MySQL内存管理机制
作者:互联网
參考鏈接
https://www.cnblogs.com/jmliao/p/13415292.html
MySQL内存管理机制
目录
Top
1. BufferPool
- What is BufferPool?
MySQL InnoDB Buffer Pool,MySQL InnoDB 缓冲池。里面缓存着大量数据(数据页),使 CPU 读取或写入数据时,不直接和低速的磁盘打交道,直接和缓冲区进行交互,从而解决了因为磁盘性能慢导致的数据库性能差的问题。
- Why need BufferPool?
buffer pool 最主要的功能便是加速读和加速写。
加速读就是当需要访问一个数据页的时候,如果这个页已经在缓存池中,那么就不再需要访问磁盘,直接从缓冲池中就能获取这个页面的内容。
加速写就是当需要修改一个数据页的时候,先将这个页在缓冲池中进行修改,记下相关的 redo log,这个页的修改就算已经完成了。至于这个被修改的页什么时候真正刷新到磁盘,这个是 buffer pool 后台刷新线程来完成的。
- How implemented?
所有从磁盘加载进内存的数据页,都会通过这个buffer pool管理起来。对应在代码的中的结构体为buf_pool_t。在MySQL中通常会有多个buffer pool instance,这是为了减少多线程并发访问时,buffer pool锁等待的开销。
BufferPool由buf_pool, buf_chunk, buf_block和buf_page组成,结构如下:
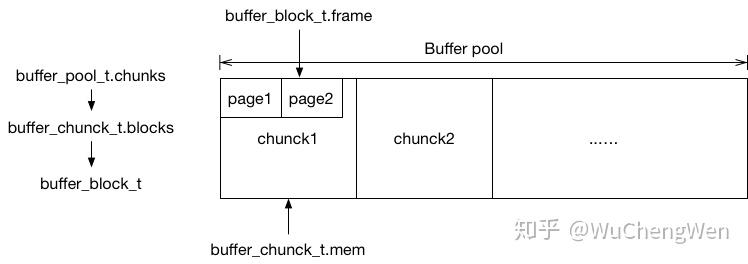
- Code?
struct buf_pool_t {
buf_chunk_t *chunks; /*!< buffer pool chunks */
hash_table_t *page_hash; /*!< hash table of buf_page_t or
buf_block_t file pages,
buf_page_in_file() == TRUE,
indexed by (space_id, offset).
page_hash is protected by an
array of mutexes. */
UT_LIST_BASE_NODE_T(buf_page_t) flush_list;
/*!< base node of the modified block
list */
UT_LIST_BASE_NODE_T(buf_page_t) free;
/*!< base node of the free
block list */
UT_LIST_BASE_NODE_T(buf_page_t) LRU;
/*!< base node of the LRU list */
/* ... */
}
struct buf_chunk_t {
ulint size; /*!< size of frames[] and blocks[] */
unsigned char *mem; /*!< pointer to the memory area which
was allocated for the frames */
buf_block_t *blocks; /*!< array of buffer control blocks */
/* ... */
}
struct buf_block_t {
buf_page_t page; /*!< page information; this must
be the first field, so that
buf_pool->page_hash can point
to buf_page_t or buf_block_t */
byte *frame; /*!< pointer to buffer frame which
is of size UNIV_PAGE_SIZE, and
aligned to an address divisible by
UNIV_PAGE_SIZE */
/* ... */
}
class buf_page_t {
public:
/** @name General fields
None of these bit-fields must be modified without holding
buf_page_get_mutex() [buf_block_t::mutex or
buf_pool->zip_mutex], since they can be stored in the same
machine word. */
/* @{ */
/** Page id. */
page_id_t id;
/** Page size. */
page_size_t size;
/** Count of how manyfold this block is currently bufferfixed. */
uint32_t buf_fix_count;
/** type of pending I/O operation. */
buf_io_fix io_fix;
/** Block state. @see buf_page_in_file */
buf_page_state state;
/* ... */
}
2. 页面管理机制
InnoDB 基于 LRU 算法管理 buffer pool 中的数据页。一般情况下 list 头部存放的是热数据,就是所谓的 young page(最近经常访问的数据),list 尾部存放的就是 old page(最近不被访问的数据)。
LRU List:缓存了所有读入内存的数据页。包含三类:
- 未修改的页面,可以从该链表中摘除,然后移到 Free List 中;
- 已修改还未刷新到磁盘的页面;
- 已修改且已经刷新到磁盘的页面,可并为第一类。
Free List:空闲内存页列表,需要装载(缓存)磁盘上数据页的时候,从此列表取内存块。
Flush List:在内存中被修改但还没有刷新到磁盘的数据页(脏页)链表,内存中的数据跟对应磁盘上的数据不一致,属于该链表的页同样存在于 LRU List 中,但反之未必。

- How read a page?
当访问的页面在缓存池中命中,则直接从缓冲池中访问该页面。如果没有命中,则需要将这个 page 从磁盘上加载到缓存池,因此需要在缓存池中的 Free List 中找一个空闲的内存页来缓存这个从磁盘读入的 page。
但存在空闲内存页被使用完的情况,不保证一定有空闲的内存页。假如 Free List 为空,则需要想办法产生空闲的内存页。 首先是在 LRU List 中找可以替换的内存页,查找方向是从列表的尾部开始找,如果找到可以替换的 page,将其从 LRU List 中摘除,加入 Free List,然后再去 Free List 中找空闲的内存页。第一次查找最多只扫描 100 个 page,循环进行到第二次时,查找深度就是整个 LRU List。这就是 LRU List 的页面淘汰机制。
如果在 LRU List 中没有找到可以替换的页,则进行单页刷新,将脏页刷新到磁盘后,再将释放的内存页加入到 Free List,最后再去 Free List 取。为什么只做单页刷新呢?因为它的目的是获取空闲内存页,进行脏页刷新是不得已而为之,所以只会进行一个页的刷新,目的是为了尽快的获取空闲内存页。
因为 Free List 是一个公共的链表,所有的用户线程都可以使用,存在争用的情况。因此,自己产生的空闲内存页有可能会刚好被其它线程所使用,因此用户线程可能会重复执行上面的查找流程,直到找到空闲的内存页为止。
通过数据页访问机制,可以知道当无空闲页时产生空闲页就成为了一个必须要做的事情。
如果需要通过刷新脏页来产生空闲页或者需要扫描整个 LRU List 来产生空闲页,查找空闲页的时间就会延长,这是一个 bad case。
因此,innodb buffer pool 中存在大量可以替换的页,或者 Free List 中一直存在着空闲内存页,对快速获取空闲内存页就起到了决定性的作用。
而在 innodb buffer pool 的机制中,是采用何种方式来产生空闲内存页以及可以替换的内存页呢?这就是下面要讲的内容——脏页刷新策略。
- How to flush a dirty page?
MySQL线程后台会有flush线程,定期地将flush list的脏页flush到磁盘上,这样可以减轻check point的开销,和页面替换时,那些被替换页面的flush开销,而使得读取页面时间增长。flush list的页面根据修改的时间从新到老进行排序,也即是最新的修改,在flush list的头部,最老的修改在flush list的尾部。当flush时,从尾部取page flush到磁盘上。这样的逻辑是跟checkpoint保持一致,checkpoint的流程也是从老到新一步步持久化page,所以可以加快checkpoint。
- When to flush dirty page?
- 后台线程定期刷;
- redo log 写满了(强制刷);
- 内存不足(强制刷)。
标签:pool,List,管理机制,内存,MySQL,buf,page,空闲 来源: https://www.cnblogs.com/liuxiuxiu/p/14963280.html