内存分配对多线程程序性能的影响【转】
作者:互联网
转自:https://www.oracle.com/technetwork/cn/articles/servers-storage-admin/1557798_ZHS
如果您的应用程序在新的多处理器、多核、多线程硬件上运行时不能伸缩,问题可能在于内存分配器中的锁争用。下文提供了一些工具以识别该问题并选择一个更好的分配器。
简介
您的新服务器刚刚投产。该服务器有多个插槽、数十个内核、数百个虚拟 CPU。是您提出了新服务器建议,为之争取到了预算,并且最后实现了该方案。现在,服务器已投产。
但是且慢,在为该服务器配置的数百个线程中,似乎只有少数几个处于忙碌状态。事务处理速度远不如预期。系统利用率只有 25%。您该向谁求助?您该怎么办?更新您的简历?
|
不要惊慌,先检查一下应用程序的锁使用情况!开发高效、可伸缩、高度线程化的应用程序非常具有挑战性。操作系统开发人员面临同样的挑战,尤其是在内存分配的功能领域。
术语
在本文中,插槽 是一个芯片,一片 CPU 硬件。插槽携带内核。内核通常由自己的整数处理单元和一级(有时是二级)缓存组成。硬件线程、导线束 或虚拟 CPU (vCPU) 是一组寄存器。vCPU 彼此共享一级缓存等资源。大多数操作系统将 vCPU 数量报告为 CPU 计数。
背景
从前,程序和操作系统是单线程的。程序在运行时可以访问和控制全部系统资源。在 UNIX 系统上运行的应用程序使用 malloc() API 分配内存,使用 free() API 释放内存。
那时,调用 malloc() 不仅会增加进程可以使用的地址空间,还会增加与地址空间关联的随机存取内存 (RAM)。按需分页操作系统的出现改变了这一切。调用 malloc() 仍然会增加应用程序可以使用的地址,但在访问页面之前,不会分配 RAM。sbrk() 和 brk() API 用来增加应用程序可以使用的地址空间。
人们常常误以为 free() 会减少程序大小(地址空间)。尽管 sbrk()/brk() 提供的地址空间可以通过向 sbrk() 传递负值来缩小,但实际上,free() 并未实现这一技术,因为它要求以地址空间分配时的相同幅度来减少地址空间。
通常,当空闲内存量过低导致页扫描程序运行或应用程序退出时,与地址空间关联的 RAM 将返回给内核。这正是内存映射文件发挥作用之处。将文件映射到程序地址空间的功能提供了另一种增加地址空间的方法。一个明显的区别是,当内存映射文件取消映射时,与取消映射地址范围关联的 RAM 将返回给内核,进程的总地址空间将缩小。
多核硬件系统带来了多线程操作系统和多线程应用程序。于是,可能有多个程序组件需要同时增加地址空间。需要某种方法来同步这些活动。
最初,使用单进程锁来确保对 libc 中的 malloc() 和 free() 内受保护区域的单线程访问。实际上,对于线程数量很少的应用程序或很少使用 malloc() 和 free() API 的应用程序,单锁当然工作得不错。但在具有大量 CPU 的系统上运行的高线程应用程序可能会遇到可伸缩性的问题,这种应用程序会由于 malloc 和 free 锁争用而降低预期事务处理速度。
如何识别该问题
默认情况下,大多数 UNIX 操作系统使用 libc 中的 malloc() 或 free() 版本。在 Oracle Solaris 中,对 malloc() 和 free() 的访问是由一个进程专用锁来控制的。在 Oracle Solaris 中,第一个用于确定是否存在锁争用的工具是带 -mL 标志的 prstat(1M),采样时间间隔为 1。
以下是某个应用程序使用两个线程时的 prstat 输出。一个线程在调用 malloc(),另一个在调用 free()。
PID USERNAME USR SYS TRP TFL DFL LCK SLP LAT VCX ICX SCL SIG PROCESS/LWPID 4050 root 100 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0 51 0 0 malloc_test/2 4050 root 97 3.0 0.0 0.0 0.0 0.0 0.0 0.0 0 53 8K 0 malloc_test/3
prstat 输出为进程中的每个线程提供了一行信息。有关每列的描述,请参见手册页面。这里我们感兴趣的是 LCK 列,它反映了在上一采样周期线程用于等待用户级锁的百分比时间。清单 1 显示了同一应用程序使用 8 个线程时的输出。
清单 1. 8 线程 prstat 输出
PID USERNAME USR SYS TRP TFL DFL LCK SLP LAT VCX ICX SCL SIG PROCESS/LWPID 4054 root 100 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0 52 25 0 malloc_test/8 4054 root 100 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0 52 23 0 malloc_test/7 4054 root 100 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0 54 26 0 malloc_test/6 4054 root 100 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0 51 25 0 malloc_test/9 4054 root 94 0.0 0.0 0.0 0.0 5.5 0.0 0.0 23 51 23 0 malloc_test/3 4054 root 94 0.0 0.0 0.0 0.0 5.6 0.0 0.0 25 48 25 0 malloc_test/4 4054 root 94 0.0 0.0 0.0 0.0 6.3 0.0 0.0 26 49 26 0 malloc_test/2 4054 root 93 0.0 0.0 0.0 0.0 6.7 0.0 0.0 25 50 25 0 malloc_test/5
使用 8 个线程时,我们开始看到出现一些锁争用。清单 2 显示 16 线程的输出。
清单 2. 16 线程 prstat 输出
PID USERNAME USR SYS TRP TFL DFL LCK SLP LAT VCX ICX SCL SIG PROCESS/LWPID 4065 root 63 37 0.0 0.0 0.0 0.0 0.0 0.0 51 222 .4M 0 malloc_test/31 4065 root 72 26 0.0 0.0 0.0 1.8 0.0 0.0 42 219 .3M 0 malloc_test/21 4065 root 66 30 0.0 0.0 0.0 4.1 0.0 0.0 47 216 .4M 0 malloc_test/27 4065 root 74 22 0.0 0.0 0.0 4.2 0.0 0.0 28 228 .3M 0 malloc_test/23 4065 root 71 13 0.0 0.0 0.0 15 0.0 0.0 11 210 .1M 0 malloc_test/30 4065 root 65 9.0 0.0 0.0 0.0 26 0.0 0.0 10 186 .1M 0 malloc_test/33 4065 root 37 28 0.0 0.0 0.0 35 0.0 0.0 36 146 .3M 0 malloc_test/18 4065 root 38 27 0.0 0.0 0.0 35 0.0 0.0 35 139 .3M 0 malloc_test/22 4065 root 58 0.0 0.0 0.0 0.0 42 0.0 0.0 28 148 40 0 malloc_test/2 4065 root 57 0.0 0.0 0.0 0.0 43 0.0 0.0 5 148 14 0 malloc_test/3 4065 root 37 8.1 0.0 0.0 0.0 55 0.0 0.0 12 112 .1M 0 malloc_test/32 4065 root 41 0.0 0.0 0.0 0.0 59 0.0 0.0 40 108 44 0 malloc_test/13 4065 root 23 15 0.0 0.0 0.0 62 0.0 0.0 23 88 .1M 0 malloc_test/29 4065 root 33 2.9 0.0 0.0 0.0 64 0.0 0.0 7 91 38K 0 malloc_test/24 4065 root 33 0.0 0.0 0.0 0.0 67 0.0 0.0 42 84 51 0 malloc_test/12 4065 root 32 0.0 0.0 0.0 0.0 68 0.0 0.0 1 82 2 0 malloc_test/14 4065 root 29 0.0 0.0 0.0 0.0 71 0.0 0.0 5 78 10 0 malloc_test/8 4065 root 27 0.0 0.0 0.0 0.0 73 0.0 0.0 5 72 7 0 malloc_test/16 4065 root 18 0.0 0.0 0.0 0.0 82 0.0 0.0 3 50 6 0 malloc_test/4 4065 root 2.7 0.0 0.0 0.0 0.0 97 0.0 0.0 7 9 18 0 malloc_test/11 4065 root 2.2 0.0 0.0 0.0 0.0 98 0.0 0.0 3 7 5 0 malloc_test/17
使用 2 线程和 8 线程时,进程的大部分时间都用在处理上。但使用 16 线程时,可以看到有些线程大部分时间都花在等待锁上。但是等待的是哪个锁呢?为回答这个问题,我们将使用一个 Oracle Solaris DTrace 工具 plockstat(1M)。我们关注的是争用事件 (-C)。将对一个已经运行的进程 (-p) 监视 10 秒钟 (-e 10)。
plockstat -C -e 10 -p `pgrep malloc_test` 0 Mutex block Count nsec Lock Caller 72 306257200 libc.so.1`libc_malloc_lock malloc_test`malloc_thread+0x6e8 64 321494102 libc.so.1`libc_malloc_lock malloc_test`free_thread+0x70c
第一个 0 来自于旋转计数。(遗憾的是,Oracle Solaris 10 中存在一个错误,妨碍了精确确定旋转计数)。此错误在 Oracle Solaris 11 中已得到修复。)
我们将看到线程被锁定次数的计数 (Count) 以及每次阻塞发生的平均时间(以纳秒计,nsec)。如果锁有名称 (Lock),则会显示出来,同时还显示阻塞发生时的堆栈指针 (Caller)。结果是,有 136 次为获得同一锁而等待十分之三秒,这严重影响了性能。
在数十个(如果不是数百个话)核上运行的 64 位高线程应用程序的出现导致了对多线程感知内存分配器的明确需要。Oracle Solaris 设计为附带两个多线程依赖 (MT-hot) 内存分配器:mtmalloc 和 libumem。还有一个著名的、公开提供的名为 Hoard 的多线程依赖分配器。
Hoard
Hoard 由 Emery Berger 教授编写。它已付诸商用,为许多著名的公司所采用。
Hoard 追求提供速度和可伸缩性,避免伪共享,并减少碎片。伪共享发生在不同处理器上的线程意外共享缓存行时。伪共享妨碍缓存的高效使用,从而对性能产生负面影响。当进程所消耗的实际内存超过应用程序的实际内存需要时,会出现碎片。您可以将碎片视为浪费的地址空间或某种内存泄漏。当线程专用池有可分配的地址空间但另一个线程无法使用它时,就可能发生这种情况。
Hoard 维护线程专用堆和一个全局堆。通过在这两种类型的堆之间动态分配地址空间,Hoard 能够减少或防止碎片化,并且还允许线程重用最初由另一线程分配的地址空间。
基于线程 ID 的哈希算法将线程映射到堆。各个堆组织成一系列超级块,每个块是系统页大小的倍数。大于超级块一半大小的分配使用 mmap() 分配,并使用 munmap() 取消映射。
每个超级块容纳大小一致的分配。空的超级块将得以重用并可以分配给新类。此特性可减少碎片。(详情参见 Hoard:适用于多线程应用程序的可伸缩内存分配器。)
本文所使用的 Hoard 版本为 3.8。在 Hoard.h 中存在以下定义:
#define SUPERBLOCK_SIZE 65536 .
SUPERBLOCK_SIZE 是超级块的大小。因此任何大于超级块一半大小(即 32 KB)的分配将使用 mmap()。

图 1. Hoard 简化架构
mtmalloc 内存分配器
与 Hoard 类似,mtmalloc 维护半专用堆和一个全局堆。使用 mtmalloc,会创建两倍于 CPU 数目的存储段。使用线程 ID 索引到某个存储段。每个存储段包含一个缓存链接列表。每个缓存包含一些特定大小的分配。每个分配上调到 2 的 n 次方的分配。例如,100 字节的请求将填充为 128 字节,结果给出 128 字节的缓存。
每个缓存是一个块链接列表。当缓存耗尽可用空间时,将调用 sbrk() 分配新块。块的大小可调。大于阈值 (64k) 的分配将从全局超大存储段进行分配。
有针对每个存储段的锁,也有针对每个缓存的锁。还有一个锁是用于超大分配的。(请参见 opensolaris.org 上的 malloc.c。)

图 2. mtmalloc 简化架构
libumem 内存分配器
libumem 是 SunOS 5.4 中引入的 slab 分配器的用户端实现。(详情参见 Slab 分配器:对象缓存内核内存分配器和弹仓与 Vmem:将 Slab 分配器扩展到多 CPU 和任意资源。)
slab 分配器缓存普通类型的对象以便快速重用。slab 是内存中的一片连续区域,分割成固定大小的块。libumem 使用一种称为弹仓 (magazine) 层的 CPU 专用缓存结构。
弹仓 本质上是一个堆栈。我们将分配从堆栈顶部弹出,将释放的分配推入堆栈。当堆栈触底时,将从 vmem 层(仓库)重新装填弹仓。此 vmem 分配器为弹仓提供了一个通用后备存储。(弹仓会自我动态调优,因此可能会花几分钟时间“准备 slab”以达到最佳性能。)libumem 会小心填充数据结构以确保每个数据结构都有自己的缓存行,从而降低伪共享的可能。
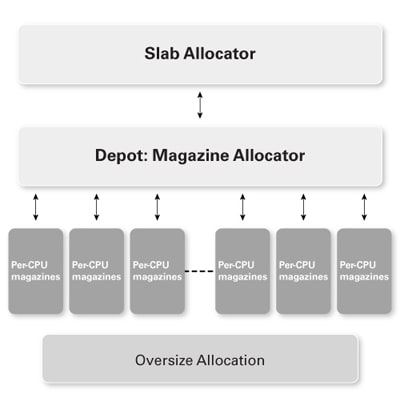
图 3. libumem 简化架构
新 mtmalloc 内存分配器
mtmalloc 已实现重写,并首先用于 Oracle Solaris 10 8/11。现在可用于 Oracle Solaris 11 中。(请参见 libmtmalloc 性能改进。)
取消了保护每个缓存的锁,对被保护信息的更新使用原子操作来完成。保存最后一次分配发生位置的指针以方便查询。
数组链接列表取代了缓存链接列表,数组中的每一项指向一个缓存。这有助于引用的局部性,从而改进性能。在设置某些标志后,ID 小于两倍 vCPU 数的线程会收到独占式内存存储段,从而消除了对存储段专用锁的使用。
64 位应用程序增量缓存增长的默认大小为 64,而不是原来的 9。在以下讨论中,使用独占式存储段的新 mtmalloc 算法称为“新的独占式 mtmalloc”,当不使用独占式存储段时,则称其为“新的非独占式 mtmalloc”。
测试工具
但哪个是最好的分配器呢?
为了评估每种方法的性能,开发了一种测试工具,它完成以下工作:
- 基于输入参数创建若干分配线程
- 为每个分配线程创建一个释放线程
- 根据输入参数每个循环执行一定数量的分配
- 对循环计数以作为关注的量度
- 使用随机数发生器(参见
man rand_r)选择每个分配的大小
最大分配大小为输入参数。我们将使用每循环 5000 个分配并让每个测试运行大约 1200 秒。将使用 256、1024、4096、16384 和 65536 字节的最大分配大小。
此外,我们将使用 LD_PRELOAD_64 指示链接程序预加载要测试的库。使用 LD_PRELOAD 也是在生产中实现每个库的一种方法。另一种使用不同内存分配器的方法是在编译应用程序时链接库(例如 -lmtmalloc)。
下面对输入参数进行了说明,源代码可在我的博客中找到(参见 Malloc 测试工具)。
测试程序 malloc_test 接受以下标志:
-h显示帮助。-c指定样本计数(要发布的三秒样本数)。-t指定线程计数。-s指定是否对分配使用memset;0= 否,1= 是。-m指定最大分配大小(字节)。-r指定使用随机数发生器确定分配大小。-n指定每循环分配数;最大为 5000。-f指定执行固定次数的循环,然后程序退出;0= 否,xx= 循环次数。
可以使用 DTrace 检查分配大小的分布。以下显示 4-KB 最大分配的分布:
Date: 2011 May 27 12:32:21 cumulative malloc allocation sizes
malloc
value ------------- Distribution ------------- count
< 1024 |@@@@@@@@@@ 2331480
1024 |@@@@@@@@@@ 2349943
2048 |@@@@@@@@@@ 2347354
3072 |@@@@@@@@@@ 2348106
4096 | 18323
5120 | 0
以下是 DTrace 代码:
/* arg1 contains the size of the allocation */
pid$target::malloc*:entry
{ @[probefunc]=lquantize(arg1,1024,16684,1024); }
tick-10sec
{ printf("\n Date: %Y cumulative malloc allocation sizes \n", walltimestamp);
printa(@);
exit(0); }
测试结果
初始测试在一台基于 UltraSPARC T2 的服务器上运行,该服务器有 1 个插槽、8 个内核、64 个硬件线程以及 64 GB 的 RAM。内核版本为 SunOS 5.10 Generic_141444-09。结果显示了超大分配的可伸缩性问题,如表 1 所示。
另一测试在一台基于 UltraSPARC T3 的服务器上运行,该服务器有 2 个插槽、32 个内核、256 个硬件线程以及 512 GB 的 RAM。内核版本为 SunOS 5.10 Generic_144408-04。对于这第二次测试,只使用小于 4 KB 的分配以避免超大大小问题。结果(平均每秒循环次数)汇总于表 1 下半部分。可以看到新的独占式 mtmalloc 算法性能出色(绿色),而 Hoard 和 libumem 在高线程计数情况下存在一些可伸缩性问题(红色)。每个系统中的 RAM 量是无关的,因为我们测试的是地址空间或空页的分配。
表 1. 分配器性能比较
| 每秒循环次数 (lps) | lps | lps | lps | lps | lps | lps |
|---|---|---|---|---|---|---|
| 线程计数/ 分配大小 (UltraSPARC T2) | Hoard | mtmalloc | umem | 新的独占式mtmalloc | 新的非独占式mtmalloc | libcmalloc |
| 1 线程 256 字节 | 182 | 146 | 216 | 266 | 182 | 137 |
| 4 线程 256 字节 | 718 | 586 | 850 | 1067 | 733 | 114 |
| 8 线程 256 字节 | 1386 | 1127 | 1682 | 2081 | 1425 | 108 |
| 16 线程 256 字节 | 2386 | 1967 | 2999 | 3683 | 2548 | 99 |
| 32 线程 256 字节 | 2961 | 2800 | 4416 | 5497 | 3826 | 93 |
| 1 线程 1024 字节 | 165 | 148 | 214 | 263 | 181 | 111 |
| 4 线程 1024 字节 | 655 | 596 | 857 | 1051 | 726 | 87 |
| 8 线程 1024 字节 | 1263 | 1145 | 1667 | 2054 | 1416 | 82 |
| 16 线程 1024 字节 | 2123 | 2006 | 2970 | 3597 | 2516 | 79 |
| 32 线程 1024 字节 | 2686 | 2869 | 4406 | 5384 | 3772 | 76 |
| 1 线程 4096 字节 | 141 | 150 | 213 | 258 | 179 | 92 |
| 4 线程 4096 字节 | 564 | 598 | 852 | 1033 | 716 | 70 |
| 8 线程 4096 字节 | 1071 | 1148 | 1663 | 2014 | 1398 | 67 |
| 16 线程 4096 字节 | 1739 | 2024 | 2235 | 3432 | 2471 | 66 |
| 32 线程 4096 字节 | 2303 | 2916 | 2045 | 5230 | 3689 | 62 |
| 1 线程 16384 字节 | 110 | 149 | 199 | 250 | 175 | 77 |
| 4 线程 16384 字节 | 430 | 585 | 786 | 1000 | 701 | 58 |
| 8 线程 16384 字节 | 805 | 1125 | 1492 | 1950 | 1363 | 53 |
| 16 线程 16384 字节 | 1308 | 1916 | 1401 | 3394 | 2406 | 0 |
| 32 线程 16384 字节 | 867 | 1872 | 1116 | 5031 | 3591 | 49 |
| 1 线程 65536 字节 | 0 | 138 | 32 | 205 | 151 | 62 |
| 4 线程 65536 字节 | 0 | 526 | 62 | 826 | 610 | 43 |
| 8 线程 65536 字节 | 0 | 1021 | 56 | 1603 | 1184 | 41 |
| 16 线程 65536 字节 | 0 | 1802 | 47 | 2727 | 2050 | 40 |
| 32 线程 65536 字节 | 0 | 2568 | 38 | 3926 | 2992 | 39 |
| 线程计数/ 分配大小 (UltraSPARC T3) | Hoard | mtmalloc | umem | 新的独占式mtmalloc | 新的非独占式mtmalloc | |
| 32 线程 256 字节 | 4597 | 5624 | 5406 | 8808 | 6608 | |
| 64 线程 256 字节 | 8780 | 9836 | 495 | 16508 | 11963 | |
| 128 线程 256 字节 | 8505 | 11844 | 287 | 27693 | 19767 | |
| 32 线程 1024 字节 | 3832 | 5729 | 5629 | 8450 | 6581 | |
| 64 线程 1024 字节 | 7292 | 10116 | 3703 | 16008 | 12220 | |
| 128 线程 1024 字节 | 41 | 12521 | 608 | 27047 | 19535 | |
| 32 线程 4096 字节 | 2034 | 5821 | 1475 | 9011 | 6639 | |
| 64 线程 4096 字节 | 0 | 10136 | 1205 | 16732 | 11865 | |
| 128 线程 4096 字节 | 0 | 12522 | 1149 | 26195 | 19220 |
评论和结果
哪个内存分配器最佳取决于应用程序的内存使用模式。在任何情况下,使用超大分配将导致分配器成为单线程的。
新的独占式 mtmalloc 算法具有可调超大阈值的优点。如果您在应用程序中可以使用独占标志,则新的独占式 mtmalloc 可提供显然最高的性能。但如果您无法使用独占标志,在最多 16 线程的情况下 libumem 可提供最高性能。当测量地址空间的分配速度时,系统中的内存量并不有利于任何算法。考虑图 4 中的 4-KB 分配图。
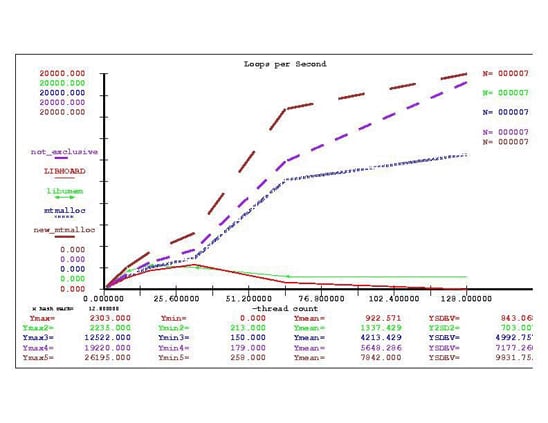
图 4. Hoard、mtmalloc 和 libumem 的每秒循环次数
如您所见,当从 32 线程升到 64 线程时,libumem 和 Hoard 会遇到可伸缩性下降,即应用程序的每秒事务数实际下降的问题。
作为调优练习,我们可以试验提高每线程堆数的各种选项。这里的 mtmalloc 分配器可以持续伸缩,其中新的带独占选项的 mtmalloc 表现出最高性能,新的非独占式 mtmalloc 表现出持续可伸缩性。
性能
为进一步检查每种方法的性能,我们将检查线程在执行时的资源配置文件。在 Oracle Solaris 中,这可以使用 procfs 接口来完成。
使用 tpry,可以收集有关测试工具的 procfs 数据(参见 tpry,基于 procfs 的线程监视 SEToolkit 风格)。我们可以使用 newbar 以图形方式检查测试工具的线程(参见 newbar:后处理可视化工具)。
图 5 到图 9 中图形的颜色指示以下内容:
- 红色表示用于内核的时间百分比。
- 绿色表示用于用户模式的时间百分比。
- 橙色表示用于等待锁的时间百分比。
- 黄色表示用于等待 CPU 的时间百分比。
如您所见,由于每个条代表 100% 的时间间隔,Hoard 和 libumem 存在数量不等的锁争用(橙色)。
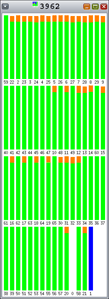 图 5. Hoard:一些锁争用 |
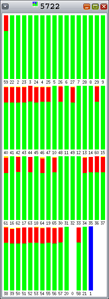 图 6. |
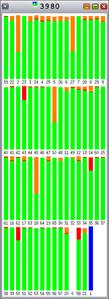 图 7. |
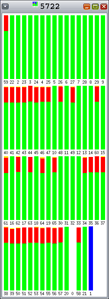 图 8. 新的非独占式 |
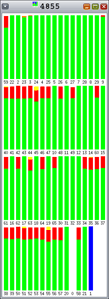 图 9. 新的独占式 |
还需注意,Hoard 未伸缩到 128 线程。要对此进一步调查,可以查看从 procfs 得到的数据。回忆一下,绿色表示用于用户模式的时间百分比,红色表示用于内核模式的时间百分比。我们看到内核模式(红色)的 CPU 时间增加。参见图 10。
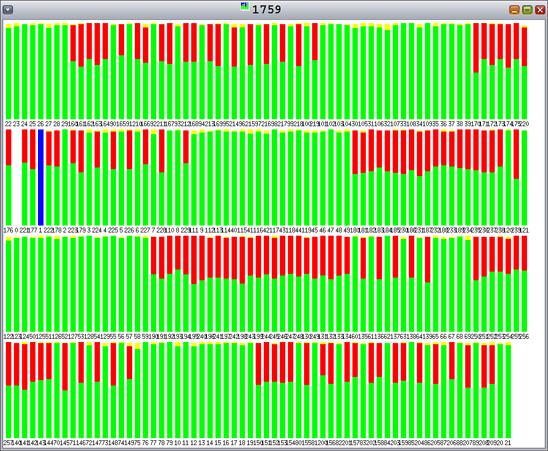
图 10. 带 128 个分配线程、128 个释放线程以及 4-KB 分配的 Hoard — 用于内核模式的时间增加
使用 DTrace 和 truss -c (man -s 1 truss),我们确定最常执行的系统调用是 lwp_park。为进一步调查,使用以下 DTrace 脚本查看对应用程序执行最常用系统调用时的堆栈:
syscall::lwp_park:entry
/ pid == $1 /
{ @[pid,ustack(3)]=count();
self->ts = vtimestamp; }
tick-10sec
{ printf("\n Date: %Y \n", walltimestamp);
printa(@);
trunc(@); }
当测试工具使用 Hoard、128 个分配线程以及 128 个释放线程时在基于 UltraSPARC T3 的服务器上执行该脚本,将看到清单 3 所示的输出。
清单 3. 脚本的输出
12 57564 :tick-10sec
Date: 2011 May 31 17:12:17
3774 libc.so.1`__lwp_park+0x10
libc.so.1`cond_wait_queue+0x4c
libc.so.1`cond_wait_common+0x2d4 826252
12 57564 :tick-10sec
Date: 2011 May 31 17:12:27
3774 libc.so.1`__lwp_park+0x10
libc.so.1`cond_wait_queue+0x4c
libc.so.1`cond_wait_common+0x2d4 891098
可以看出,Hoard 正在调用 libc.so.1`cond_wait_common+0x2d4,并且很显然,正在反复检查条件变量。
另一方面,libumem 存在锁争用(请回忆,橙色表示用于等待锁的时间百分比),如图 11 所示。
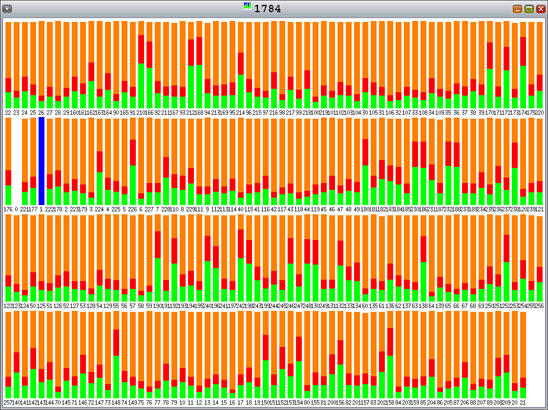
图 11. 128 个分配线程、128 个释放线程以及 4-KB 分配情况下的 libumem — 锁争用
新的独占式 mtmalloc 算法避免了锁争用,如图 12 所示。
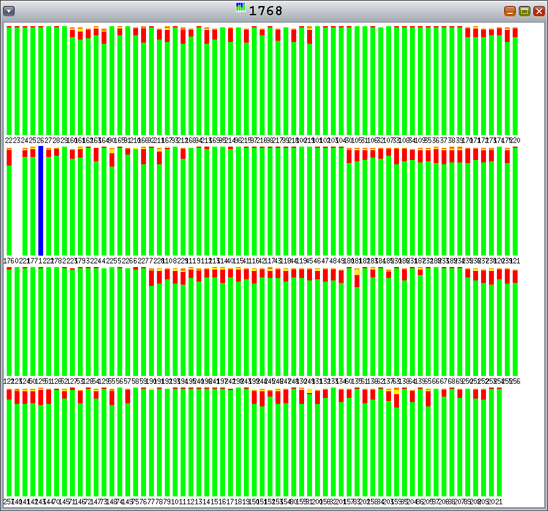
图 12. 128 个分配线程和 128 个释放线程情况下的新的独占式 mtmalloc — 无锁争用
碎片化
为了比较这些分配器使用系统内存的效率,对 4-KB 分配重复测试。
在此测试中,使用 memset 访问所有分配的内存地址,从而确保 RAM 与每个地址关联。每隔 3 秒对应用程序进行一次测试,查看是否执行了固定次数的分配循环。当达到分配限制时,指示全部线程停止并释放其分配。
然后使用 ps 命令估算应用程序在退出前的驻留集大小 (RSS)。大小以千字节为单位,越小越好。
表 2. 碎片化
| 线程计数/ 分配大小 | Hoard | mtmalloc | umem | 新的独占式 mtmalloc | 新的非独占式 mtmalloc |
|---|---|---|---|---|---|
| 32 线程 4096 字节 | 1,073,248 | 1,483,840 | 570,704 | 1,451,144 | 1,451,144 |
libumem 在内存占用量上胜出,其原因可以这么解释:弹仓从 CPU 专用层返回到仓库。Hoard 也将空的超级块返回全局缓存。
每种算法都有自己的优点。Hoard 不负其减小碎片的美名,而 mtmalloc 牺牲了地址空间和内存约束以提高性能。
所有分配器都有针对分配模式“调优”分配器的选项。为获得最高性能,您必须针对应用程序的需要考虑这些选项。这些结果表明,对于内存占用量较小的系统来说,使用 libumem 和 Hoard 会更好。
libumem 在达到最高性能之前有一个更明显的启动爬升阶段。图 13 比较了在 20 分钟运行期间的头 5 分钟内的性能。
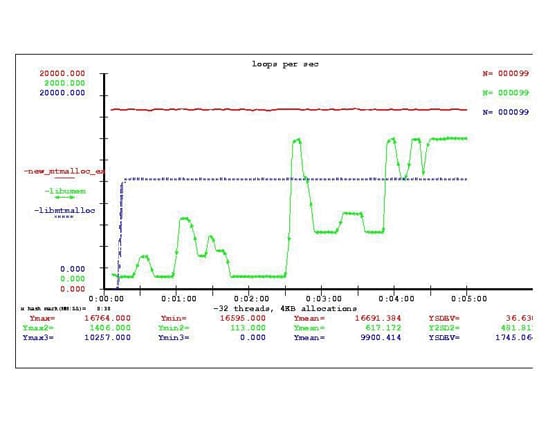
图 13. 启动性能比较
总结
随着系统越来越依赖于大规模并行以提高可伸缩性,让操作环境适于运行新的高线程应用程序变得非常重要。选择内存分配器时必须考虑到应用程序的架构和操作约束。
如果低延迟(速度)很重要并且需要快速启动,则使用新的非独占式 mtmalloc 分配器。此外,如果应用程序使用长生命周期的线程或线程池,请启用独占特性。
如果需要以较低的 RAM 占用取得合理的可伸缩性,则 libumem 比较合适。如果您有生命周期短、内存需求超大的代码段,Hoard 将自动使用 mmap(),这样,调用 free() 时将释放地址空间和 RAM。
资源
以下是本文前面所引用的资源:
- Hoard:http://www.hoard.org/
- “Hoard:适用于多线程应用程序的可伸缩内存分配器”:http://www.cs.umass.edu/~emery/hoard/asplos2000.pdf
- opensolaris.org 上的
malloc.c:http://src.opensolaris.org/source/xref/onnv/onnv-gate/usr/src/lib/libmalloc/common/malloc.c - “Slab 分配器:对象缓存内核内存分配器”:http://www.usenix.org/publications/library/proceedings/bos94/bonwick.html
- “弹仓和 Vmem:将 Slab 分配器扩展到多个 CPU 和任意资源”:http://www.usenix.org/event/usenix01/full_papers/bonwick/bonwick_html/index.html
- “
libmtmalloc性能改进”:http://arc.opensolaris.org/caselog/PSARC/2010/212/libmtmalloc_onepager.txt - “Malloc 测试工具”:https://blogs.oracle.com/rweisner/entry/test_harness_for_malloc
- “tpry,基于 procfs 的线程监视 SEToolkit 风格”:https://blogs.oracle.com/rweisner/entry/tpry_procfs_based_thread_monitoring
- “newbar:后处理可视化”:https://blogs.oracle.com/rweisner/entry/newbar_a_post_proceesing_visualization
| 修订版 1.0,2012 年 3 月 8 日 |
通过 Facebook、Twitter 或 Oracle 博客关注我们。
标签:malloc,字节,0.0,程序,线程,内存,分配器,test,多线程 来源: https://www.cnblogs.com/sky-heaven/p/15978866.html