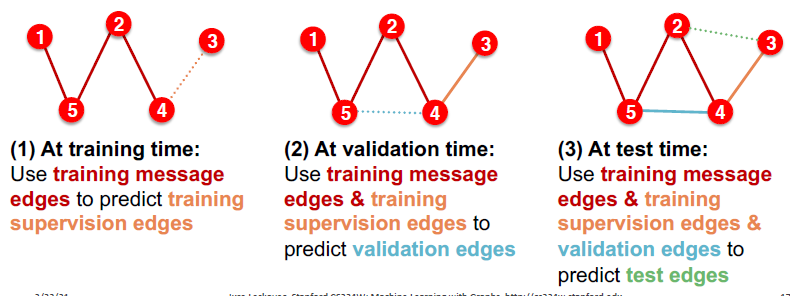
transductive link predict方式,在验证时会将train 的supervision edges 加入到message edges,在test时候,做类似的事情,会将valid 的supervision edges加入到message edges。
jure教授给出的视角:将这个过程视为边生长的过程,也就是引入了时序这个概念,train、valid、test分别对应在不同时间的图。
思考:既然可以视为一个时序数据,那对不同时刻的图,做graph2vec,然后输入到LSTM或者GRU里,是否可以做到预测?
另一个思考的视角:将supervision视为一个mask,引入在之前分享提到的多头 attention机制,用attention进行来训练。这个有点类似于bert里的预训练过程,可以随机随选mask边进行training,最后再做一个预测。
How Powerful are Graph Neural Networks
以这张图为例,我们不用node features,也就是所有节点的features一样,于是用黄色给每个节点标了颜色代表节点特征。
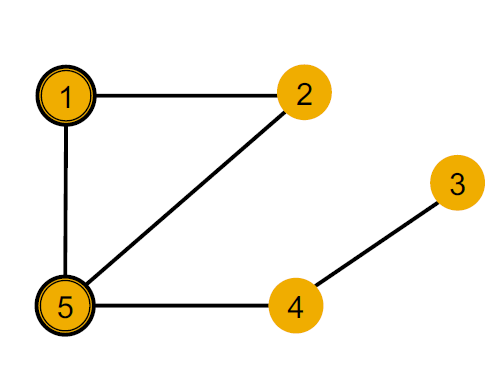
可以看到我们可以区分node 1 和node 5的,因为两个节点的度不一样。
对于node 1和node 4 我们虽然没法直接用degree来区分,但可以用其邻居节点的degree进行区分。
但是对于node 1和node 2我们是没有办法进行区分的。
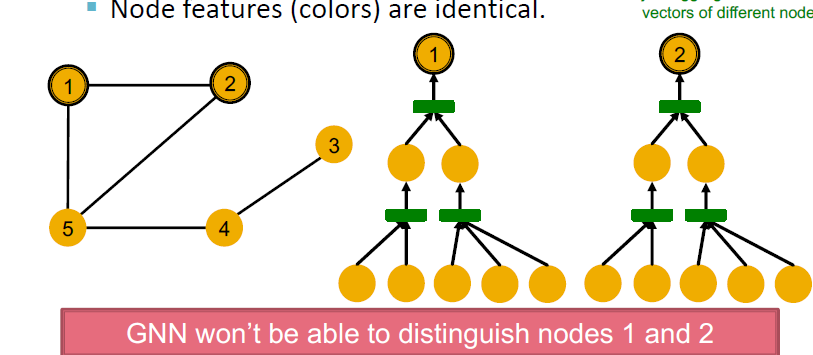
可以看到node 1 和node 2的计算图是一样的,注意这个节点的标号其实是不存在的,我们只能够看到structure和node features,因为所有节点都是黄色,所有节点的features都一样。
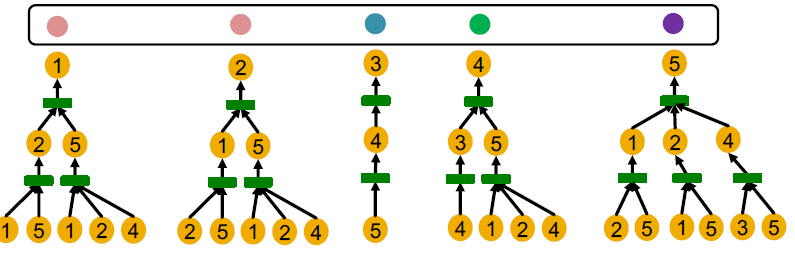
我们将这个graph的所有节点的计算图写出来,可以看到这五个节点可以划分为四种计算图。
那么说,最强的GNN能做什么呢?
最强的GNN应当可以将每一种不同的节点embedding为不同的向量。
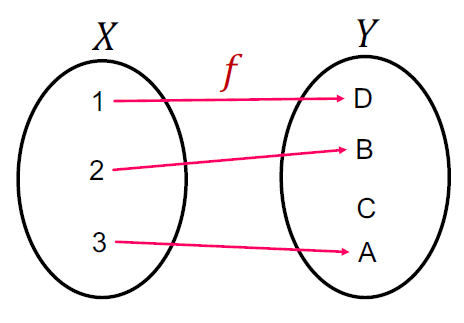
那么这个GNN这就应当是一个单射函数,我们不同种的node可以映射为不同向量。
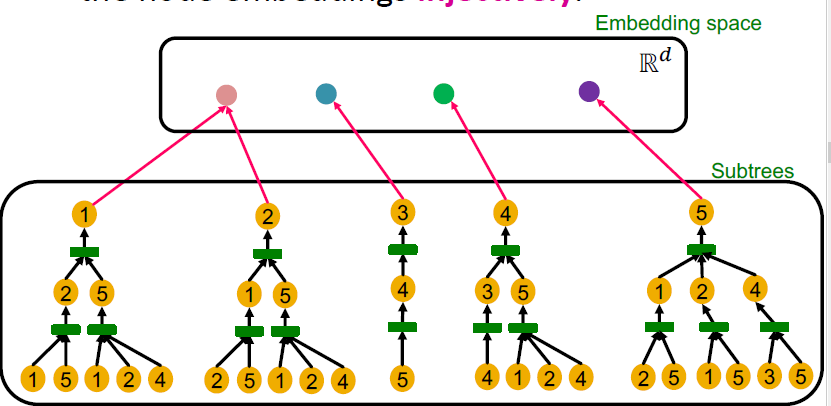
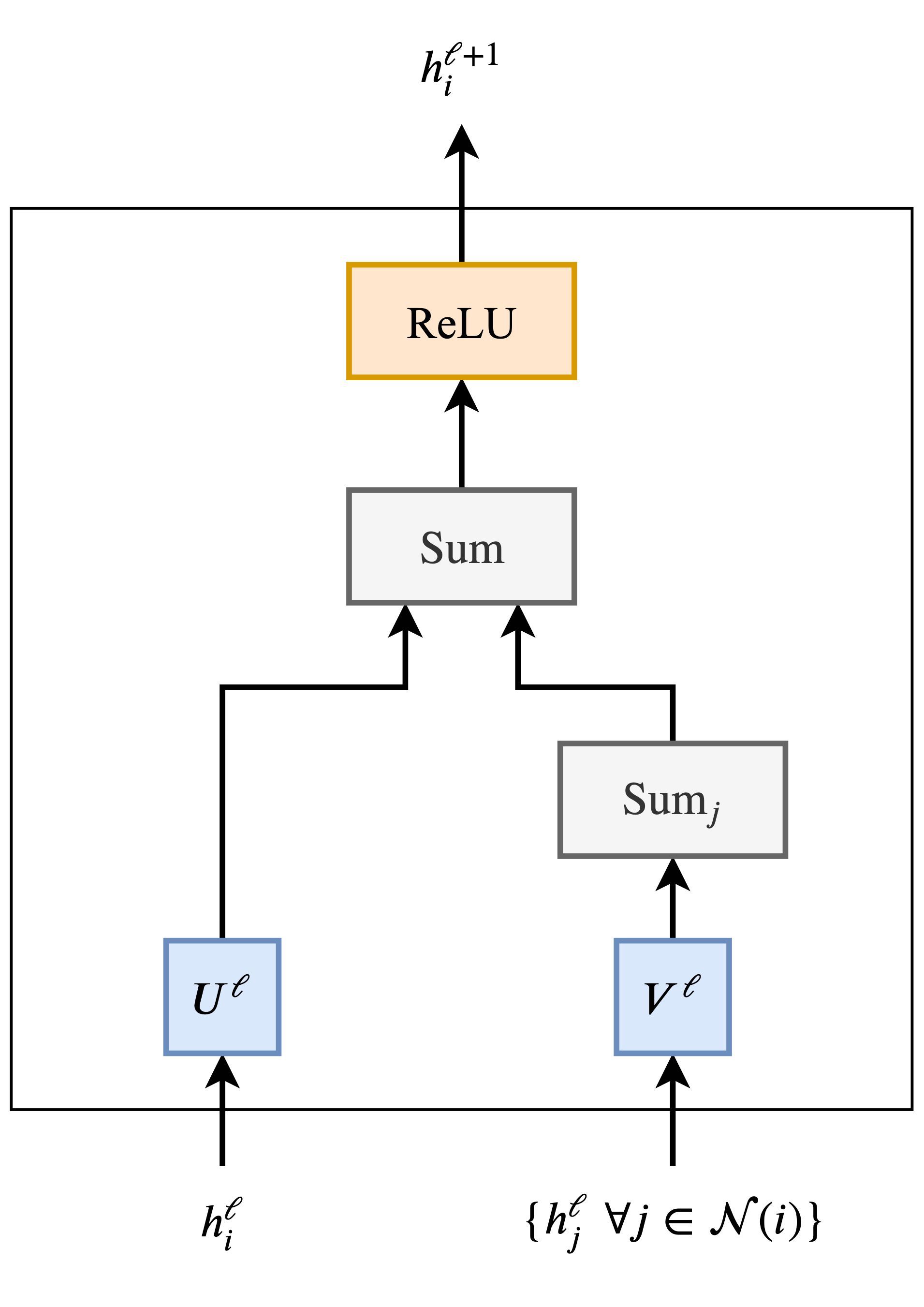
不同的aggregate function
max pool
待续
标签:node,inductive,graph,dataset,划分,edges,message,GNN,节点 来源: https://www.cnblogs.com/kalicener/p/15573728.html