yolox head
作者:互联网
yolox head
目录yolox head 网络
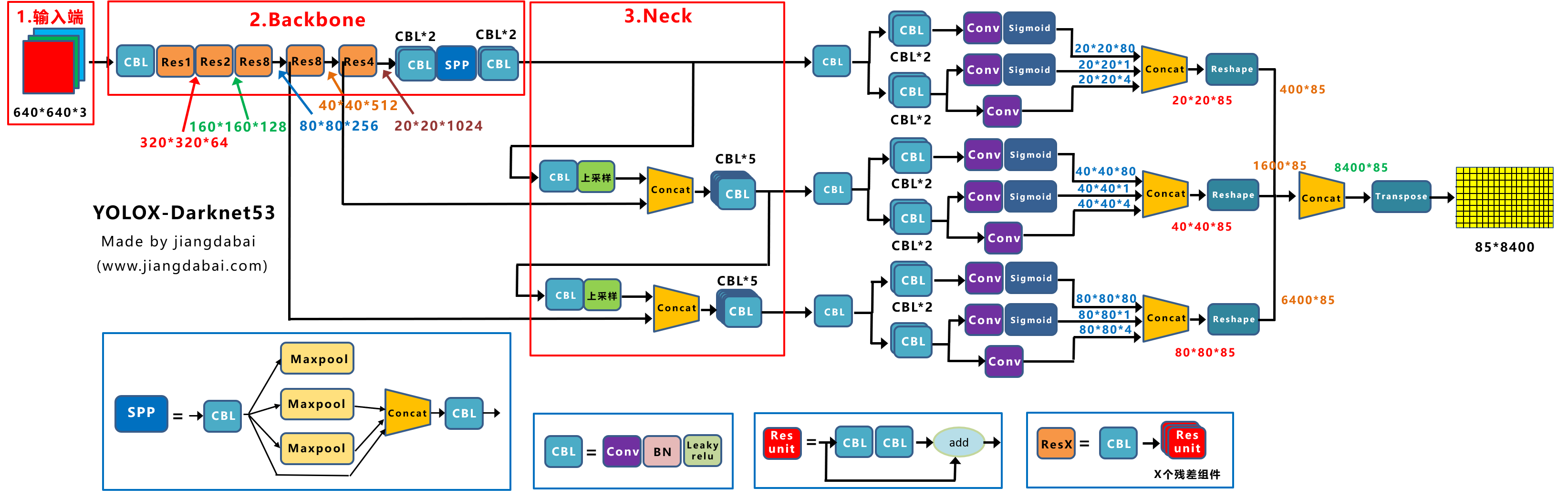
概述
yolox-head 包含了3个分支
- 三个大分支输入的是三种尺度特征图,
- 自下而上分别对应前面提到的backbone输出的dark3, dark4, dark5 。
- 尺度由大到小,堆叠成金字塔型。
代码位置: yolox/models/yolo_head.py 下的 YOLOhead 类
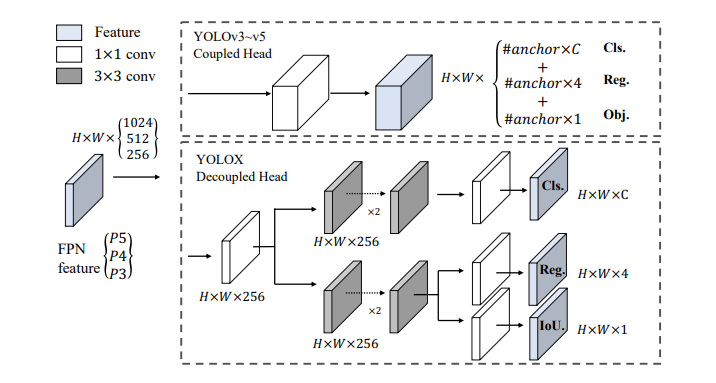
主体结构
self.cls_convs = nn.ModuleList() # 两个3x3的卷积
self.reg_convs = nn.ModuleList() # 两个3x3的卷积
# pred
self.cls_preds = nn.ModuleList() # 一个1x1的卷积,把通道数变成类别数,比如coco 80类
self.reg_preds = nn.ModuleList() # 一个1x1的卷积,把通道数变成4通道,因为位置是xywh
self.obj_preds = nn.ModuleList() # 一个1x1的卷积,把通道数变成1通道,判断有无目标
self.stems = nn.ModuleList() # 模前面的 BaseConv模块
初始化head,__init__
# 3个不同尺度的输出分支(对应dark3, dark4, dark5),期间用到的组件都是一样的
for i in range(len(in_channels)):
self.stems.append(
# 开头的 CBL 1x1 卷积 降维
BaseConv(
in_channels=int(in_channels[i] * width),
out_channels=int(256 * width),
ksize=1,
stride=1,
act=act,
)
)
# 两个分支,分类分支和回归分支
# 分类的卷积部分 开头包含两个卷积
self.cls_convs.append(
nn.Sequential(
*[
Conv(
in_channels=int(256 * width),
out_channels=int(256 * width),
ksize=3,
stride=1,
act=act,
),
Conv(
in_channels=int(256 * width),
out_channels=int(256 * width),
ksize=3,
stride=1,
act=act,
),
]
)
)
# 回归的卷积部分 包含了两层 卷积
self.reg_convs.append(
nn.Sequential(
*[
Conv(
in_channels=int(256 * width),
out_channels=int(256 * width),
ksize=3,
stride=1,
act=act,
),
Conv(
in_channels=int(256 * width),
out_channels=int(256 * width),
ksize=3,
stride=1,
act=act,
),
]
)
)
# 分类的预测部分 包含一层卷积,返回的是类别
self.cls_preds.append(
nn.Conv2d(
in_channels=int(256 * width),
out_channels=self.n_anchors * self.num_classes,
kernel_size=1,
stride=1,
padding=0,
)
)
# 回归的预测部分 包含了一层卷积,返回的是四维度坐标
self.reg_preds.append(
nn.Conv2d(
in_channels=int(256 * width),
out_channels=4,
kernel_size=1,
stride=1,
padding=0,
)
)
# 目标的预测部分,返回的是目标是否存在
self.obj_preds.append(
nn.Conv2d(
in_channels=int(256 * width),
out_channels=self.n_anchors * 1,
kernel_size=1,
stride=1,
padding=0,
)
)
head模型的forward
for k, (cls_conv, reg_conv, stride_this_level, x) in enumerate(
zip(self.cls_convs, self.reg_convs, self.strides, xin)):
# CBL卷积
x = self.stems[k](x)
cls_x = x
reg_x = x
# 分类-卷积
cls_feat = cls_conv(cls_x)
# 分类-预测
cls_output = self.cls_preds[k](cls_feat)
# 回归-卷积
reg_feat = reg_conv(reg_x)
# 回归-预测
reg_output = self.reg_preds[k](reg_feat)
# 目标-预测
obj_output = self.obj_preds[k](reg_feat)
# 同一层合并
output = torch.cat(
[reg_output, obj_output.sigmoid(), cls_output.sigmoid()], 1)
# 不同层叠加
outputs.append(output)
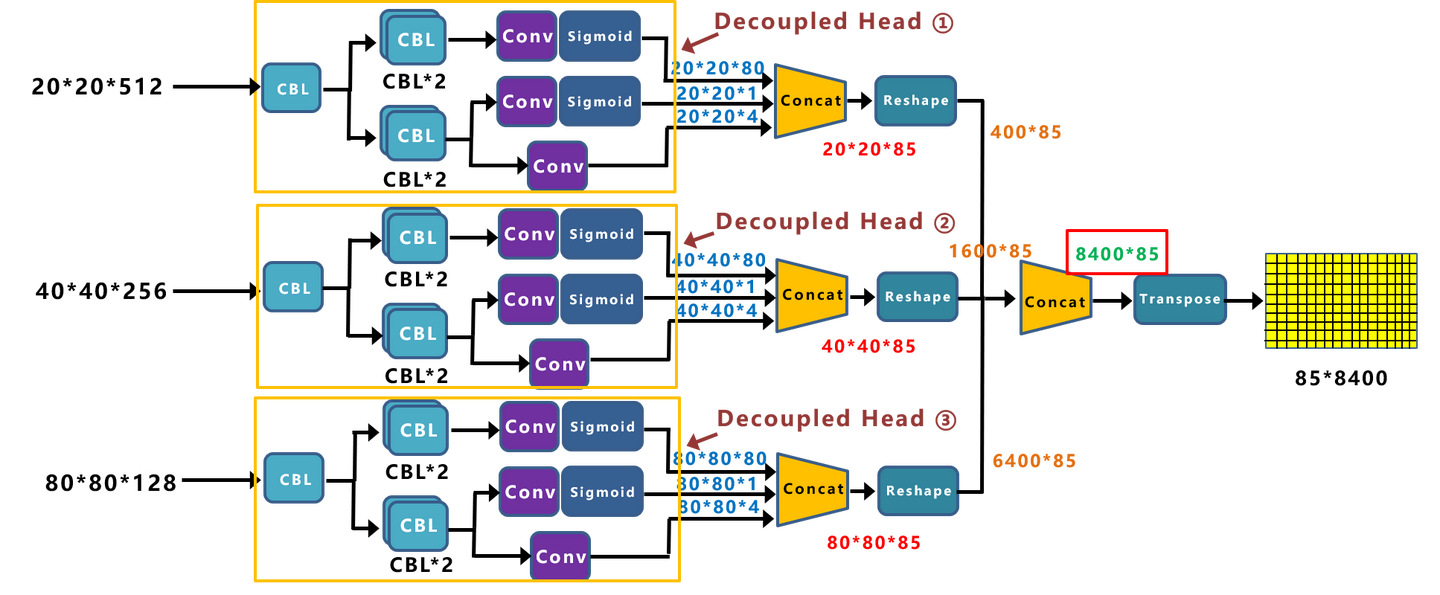
结果输出
concat + reshape + concat + transpose
- 三层特征经过
concat组件,是把分类和回归结果按channel维度,即dim=1拼接; - 然后是
reshape,将特征图展平成向量,(b,c,h,w) -> (b,c, h*w),h*w即预测anchor个数; - 按dim=2,
concat不同尺度下的输出,(b,c, h*w) -> (b,c, num_anchors); - 然后是转置操作,
(b,c, num_anchors) -> (b, num_anchors, c)。
# channel维度,将分类和回归分支结果拼接。
output = torch.cat(
[reg_output, obj_output.sigmoid(), cls_output.sigmoid()], 1
)
# 1, reshape + concat + transpose, (b,c,h,w) -> (b,c,h*w) -> (b,c, ?) -> (b, ?, c)
outputs = torch.cat(
[x.flatten(start_dim=2) for x in outputs], dim=2
).permute(0, 2, 1)
转置之后的输出维度是(b, num_anchors, c),其中每一行是一个预测的anchor信息。后面就是解码,即将这些输入翻译成对应的预测框。
解码
对网络的输出进行解码,这里需要解码信息是回归的位置信息(分类信息不需要解码),因为输出的xywh是相对位置,简单来说解码过程就是(x+x_c, y+y_c, w, h) * stride,即预测的相对于网格左上角偏移的位置加上网格的位置,再乘以下采样倍数,映射到原图位置。解码模块的输入是 (b, num_anchors, c)
def decode_outputs(self, outputs, dtype):
# outputs=(b, num_anchors, c)
grids = []
strides = []
# 计算每个尺度下所有网格的位置和对应的下采样倍数
for (hsize, wsize), stride in zip(self.hw, self.strides):
# yv和xv分别存储了每个网格的行和列。shape都是(hsize, wsize)
yv, xv = torch.meshgrid([torch.arange(hsize), torch.arange(wsize)])
# (hsize, wsize) -> (hsize, wsize, 2) -> (1, hsize*wsize, 2)
# 这样每一行对应的是一个网络的行列号。
grid = torch.stack((xv, yv), 2).view(1, -1, 2)
# 存储每个尺度下所有网格的位置和对应的下采样倍数
grids.append(grid)
shape = grid.shape[:2]
# (1, hsize*wsize, 1) 存储放大倍数
strides.append(torch.full((*shape, 1), stride))
# 多个(1,hsize*wsize,2) -> (1,all_num_grids,2),并转换类型。主要是把所有不同尺度下的网格位置信息拼接起来。
grids = torch.cat(grids, dim=1).type(dtype)
# 同理。 多个(1,hsize*wsize,1) -> (1,all_num_grids,1)
strides = torch.cat(strides, dim=1).type(dtype)
# x,y位置偏移outputs[..., :2], shape=(1, all_num_grids, 2)
# grids所有网格的xy行列号, shape=(1, all_num_grids, 2)
# strides所有网格的下采样倍数, shape=(1, all_num_grids, 1)
outputs[..., :2] = (outputs[..., :2] + grids) * strides
outputs[..., 2:4] = torch.exp(outputs[..., 2:4]) * strides
return outputs
yolo-backbone 和 yolo-head 结合
地址:yolox/models/yolox.py 中的 YOLOX 类型
注意:
backbone输出的是三个值- 在
head的forward第一个输入参数也是三个值
class YOLOX(nn.Module):
"""
YOLOX model module. The module list is defined by create_yolov3_modules function.
The network returns loss values from three YOLO layers during training
and detection results during test.
"""
def __init__(self, backbone=None, head=None):
super().__init__()
if backbone is None:
backbone = YOLOPAFPN()
if head is None:
head = YOLOXHead(80)
self.backbone = backbone
self.head = head
def forward(self, x, targets=None):
# fpn output content features of [dark3, dark4, dark5]
# fpnout 输出的是3个值
fpn_outs = self.backbone(x)
if self.training:
assert targets is not None
loss, iou_loss, conf_loss, cls_loss, l1_loss, num_fg = self.head(fpn_outs, targets, x)
outputs = {
"total_loss": loss,
"iou_loss": iou_loss,
"l1_loss": l1_loss,
"conf_loss": conf_loss,
"cls_loss": cls_loss,
"num_fg": num_fg,
}
else:
outputs = self.head(fpn_outs)
return outputs
参考博客:https://blog.csdn.net/jizhidexiaoming/article/details/119775002
参考博客:https://zhuanlan.zhihu.com/p/397993315
标签:channels,head,loss,self,yolox,reg,cls 来源: https://www.cnblogs.com/tian777/p/15329938.html