PostgreSQL 逻辑复制数据不一致,导致主库wal log 无限增大
作者:互联网
PostgreSQL的逻辑复制对比物理复制的好处总结有以下几点
1 灵活: 逻辑复制对比物理复制来说,可以单表进行数据的复制,物理复制则是不可以的,并且大部分时间对于ETL的功能需求来说,物理复制太重了,需要的磁盘,网络,等资源都相对于逻辑复制消耗的要大的多.
2 方便:逻辑复制相对于物理复制,设置会更简单,可以随时终止或者创建,数据进行同步等等.
3 定制化:逻辑复制可以设置复制的操作,例如只需要进行insert 的复制,或者 update, delete 等操作的复制,可以做到, 数据不和primary端一致,而达到某些目的.
4 数据迁移,PG如果版本不同进行升级的情况下,PG的logical replication 是可以作为一种数据迁移的方案,在不同的版本中进行数据的同步使用的. 逻辑复制还是使用物理复制架构实现,从上图可见, 在复制槽的基础上添加了pgoutput plugin 将原有的wal 日志转换后发送, subscription 在接受这些信息,将信息填充到目的地. 为了避免数据被重复的在subscription 上重复操作,通过客户端记录接受的LSN号码,避免重复接受同样的数据,并操作.
逻辑复制还是使用物理复制架构实现,从上图可见, 在复制槽的基础上添加了pgoutput plugin 将原有的wal 日志转换后发送, subscription 在接受这些信息,将信息填充到目的地. 为了避免数据被重复的在subscription 上重复操作,通过客户端记录接受的LSN号码,避免重复接受同样的数据,并操作.
另外需要提示的是,很多不能进行vacuum的案例中,部分都有复制槽的出现,可能这个复制槽一主多用,同时有数据接收端,其中如果有数据接收端无法接受数据,则与相关的需要保留的tuples 就不会被清理,造成 vacuum 无法回收.
下面我们有一个复制槽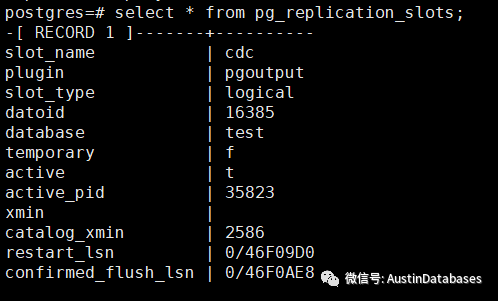
然后我们人为的制造一个冲突. 在数据复制的从库,将数据表的人为添加了一条数据. 在subscription 端查看subscription 的信息
在subscription 端查看subscription 的信息
然后我们在publication 端也插入数据
直接进入到subscription 中查看错误日志 系统一直在报错的状态中, 由于主库和从库之间的数据操作冲突,导致从主库到从库的数据无法被操作. 那到底是怎么影响了WAL log
系统一直在报错的状态中, 由于主库和从库之间的数据操作冲突,导致从主库到从库的数据无法被操作. 那到底是怎么影响了WAL log
我们继续往下看
在主库我们将2000条数据删除1900条 在subscription 中我们查看当前的数据,结果一定是和主库已经脱离,不会在继续进行任何操作,主要的原因也是 逻辑复制是有顺序的,如果任何一个操作被卡主,则后续的操作都不会被完成.
在subscription 中我们查看当前的数据,结果一定是和主库已经脱离,不会在继续进行任何操作,主要的原因也是 逻辑复制是有顺序的,如果任何一个操作被卡主,则后续的操作都不会被完成.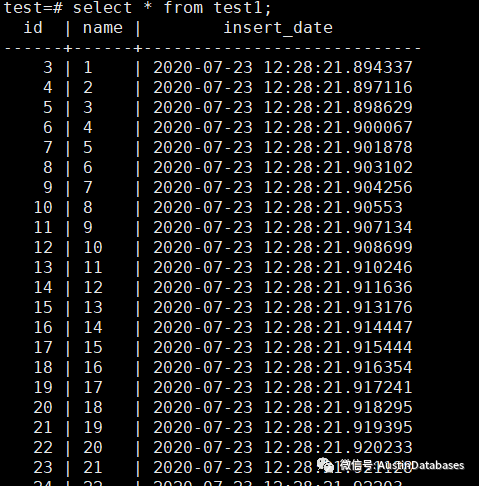
那么后续主库的 latest checkpoint location 的进度将停止,无论你卖手机号码地图做任何的操作,或者使用checkpoint 命令 也不会影响
这里如果PG_WAL 无法进行checkpoint 则表明PG的WAL LOG 无法归档,随着主库的操作越来越多,则WA了的文件也会越来越大,无法进行清理.
下面我们在从库中将自行添加的记录删除后,在看主库的checkpoint location
已经变化了. 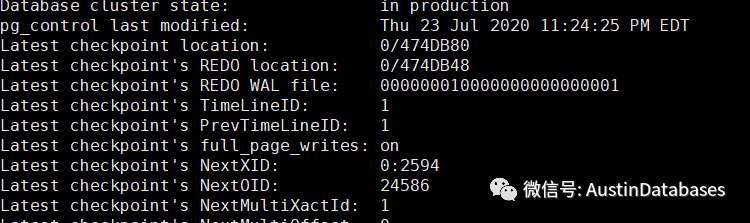
当然如何监控replication logical 复制是否中断的问题select pid, client_addr, state, sync_state, pg_wal_lsn_diff(sent_lsn, write_lsn) as write_lag, pg_wal_lsn_diff(sent_lsn, flush_lsn) as flush_lag, pg_wal_lsn_diff(sent_lsn, replay_lsn) as replay_lagfrom pg_stat_replication;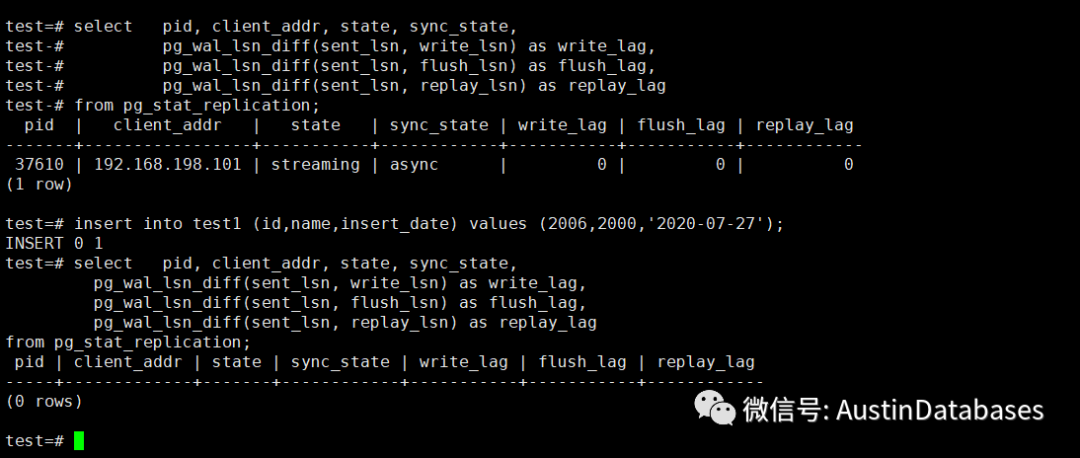
如果你当前有一个replication 的情况下, 查询主库,如果复制正常,则会查出你与subscription之间的情况, 如果数据不一致,造成复制停止的情况,则再次查询就不会有数据显示了. 所以这也是一个判断逻辑复制是否正常的一个方式方法.
逻辑复制停止会造成主库的wal 无法截断的问题,所以如果PG 已经使用了逻辑复制,则必须对逻辑复制进行监控,否则在繁忙的业务系统中,逻辑复制的停止,会让你的主库的wal 空间出现问题,最终导致主库磁盘空间耗尽的问题.
标签:主库,逻辑,wal,PostgreSQL,lsn,复制,数据 来源: https://www.cnblogs.com/ludongguoa/p/15334277.html