HBase2.0的修复工具HBCK2
作者:互联网
1. 背景
在了解HBCK2之前,建议先了解一下啥是HBCK。HBCK是HBase1.x中的命令,到了HBase2.x中,HBCK命令不适用,且它的写功能(-fix)已删除,它虽然还可以报告HBase2.x集群的状态,但是由于它不了解HBase2.x集群内部的工作原理,因此其评估将不准确。因此,如果你正在使用HBase2.x,那么对HBCK2应该需要了解一些,即使你不经常用到。
2. 获取HBCK2
HBCK2已经被剥离出HBase成为了一个单独的项目,如果你想要使用这个工具,需要根据自己HBase的版本,编译源码。其GitHub地址为:https://github.com/apache/hbase-operator-tools.git
默认HBase的版本是2.1.6,可以在父pom.xml文件里修改成你需要的版本,我们线上集群的版本是cdh-6.3.1-hbase2.1.0,与默认版本接近,因此我就使用默认的版本。
项目根目录下运行打包命令:
mvn clean install -DskipTests
编译成功后的截图:
Base-hbck2的target目录下可以找到我们最后需要的jar
把该jar包上传到集群随便一个目录下。
3. 测试命令是否可以正常使用
开始使用HBCK2的命令,最直接的使用方式:
./bin/hbase hbck -j <jar包地址> <命令>
使用HBCK2禁用启用测试表。
运行禁用表命令:
hbase hbck -j hbase-hbck2-1.1.0-SNAPSHOT.jar setTableState leo_test DISABLED
- hbase hbck -j hbase-hbck2-1.1.0-SNAPSHOT.jar 指定jar包的方式使用HBCK2命令
- setTableState 改变表状态的命令
- leo_test 表名
- DISABLED 禁用状态
看图,表的状态已经被更改为DISABLED

运行启用表命令:
hbase hbck -j hbase-hbck2-1.1.0-SNAPSHOT.jar setTableState leo_test ENABLED
看图,表的状态已经被更改为ENABLED

有个疑问就是,表状态被更改为DISABLED,这张表的region依然是online状态,表依然可以被正常查询。
以上操作顺利执行,就可以证明我们的HBCK2命令被安装成功了。
4. Procedure简介
HBase2集群几乎所有的操作都是通过procedure进行的,因此,HBCK2的工作实际就是修复各种不正常的procedure。
一个procedure是由一系列的操作组成,一旦完成,要么成功,要么失败(ROLL BACK),不存在中间状态,所以,procedure是支持事物的。
procedure执行的每一步都会以log的形式持久化在HBase的MasterProcWals目录下,这样master重启时也能通过日志来恢复之前的状态且继续执行。
对于运维而言最重要的一点就是procedure在执行过程中会拿好几把锁, 这个在处理问题时是很重要的,因为一旦锁没有释放,再做任何操作也只能是卡住等锁。
- IdLock:procedure级别的锁,保证一个procedure不会被多个线程同时执行。
- 资源锁:对HBase的内部资源进行加锁,不同的procedure加锁的粒度不同,目前有region/table/namespace/region server级别的锁。
举例来说,假设我assign一个region,那么procedure在执行的时候就需要对这个region进行加锁,这样如果有别的人想要unassign这个region,或者drop这个region所在的table,都需要等最早的assignment结束后释放锁了才能执行。这样防止有不一致的情况出现。
5. HBCK2核心功能介绍
5.1 bypass [OPTIONS] ...
bypass可以将一个或多个卡住的procedure进行释放。
原理是,在procedure的类里有一个bypass的flag,每次执行时会检查这个flag是否为true,如果为true则直接返回null,这样procedure就会被认为执行成功。
而bypass就是把这个procedure对象中的这个flag设为true。这样stuck的procedure就能够不再执行,后续的修复才能继续。
返回值为true则是成功,false是失败。
参数解析:
-o,--overide
在执行bypass之前先会尝试去拿idLock,如果procedure还在运行就会超时返回null,但是设置了这个参数,即使拿不到idLock也会去将procedure的bypass flag设为true。
-r, --recursive
在bypass一个procedure时也会将这个procedure的所有子procedure进行递归bypass是。例如我们bypass一个对table schema修改的procedure,就需要加上-r参数,才能把这个操作的所有子procedure都bypass掉。
-w, --lockWait
上面提到的等到idLock的超时时间配置,默认为1ms。
5.2 assigns [OPTIONS] <ENCODED_REGIONNAME> ...
将一个或多个region再次随机assign到别的机器上,返回值时创建的pid则为成功,-1则为失败。
参数解析:
-o, --override
这里的override跟bypass的override不同,因为assign本身就会创建一个新的procedure,所以肯定是不涉及到拿idLock的,但是这里涉及到资源锁的问题。因为之前卡住的资源锁即使在bypass后也不会释放(用于fence, 防止更多未知的错误操作),所以需要加一个-o去手动释放这个资源锁。
下面,我们实际运行一下这个命令,感受其作用。
hbase hbck -j hbase-hbck2-1.1.0-SNAPSHOT.jar assigns -o leo_test,,1588902855503.596a8c918380a9fb55ed64ecf716ecd6.
- leo_test,,1588902855503.596a8c918380a9fb55ed64ecf716ecd6. 这个是我测试表,leo_test的一个region的encoded_name
命令执行的结果是:

返回值为-1,说明命令运行失败。
十有八九是我的region name指定错了,重新运行如下命令。
hbase hbck -j hbase-hbck2-1.1.0-SNAPSHOT.jar assigns -o 596a8c918380a9fb55ed64ecf716ecd6
命令执行的结果是:

可以看到,成功返回了此次procedure的ID,观察HBase自带的监控界面。

HBCK2的命令提交成功后,监控界面会显示此次操作的记录,里面可以查看命令运行的详细状态。
查看表的监控界面,发现我们操作的region依然在72那台机器上,看起来好像没有任何变化。不知道是不是由于我们测试的表只有一个region的缘故,于是,我又测试了一张有17个region的表。
除了master有这样的日志之外,还是没有任何效果。

暂时实在搞不明白这条命令的具体效果,以后再慢慢研究吧,接着来看下一个核心功能。
5.3 unassigns [OPTIONS] <ENCODED_REGIONNAME> ...
将一个或多个region unassign,返回值是创建的pid则为成功,-1则为失败。
参数解析:
-o,--override,与assigns的一致
5.4 setTableState
可能的table状态, ENABLED, DISABLED, DISABLING, ENABLING
在table的状态和所有的region状态不一致时可以用这个命令进行修复
5.5 serverCrashProcedures ...
手动schedule一个或多个serverCrashProcedure, 如果有serverCrashProcedure没有执行成功,但是procedure log已经丢失了,那么可以利用这个命令进行修复。返回值为创建的pid则为成功,-1则为失败。
patch在HBASE-21393[3],目前这个功能在release版本还没有。

看样子应该能用,可现在就是不知道咋用。
6. 利用HBCK2来查找集群的问题
6.1 canary tool
模拟用户的读写请求,去访问集群上的表。当我们需要检查集群meta上记录的region assignment跟实际region server上打开的region是否一致时,可以使用这个命令去检查:
hbase canary -f false -t 6000000
nohup hbase canary -f false -t 6000000 > /data/leo_jie/hbase.log 2>&1 &
这个命令会向meta上的记录的每个region发送一个get请求,将-f设为false是为了不在遇到第一个错误时退出,-t则是这个命令的超时时间,我们设成了6000秒。在执行完成以后可以通过grep ERROR来找到那些有问题的region。
需要注意的是因为是模拟客户端发送的get请求,最好将HBase的客户端超时时间和超时次数配的小一些,否则会很慢。
PS: canary 本身也很适合用来作为集群可用性的监控,有兴趣的同学可以去了解一下。
cat /data/leo_jie/hbase.log | grep ERROR
grep ERROR 来发现是否有异常信息。
6.2 页面状态
其实大部分的信息都会在master的页面上展示出来,我们来详细的介绍一下:

可以检查当前所有没有执行完的procedure以及所有资源锁,当我们想要assign或者unassign一个region时,需要先去检查下是由有别的procedure已经占有了这个资源锁,如果是的话需要现将那个procedure bypass掉,或者等待那个procedure释放锁。
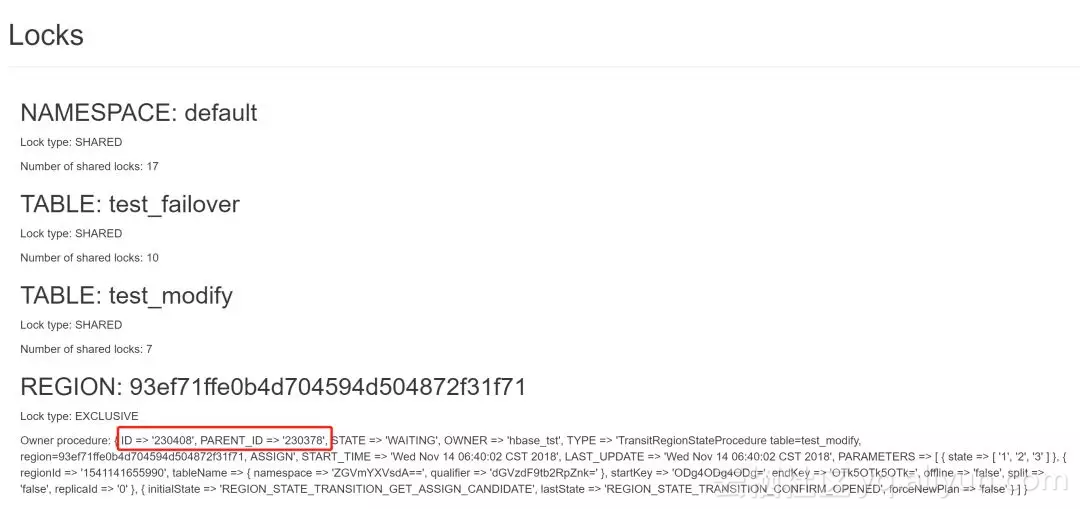
可以看到EXCLUSIVE的lock只有region级别的,图中红框圈出来的就是占有这个锁的procedure id以及它的parent procedure id, 由此我们知道如果想要重新assign/unassign这个region,那么一定要bypass这个procedure。
同理,当Locks这块没有任何EXLUSIVE锁时,我们可以放心的去执行操作而不用担心被卡住。
以上内容节选自,HBase指南 | HBase 2.0之修复工具HBCK2运维指南,因为我在本地测试的时候,没有重现这种锁占用的情况。
6.3 OPENING/CLOSING region的查找
branch-2.0 上最容易出现的问题就是region卡在了OPENNING/CLOSING状态,一般处于这两种状态的region都会在rit的队列中,可以通过点击页面上的链接拿到所有的region以及对应的procedure id。
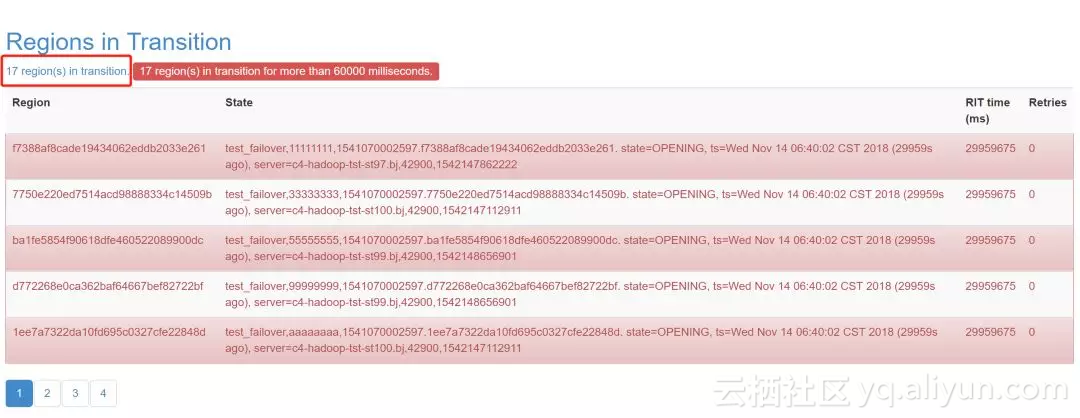
可以看到现在有17个region处在transition中,我们可以点击红框圈住的这个链接,会展示所有的region。
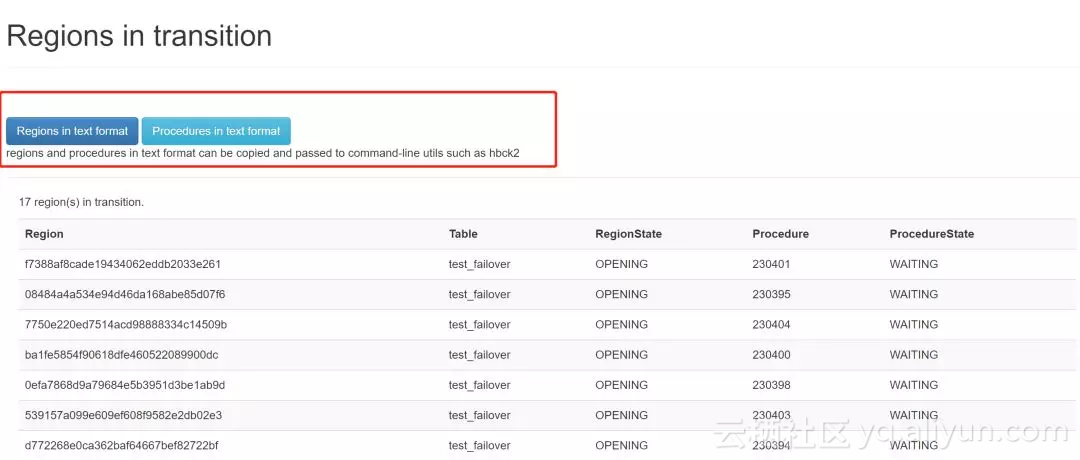
因为我们最后是希望通过HBCK2来进行处理,那么最好是可以复制粘贴需要处理的region或者procedure, 所以可以点击圈出的这两个按钮,会以text形式展示所有region或者所有procedure。

以上内容依旧是节选,因为没遇到RIT的情况,同时,我们也不希望遇见。
标签:修复,region,HBase2.0,HBCK2,bypass,hbase,HBase,procedure
来源: https://www.cnblogs.com/leojie/p/15023028.html
可能的table状态, ENABLED, DISABLED, DISABLING, ENABLING
在table的状态和所有的region状态不一致时可以用这个命令进行修复
5.5 serverCrashProcedures ...
手动schedule一个或多个serverCrashProcedure, 如果有serverCrashProcedure没有执行成功,但是procedure log已经丢失了,那么可以利用这个命令进行修复。返回值为创建的pid则为成功,-1则为失败。
patch在HBASE-21393[3],目前这个功能在release版本还没有。
看样子应该能用,可现在就是不知道咋用。
6. 利用HBCK2来查找集群的问题
6.1 canary tool
模拟用户的读写请求,去访问集群上的表。当我们需要检查集群meta上记录的region assignment跟实际region server上打开的region是否一致时,可以使用这个命令去检查:
hbase canary -f false -t 6000000
nohup hbase canary -f false -t 6000000 > /data/leo_jie/hbase.log 2>&1 &
这个命令会向meta上的记录的每个region发送一个get请求,将-f设为false是为了不在遇到第一个错误时退出,-t则是这个命令的超时时间,我们设成了6000秒。在执行完成以后可以通过grep ERROR来找到那些有问题的region。
需要注意的是因为是模拟客户端发送的get请求,最好将HBase的客户端超时时间和超时次数配的小一些,否则会很慢。
PS: canary 本身也很适合用来作为集群可用性的监控,有兴趣的同学可以去了解一下。
cat /data/leo_jie/hbase.log | grep ERROR
grep ERROR 来发现是否有异常信息。
6.2 页面状态
其实大部分的信息都会在master的页面上展示出来,我们来详细的介绍一下:
可以检查当前所有没有执行完的procedure以及所有资源锁,当我们想要assign或者unassign一个region时,需要先去检查下是由有别的procedure已经占有了这个资源锁,如果是的话需要现将那个procedure bypass掉,或者等待那个procedure释放锁。
可以看到EXCLUSIVE的lock只有region级别的,图中红框圈出来的就是占有这个锁的procedure id以及它的parent procedure id, 由此我们知道如果想要重新assign/unassign这个region,那么一定要bypass这个procedure。
同理,当Locks这块没有任何EXLUSIVE锁时,我们可以放心的去执行操作而不用担心被卡住。
以上内容节选自,HBase指南 | HBase 2.0之修复工具HBCK2运维指南,因为我在本地测试的时候,没有重现这种锁占用的情况。
6.3 OPENING/CLOSING region的查找
branch-2.0 上最容易出现的问题就是region卡在了OPENNING/CLOSING状态,一般处于这两种状态的region都会在rit的队列中,可以通过点击页面上的链接拿到所有的region以及对应的procedure id。
可以看到现在有17个region处在transition中,我们可以点击红框圈住的这个链接,会展示所有的region。
因为我们最后是希望通过HBCK2来进行处理,那么最好是可以复制粘贴需要处理的region或者procedure, 所以可以点击圈出的这两个按钮,会以text形式展示所有region或者所有procedure。
以上内容依旧是节选,因为没遇到RIT的情况,同时,我们也不希望遇见。
标签:修复,region,HBase2.0,HBCK2,bypass,hbase,HBase,procedure 来源: https://www.cnblogs.com/leojie/p/15023028.html