CMU 15-445 数据库课程第五课文字版 - 缓冲池
作者:互联网
熟肉视频地址:
今天的课程是关于期待已久的缓冲池的话题,其实就是 DBMS 如何管理它的内存并从磁盘来回移动数据,我们希望DBMS自己来管理这些内存与磁盘存储交换的操作,而不是把它留给操作系统。你可以从两个方面考虑数据库存储和内存管理问题:

第一个是空间控制,也就是我们从物理上考虑在磁盘上写页的位置,我们要把页面存储在磁盘的什么地方,以达到最大的收益。我们的目标是让页保持在一起,如果有一些页经常被我们的应用程序同时访问我们把它们连续地放在磁盘上。这么做的原因是顺序访问磁盘比随机访问消耗小得多野快得多。
我们需要考虑的第二个方面是时间控制。这意味着当我们从磁盘取页到内存时,我们希望 DBMS 能够以一种最小化磁盘 I/O 的方式来实现这一点:如果有一个您需要访问的页,而它目前不在内存中,那么就需要从磁盘读取,会有一个等待页从磁盘载入内存的 I/O 阻塞,我们想尽量避免这些,也就是 DBMS 需要找到一种有效的方法,将在同一时间被访问的页面以最少的 I/O 次数同时保存在内存中。

我们这样做的主要原因也是因为相对于访问内存,直接访问磁盘的耗时大太多了,是不可以接受的。所以,作为 DBMS 工程师,找出一种有效的方法来维护这个缓冲池,尽可能地将数据保存在内存中,这对我们来说是非常重要的
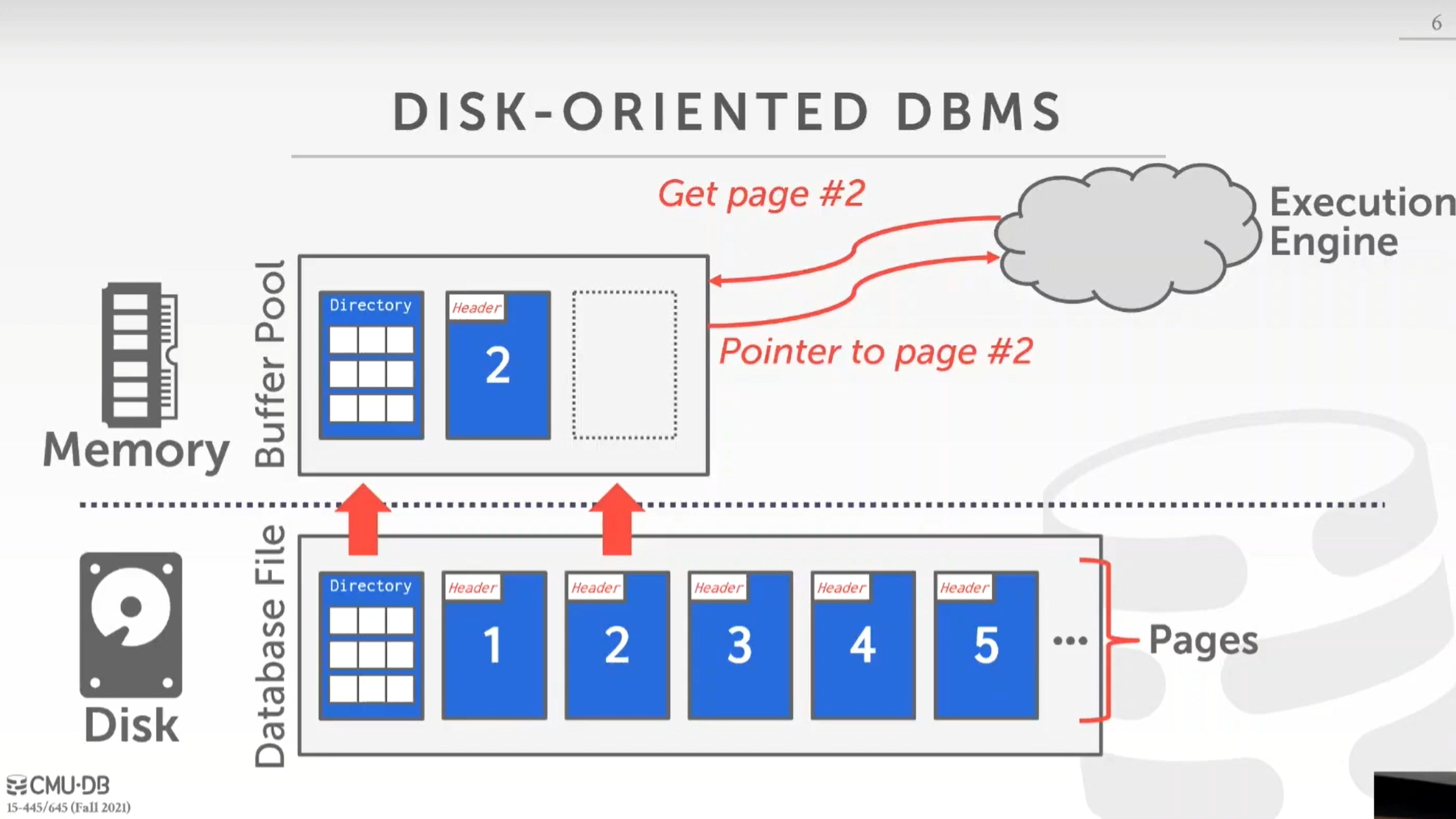
到目前为止,我们一直在讨论磁盘上面的数据库文件,这些文件被分成了很多页,并且有目录页,它存储从页 id 到文件中的物理位置或偏移量的映射。在磁盘文件上面有我们的缓冲池(Buffer Pool),它为执行引擎(Execution Engine)服务
例如:我们有一个执行引擎发出一个请求访问第二页,缓冲池中没有第二页,缓冲池要做的是,首先将文件目录加载到内存中,找出第二页的物理位置,然后获取它,这样我们就能返回一个内存中的第二页的指针给执行引擎。
以上是整个缓冲池如何工作的一个大概的例子,具体来说,我们今天这节课要讲的主题还是关于缓冲池的高级概念:

特别是缓冲池管理器(Buffer Pool Manager),即软件中负责管理缓冲池的部分,我们会看一下缓冲池管理器使用的不同算法。包括替换策略,如何决定哪些页要读取到内存,哪些页要从内存中删除,最后我们会看一些其他类型的可能存在于 DBMS 中的内存池。

缓冲池的结构是一个固定大小的页的数组,每一个数组条目都被称为一个帧(Frame):它是磁盘上的数据库文件的页的大小,这样我们就可以把磁盘上的页映射到缓冲池的数组槽中。当 DBMS 请求一个页时,我们要做的就是将页复制到缓冲池中的这些帧中。
实际上,我们现在还需要一个间接层才能访问这些页,即通过页表(Page Table)
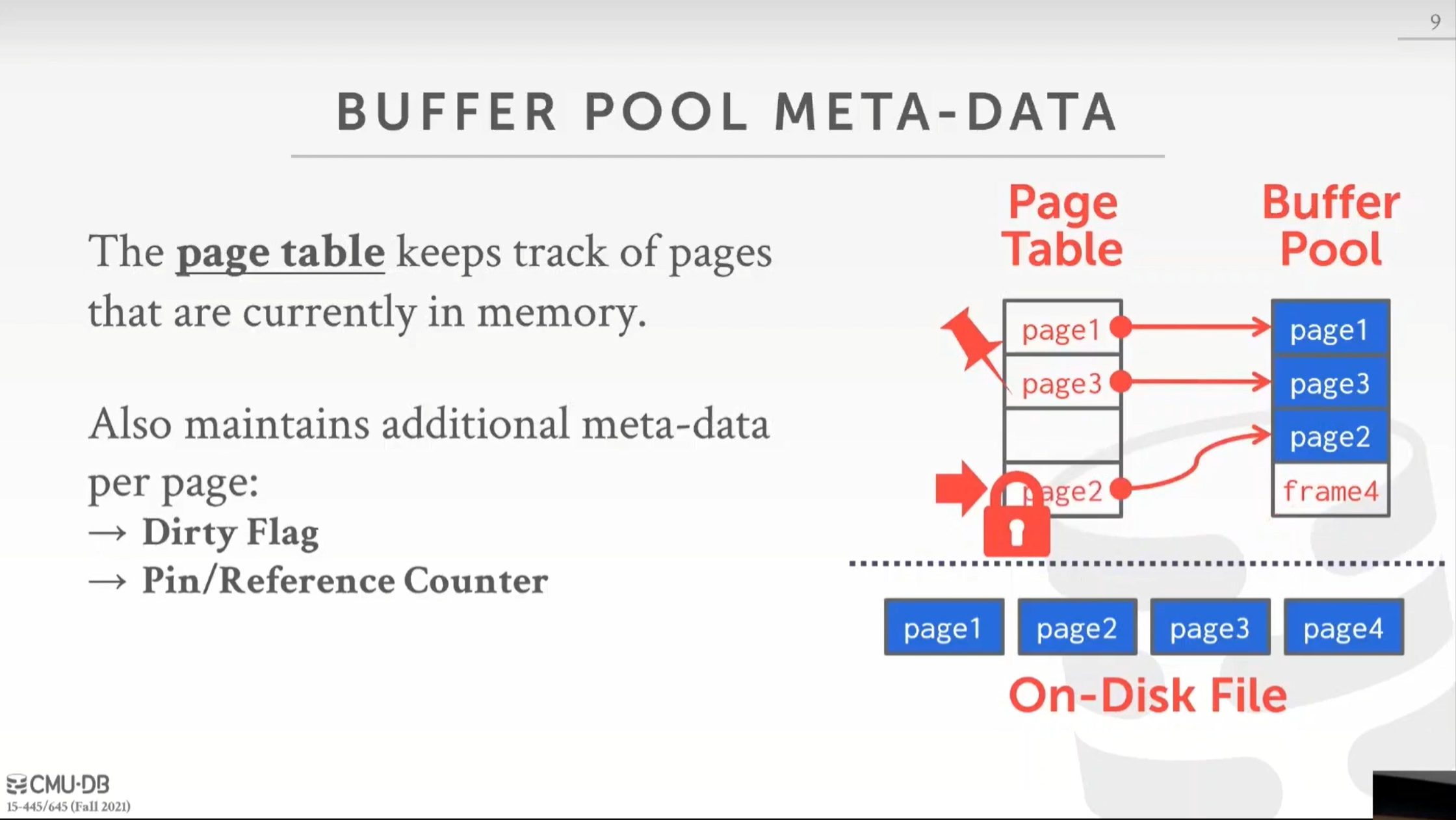
页表实际上记录了存储在内存中的页的映射,类似于数据库磁盘文件的文件头的槽页。页目录记录页在磁盘上的位置,页表则是会记录页的布局,以及它们在内存缓冲池中的位置。这里我们有从第一页和第三页到缓冲池中的帧的映射,页表还将负责维护关于每个页的一些额外元数据,例如:
- dirty 标记:是一个布尔值,告诉我们页在加载到内存后是否被修改过。
- pin 标记或者引用计数:如果我们想要一个还会被使用的页留在缓冲池的内存中,我们不希望它被删除,我们可以用 pin 标记这一页。或者通过记录引用计数让我们知道哪些页还在被查询使用。
- Latch锁存器:如果我们有一堆并发的查询,我们有多个线程或查询都访问试图修改这个页表,一般需要在页表的一个位置设置一个锁存器,来防止并发修改。
这里我们需要理清一个重要的概念区别,即锁(Lock)与锁存器(Latch)

在数据库世界中的锁与锁存器,与操作系统中的锁与锁存器的概念是不一样的。在数据库的世界中:
- 锁(Lock):指的是对于数据库的逻辑抽象的保护,例如锁的可以是整张表,也可以是索引,也可以是元组,这些都是与DBMS相关的逻辑抽象。锁通常在事务期间获取并保持,并且要考虑事务回滚
- 锁存器(Latch):我们通常指的是保护某些底层关键部分的短暂的锁存器,比如保护一个内部数据结构或者数据库管理系统中发生的修改,我们不需要能够回滚这些改变。有点类似于 Mutex(互斥锁)
下一个我们想搞清楚的是页目录(Page Directory)与页表(Page Table)的区别:

页目录就是从页id到页物理位置的映射,它需要被持久化,这样就算重启我们也可以加载以便追踪我们可能需要的各个页。
页表在内存中,它是临时的。我们不需要持久化这个页表,页表可以在我们执行查询时逐步建立。
一个问题:在内存中设置了页表某一帧的 dirty 位后,如果掉电,我们会丢失对页面的更新吗?会的,如果在缓冲池中有一些页被设置了脏位,这意味着它们被一些查询修改了,它们还没有持久化到磁盘上。但是后面我们会讨论到事务保证,如果你有一个事务,那么这个事务直到所有的更改都以某种方式(后面我们会知道通过一种类似于写入提前写日志(WAL,Write Ahead Log)的方式)持久化到磁盘上之前才会提交完成,以保证事务的完整性不受宕机影响。

我们如何决定哪些页会存在于我们的缓冲池中?一般有两种策略:
- 全局策略(Global Policies):根据系统中在同一时间并发运行的所有查询进行综合考虑
- 本地策略(Local Policies):基于每个查询来加载和移除页,但是也会有页的共享

一些缓冲池优化方式:
- 多缓冲池(Multiple Buffer Pools):多个同时使用多个并发缓冲池而不是一个
- 缓存预取(Pre-fetching):提前将一些加载到缓冲池减少 I/O
- 扫描共享(Scan Sharing):多个查询共享一个扫描的结果
- 绕过缓冲池(Buffer Pool Bypass):对于某些查询,不通过缓冲池以防污染

我们从多缓冲池(Multiple Buffer Pools)的概念开始:从逻辑上讲 DBMS 有一种缓冲池,你可以把页从磁盘加载到内存中,但在物理上,它可以被实现为具有不同策略的多个单独的缓冲池。例如你的系统管理多个并发数据库,每一个都可以有自己的缓冲池。例如你可以针对不同的页类型有不同的缓冲池,例如表的页,索引的页,这些可以由完全独立的缓冲池处理。
它有很多优点,减少锁存器争用,并且可以每个缓冲池针对不同的需求使用不同的优化策略(例如针对查询的,数据库的,不同类型页的缓冲池)。但是也引入了一个问题:你如何判断你有一个页,你想让它存在与唯一一个缓冲池?

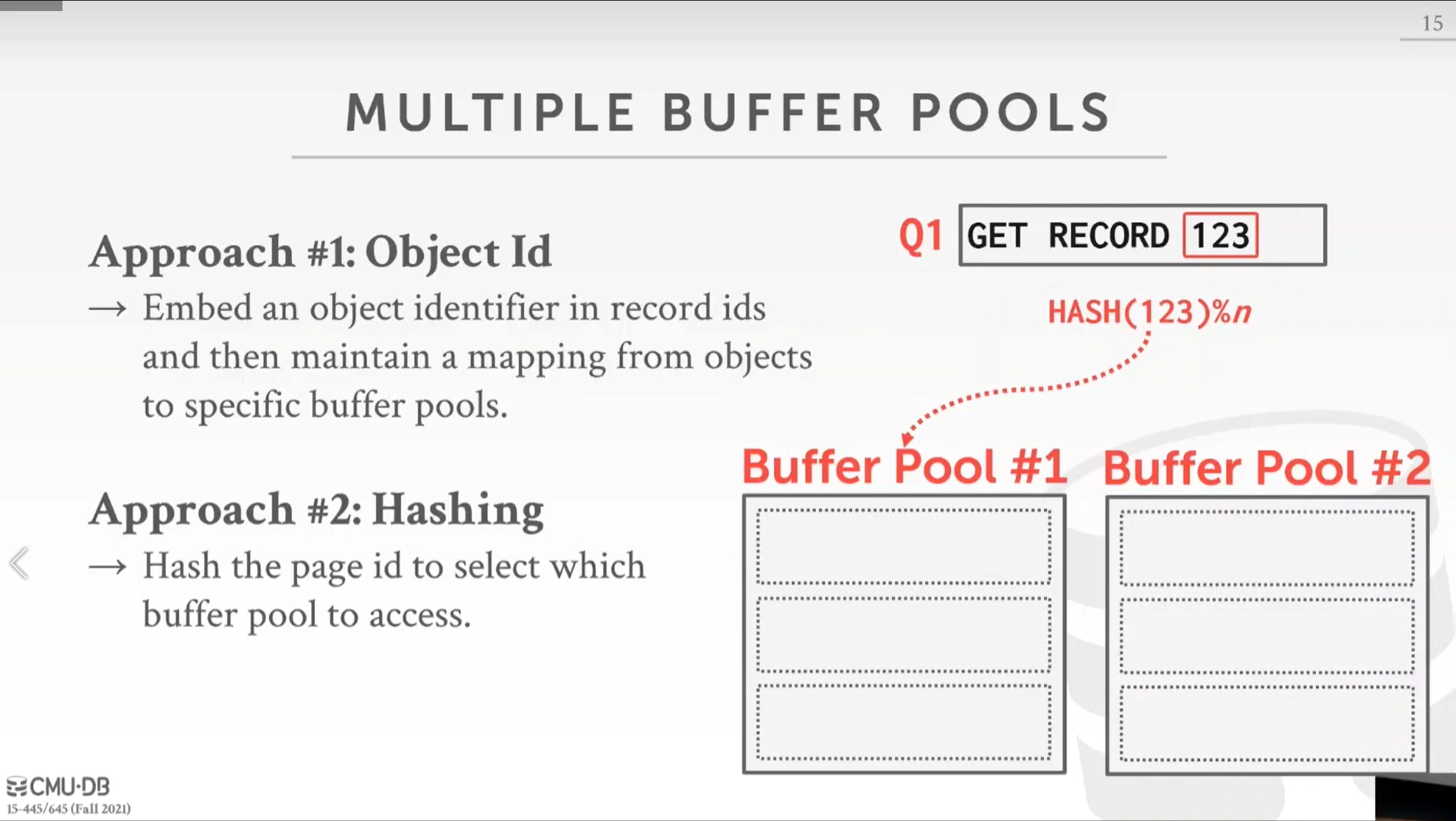
有两种常用的方法:
- 第一种方法是当你存储页时你存储一些与之相关的对象 id(Object Id):例如这里对象id是指页类型,它可以是一个存储元组和表的页,它可以是存储部分索引数据结构的页,可能是存储日志记录的页。举一个实例:假设 Q1 查询想得到记录 123,根据前面的课程,我们知道这个 123 可以解析出数据库中这个记录的位置信息,这里这个位置信息包括 ObjectId,PageId,SLotNum,根据 ObjectId 去对应的缓冲池寻找。
- 第二种方法是取哈希值:还是对于 Q1 查询想得到记录 123,对于这个记录取哈希值,然后对独立缓冲池的数量取余数得出该去哪个缓冲池去查询。

我们要讲的下一个重要优化是缓存预取(Pre-fetching),这种想法是 DBMS 可以根据查询计划在实际需要之前预取页。假设我们有一个查询 Q1 执行顺序查询扫描所有页,DBMS 可以执行一些数据预取,比如在开始扫描第 0 页的时候,就把第 0,1,2 页都加载到缓冲池中。之后到第 3 页的时候,第 0,1,2 页不再使用,可以被替换成 3,4,5 页,这样查询不用在扫描每一页的时候都阻塞。

我们接下来看这样一个查询,查询 val 在 100 ~ 250 之间的所有记录,这个查询是可以通过索引优化不用扫描所有页的。索引会在后面的课程详细讲。
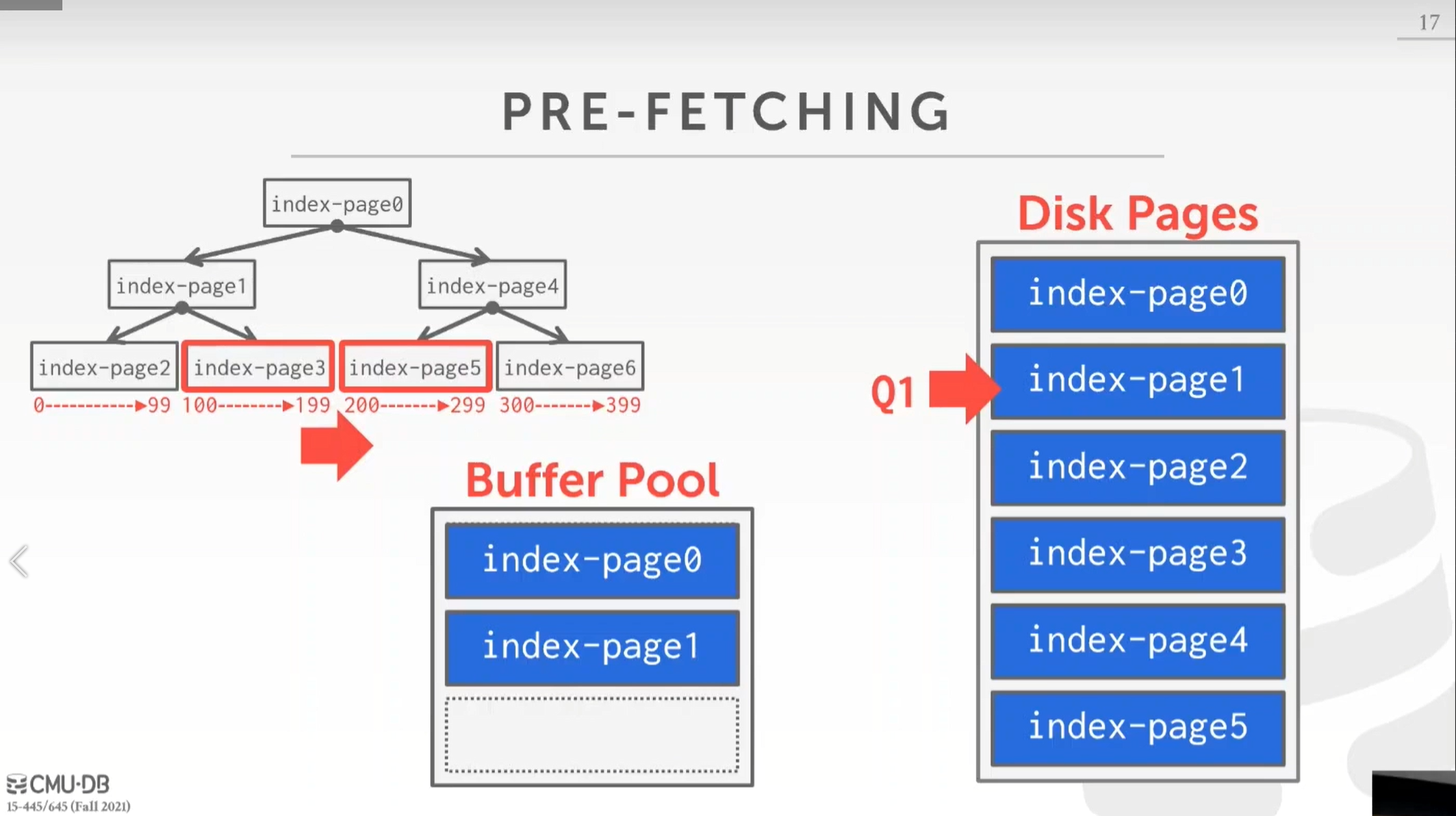
目前对于 val 这个索引,你可以把它想象成一个平衡二叉树。我们将从这个根页(index-page0)开始,之后搜索左子树 index-page1,然后找到 index-page3,由于叶子节点互相之间是有指针连接起来相当于一个双向链表,所以我们不必重新遍历二叉树就能找到 index-page5。这样我们就找到了索引中我们所有要扫描的页。
这个例子告诉我们预取需要根据数据结构以及扫描方式做出改变,并不是一直顺序扫描的
问题:你怎么知道你应该分配多少资源来做预取?学术界有很多关于预取的研究,在商业系统中,是一个很大的卖点,更好的预取应该是可以计算出你知道用这种方式预取需要付出多少资源,如果你花费太多资源做预取,那么你就会阻碍系统进行的实际工作;而如果你什么都不做,就会出现太多 I/O 阻塞。所以这是你在两者之间必须达成一种微妙的平衡。
下一个是扫描共享(Scan Sharing)

其基本思想是查询可以重用从存储中检索的数据,这也被称为同步扫描(Synchronized scans),它不同于结果缓存。结果缓存主要是针对某个特定查询的,对于不同的查询一般不会生效。扫描共享则是不必是一样的查询,但是可以共享中间结果的。

如果一个查询从磁盘读取页,并将它们放入内存,可以让另一个需要访问相同页的查询重用它们,它允许多个查询附加到一个正在扫描表的游标上。查询不一定是一样的,但是他们需要访问相同的页。
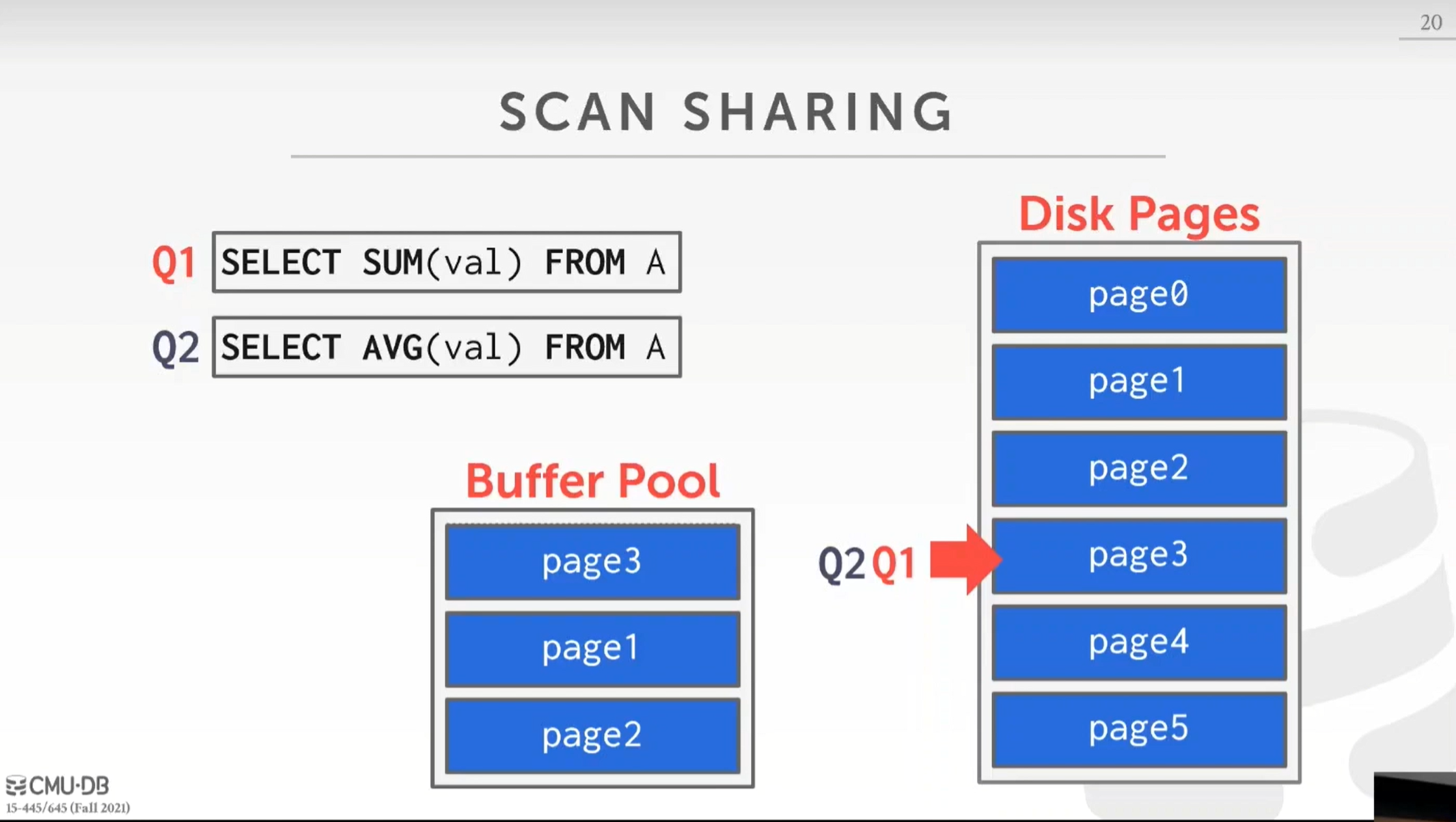
假设有两个查询:
- Q1:SELECT SUM(val) FROM A
- Q2:SELECT AVG(val) FROM A
这两个查询,都是扫描 A 表的所有页。假设 Q1 先开始执行,读取到第 3 页,这时候 Q2 开始执行,Q2 和 Q1 要扫描的页是一样的,但是 Q2 可以直接附加在 Q1 的游标上继续扫描,等 Q1 扫描完,Q2 再扫描剩下的之前没有扫描到的。
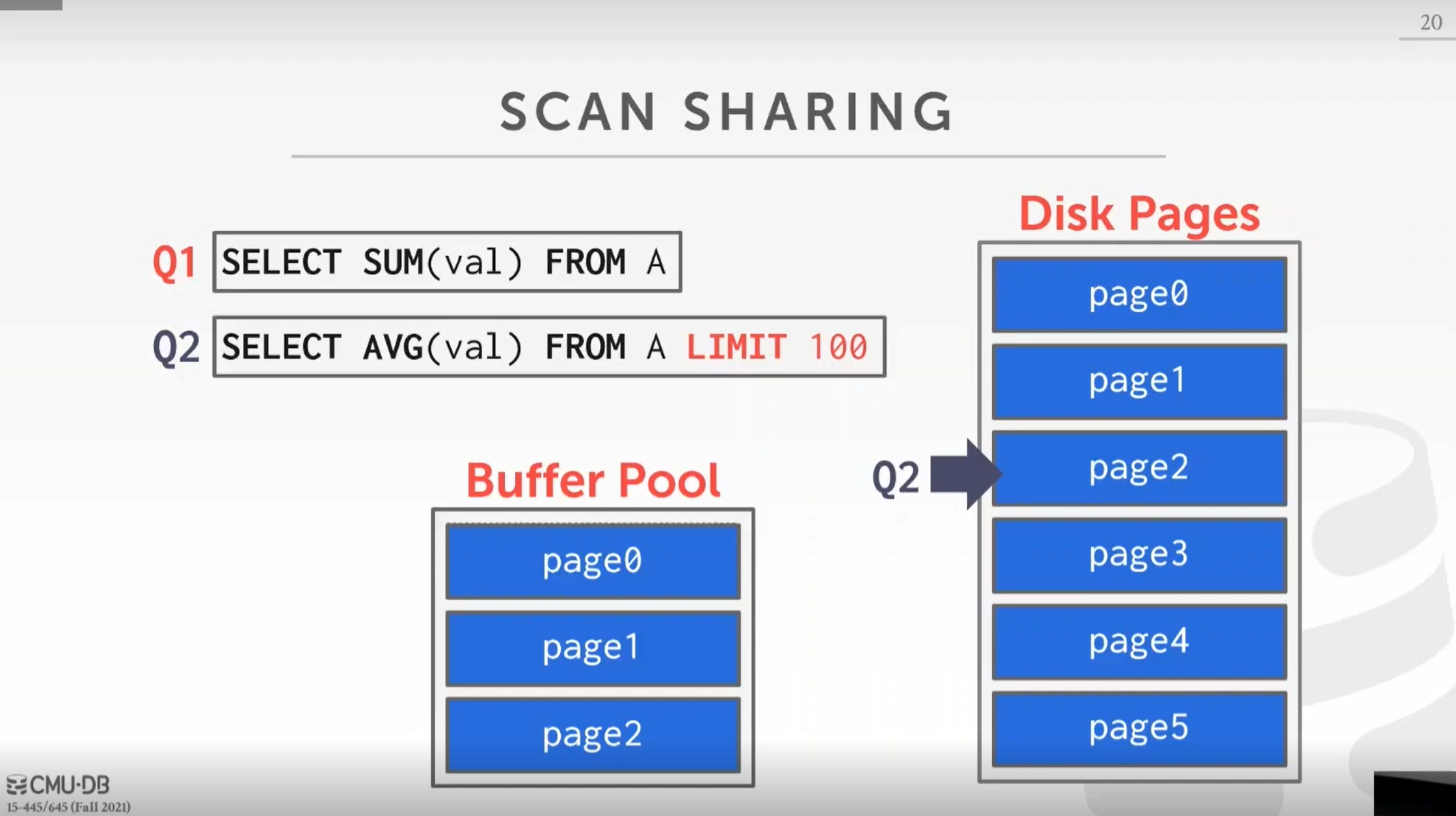
但是,如果这里 Q2 加上 limit 100,这种限制,如果配合扫描共享,那么可能每次扫描出来的结果是不一样的,因为你也不确认它到底是从头扫描还是附加到其他查询的游标上以及当前游标的位置。所以,我们最好不要有这样的查询,对于所有带 Limit 的查询,最好都指定排序条件。
最后一个优化是绕过缓冲池(buffer pool bypass)

对于顺序扫描运算符,它要扫描每一页,但是这些页仅仅一次扫描之后就立刻用不到了,如果都加载到缓冲池的话,会严重影响执行效率,并且污染缓冲池。
在 Informix 这个系统中叫做轻量扫描(Light Scans)。并且 Oracle,SQLServer,PostgresSQL 中也有这种优化机制。
下一个我们要讲的是,如果缓冲池满了,在缓冲池中替换页的不同策略,在此之前,我们先来看下操作系统中的机制:

我们要执行的大多数磁盘操作都是通过操作系统提供的 api,我们讲过mmap()或者read()和write(),对于这些 api 除非你明确指定其中的参数告诉操作系统,否则操作系统会维护自己的文件系统缓存,它通常被称为页面缓存(Page Cache)。简单来说:当你请求从磁盘读取一个页面,如果它还没有加载,就从磁盘中获取它加载到页面缓存中,然后返回一个指向你的页面的指针,之后你必须从操作系统页面缓存复制到用户空间。所以你会有一个多余的复制,一个存储在操作系统页面缓存中,一个存储在你实现的缓冲池中,所以大多数 DBMS 所做的是使用 O_DIRECT 标志来绕过操作系统的页面缓存。

我们可以采用不同的策略来确定当缓冲池填满时,我们需要腾出一个帧,以便插入一个新页。我们如何决定从缓冲池中删除哪些页呢?我们要考虑不同的方面:
- 正确性(Correctness):我们不想有任何数据被破坏的问题,例如,扔掉我们没有正确地写出的脏页。
- 准确性(Correctness):即查询结果是查询想要查的数据
- 速度(Speed):缓冲池过期需要保证查询速度,也需要考虑能快速决定哪些帧被替换,如果你花了所有的时间思考去掉哪个页最合适,那么你花在这上面的时间可能比你从智能算法中得到的好处还要
- 元数据大小(MetaData):我们需要担心的是为了进行页删除,我们存储了多少元数据,不能太多

这是最简单的一种算法,LRU(Least Recently Used,最近最少使用策略),它在很多不同的系统领域被使用。简单的实现方式是为每个页面维护一个时间戳,记录它最后一次被查询访问的时间。当 DBMS 需要删除一个页时,这很简单,我们只需要找到时间戳最早的页面,也就是最近访问最少的页面。
这是一种通用的依赖于你最近使用过的页,你最近访问过的页,很快就会再次被使用这个假设的算法。

另一个策略是时钟策略(Clock Policy),和 LRU 有点不同,这也是经常被用到的一种策略。它的实现方式通常是在每页上分配一个标记位,这个引用位可以是 0 或者 1。如果这个页面被访问到了,就会标记为 1。我们有一个时针会不断的扫描每一页,如果时钟扫描的这一页标记位为 1,那么就会更新为 0,如果本来就是 0 了,就会把这个页面过期掉。过这个算法给你带来的好处是不用维护一个完整的时间戳(每页占用4个字节或者8个字节),这个算法每页只需要一个比特标记位,所以空间的消耗会小很多。

LRU 以及时钟策略都有一些问题,它们很容易受到连续洪流(Sequential Flooding)的影响。就像前面提到的,你要做的主要假设是你最近使用过的页,你最近访问过的页,很快就会再次被使用。这对于倾斜的访问模式很好,但是如果查询执行顺序扫描,需要读取每个页,会造成只读一次然后就再也不会看的页污染缓冲池。

你可以使用一些更好的策略,例如LRU-K,它不是跟踪某件东西是否被访问,也不是跟踪某件东西最近被访问的时间戳,你要看最后 K 次引用的历史。假设 K 现在是 2,即你记录了最近当某东西被访问时的两个时间戳,然后你就可以计算出以后访问的间隔。如果这个间隔时间比较长,那么就不能经常使用,我们可以把它扔掉。如果间隔时间短得多,证明它经常被访问,我们可能会想保留它。
同时,你还可以做更高级的优化,例如:根据算法我们算出这页平均访问间隔大概是10分钟左右,你可以期望10分钟后,我需要这个页,这样你可以做一些更智能的预取。
但是,这个算法也会带来更多的元数据开销,这是我们需要权衡的。

另一种选择是使用一些本地化的策略,即以某个查询或者事务的基础决定缓冲池的过期策略,例如 Postgres 就在每个查询或事务的级别维护一个独立的唤醒缓冲池,

另一个更好的策略可能是根据不同的访问模式提供优先级提示(Priority Hints),例如,DBMS 知道访问索引和顺序扫描的访问模式的区别,因此,您可以向缓冲池提供一些提示说明哪些页面是重要的,哪些页面是我们可能不关心的。
举个例子,假设我们正在插入一些连续的 id,因为这些值是单调递增的,所以它们总是会被插入到树的右边;如果你想要执行一次扫描,你的访问路径可能会不同,但它们有一个共同点就是你总是从这个根页开始。你可以向缓冲池管理器提供的一个提示是,缓冲池保留这个根页,这两种类型的查询都需要它。

如果你的缓冲池中有一个不脏的页面,当它需要从缓冲池中剔除的时候,你可以直接删除它,覆盖它,我们不需要保留它。因为没有任何变化,它备份在磁盘上,如果我们需要我们总是可以从磁盘恢复它。但是如果是脏页的话,你需要将脏页的更新写回磁盘以保证更新的持久化。
在快速缓冲页驱除和持久写脏页之间有一种权衡。

为了减少持久化脏页的时候带来的写磁盘的 I/O 阻塞,一般会有一个后台写过程*(Background writing process)。DBMS可以定期遍历页表并将脏页写入磁盘。

除了元组和索引缓冲池之外 DBMS 还需要内存来管理其他东西,包括:
- 排序与连接缓冲
- 查询缓存
- 维护缓冲
- 日志缓冲
- 词典缓冲
这些元素有些可能有底层持久化到磁盘的元素,有些只存在于内存中,我们在后面的课程可能也会涉及到。
微信搜索“干货满满张哈希”关注公众号,加作者微信,每日一刷,轻松提升技术,斩获各种offer:
我会经常发一些很好的各种框架的官方社区的新闻视频资料并加上个人翻译字幕到如下地址(也包括上面的公众号),欢迎关注:

标签:15,缓冲,扫描,第五课,445,查询,内存,磁盘,我们 来源: https://www.cnblogs.com/zhxdick/p/16366534.html