SQL(二)DQL查询总结
作者:互联网
SQL(二)DQL查询总结
简单查询
-
查询一个字段
select 字段名 from 表名; -
查询多个字段
selsct 字段1,字段2 from 表名; -
查询所有字段
//法一(实际开发中不建议,效率低,可读性差) select * from 表名; //法二 select 字段1,字段2,...... from 表名; -
起别名as(可省略)
//查询两个字段,其中字段2显示为AAA select 字段1,字段2 as AAA from 表名; //省略as select 字段1,字段2 AAA from 表名; //别名是中文或含空格用""或''引起来,最好用'' select 字段1,字段2 'A AA' from 表名; -
查询字段可以使用数学表达式
//查询员工一年工资 select money*12 from 表名;
条件查询
语法:
select
字段1,字段2,字段3......
from
表名
where
条件;
举例:
//查询员工工资为例
select id,name from 表名 where money=800;
select id,name from 表名 where money!=800;(select id,name from 表名 where money<>800;)
select id,name from 表名 where money<=800;
//使用between and 时必须左小右大(是闭区间)
select id,name from 表名 where money>=800 and money<=1000;(select id,name from 表名 where money between 800 and 1000;)
//判空用is null,不能用=null,null不是一个值
select id,name from 表名 where money is null;(is not null)
//查询名字叫二狗工资不超过800的员工
select id,name from 表名 where name='二狗' and money=800;
//查询工资800和工资1000的员工
select id,name from 表名 where money=800 or money=1000;
select id,name from 表名 where money in(800,1000);(not in)
and和or优先级
相当于C语言里&和||优先级,写条件时可以加括号
模糊查询
like
//查询名字中含有o的人
select name from 表名 where name like '%o%';
//查询名字以T结尾的人
select name from 表名 where name like '%T';
//查询名字以K开头的人
select name from 表名 where name like 'K%';
//查询名字第三个字母是A的人
select name from 表名 where name like '__A%';
//查询名字中有_的人,需要\转义
select name from 表名 where name like '%\_%';
排序
单个字段
//查询时按员工工资排序(默认升序)
select id,name from 表名 order by money;
//查询时按员工工资排序(指定升序)
select id,name from 表名 order by money asc;
//查询时按员工工资排序(指定降序)
select id,name from 表名 order by money desc;
多个字段
//查询时按工资升序排,工资相同时按名字字典序排
select id,name from 表名 order by money asc,name asc;
//按第二列排序,了解一下
select id,name from 表名 order by 2;
综合
顺序不能变
select
id,name
from
表名
where
money between 800 and 1000
order by
money asc;
//工资在800~1000的员工按工资升序排列
select id,name from 表名 where money between 800 and 1000 order by 2;
数据处理函数
单行处理函数
-
lower()转小写,upper()转大写
select lower(name) from 表名; -
substr()截取字符串,下标从1开始不是0
//查询name从下标1开始截取1位 select substr(name,1,1) from 表名; -
concat()字符串拼接
select concat(id,name) from 表名; -
length()取字符串长度
select length(name) from 表名; -
trim()去除字符串空格
select * from 表名 where name=trim(' xpx'); -
round()四舍五入
select round(127.6598,0) from 表名;//128 select round(127.6598,1) from 表名;//127.7 select round(127.6598,2) from 表名;//127.66 select round(127.6598,-1) from 表名;//130 -
rand()随机数
select rand() from 表名; -
ifnull()空处理函数,只要有null参与的数学运算,得到的结果都是null,2+null=null
//当money为null,将null当作0处理 select name,(money+ifnull(月补助,0))*12 from 表名; -
case...when...then...when...then...else...end
//当员工是Manager工资上调10%,是Salesman工资上调50%,其他人正常 select name, job, money as oldmoney, (case job when 'Manager' then money*1.1 when 'Salesman' then money*1.5 else money end) as newmoney from 表名;
分组函数(多行处理函数)
-
count计数
//统计name不为null的总行数 select count(name) from 表名; //统计总行数 select count(*) from 表名; -
sum求和
select sum(money) from 表名; -
avg求平均
select avg(money) from 表名; -
max求最大
select max(money) from 表名; -
min求最小
select min(money) from 表名;
注意:
分组函数自动忽略null,分组函数必须在分组后使用,以上默认整张表分为一组
错误例子(分组后才能用分组函数,下面执行where时还没执行group by):
select name from 表名 where money<max(money);
分组查询
语法执行顺序:
from
where
group by
having
select
order by
-
按工作岗位job进行分组后求工资和
//在MySql中可以执行但无意义,在Oracle中报错 select name,job,sum(money) from 表名 group by job; //去掉无关字段 select job,sum(money) from 表名 group by job; -
查询每个年龄,不同岗位最高工资
//按多个字段分组 select age,job,max(money) from 表名 group by age,job; -
having筛选
//查询每个岗位最高工资,显示最高工资大于3000的 select job,max(money) from 表名 group by job having max(money)>3000;//效率低 select job,max(money) from 表名 where money>3000 group by job;//效率高 //优先选择where -
distinct去重
select distinct job from 表名; select distinct name,job from 表名;//name和job联合去重 select count(distinct job) from 表名;//统计工作岗位数量
连接查询
内连接
举例:现有两张表,表1中有员工姓名(name)和岗位编号(jobid);表2中有岗位编号(jobid)和岗位名称(jobname)
-
查询员工姓名和对应岗位名称(SQL92语法)
//一 select name,jobname from 表1,表2 where 表1.jobid=表2.jobid; //二(更好) select 表1.name,表2.jobname from 表1,表2 where 表1.jobid=表2.jobid; //三(起别名,很重要,效率) select A.name,B.jobname from 表1 A,表2 B where A.jobid=B.jobid;
内连接之等值连接:
-
查询员工姓名和对应岗位名称
//SQL92(表连接条件和筛选条件都在where里,比较杂) select A.name,B.jobname from 表1 A,表2 B where A.jobid=B.jobid; //SQL99(表连接和筛选条件分离,比较清晰) select A.name,B.jobname from 表1 A join 表2 B on A.jobid=B.jobid;//99语法更清晰(join前省略了inner) select ... from ... join ... on ... where ...
内连接之非等值连接:
-
查询员工,工资,工资等级
//表A有员工姓名name,工资money; //表B有工资等级grade,工资下限losal,工资上限hisal select A.name,A.money,B.grade from 表A A join 表B B on A.monry between B.losal and B.hisal;
内连接之自连接(一张表看成两张表):
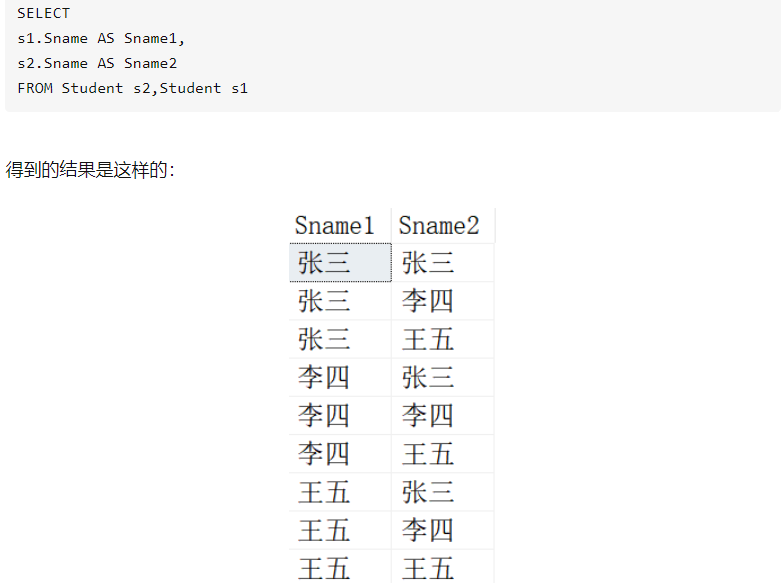

外连接
右外连接(主要查右边的表,右边的表全输出):
- 查询员工姓名,员工岗位,并且将不匹配的岗位表也全部输出
select A.name,B.jobname from 表1 A right join 表2 B on A.jobid=B.jobid;
左外连接:
同上,right换成left
全连接
同上,right换成full
多表连接
语法:
select
...
from
a
join
b
on
条件
join
c
on
条件
right join
d
on
条件;
查找员工名,薪资,工作名,薪资等级:
select
A.name,A.money,B.jobname,C.grade
from
表1 A,
join
表2 B,
on
A.id=b.id
join
表3 C
on
A.money between C.min_money and C.max_money;
子查询
语法:
//select的嵌套
select
..(select)
from
..(select)
where
..(select)
查询比最低工资高的员工名和薪资:
select name,money from 表1 where money>(select min(money) from 表1);
查询按工资分组查询平均薪资的薪资等级:
select
A.*,B.grade
from
(select job,avg(money) average from 表1 group by jobname) A
join
表2 B
on
A.average between B.min_money and B.max_money;
注意:
子查询(嵌套查询)只能返回一条数据
Union合并查询
举例:
select name from 表1 where jobname='讲师' or jobname='教授';
//上面可以换做下面
select name from 表1 where jobname='讲师'
union
select name from 表1 where jobname='教授';
//union是相加,比笛卡尔积效率高
注意:
进行union时,两条查询的列数及数据类型应相同,只是列数相同也不行(mysql中不报错,oracle语法较为严格会报错)
limit
通常用在分页查询
按薪资降序排序,取出前五条记录:
select name,money from 表 order by money desc limit 5;
取出薪资排名3到5的员工:
select name,money from 表 order by money desc limit 2,3;
注意:
mysql中limit在order by后执行
limit 5:取前5
limit 0,5:从0开始取5条记录
limit分页查询
分页显示3条记录:
第一页:limit 0,3 [0,1,2]
第二页:limit 3,3 [3,4,5]
第三页:limit 6,3 [6,7,8]
第四页:limit 9,3 [9,10,11]
观察发现(页码-1)*3是起始下标
DQL总结
书写顺序:
select
from
where
group by
having
order by
limit
执行顺序:
from
where
group by
having
select
order by
limit
标签:name,money,SQL,查询,表名,DQL,where,select 来源: https://www.cnblogs.com/LoginX/p/Login_X39.html