414天前,我以为这是编程玄学...
作者:互联网
你好呀,我是why。
不知道大家还有没有印象,我曾经写了这样的一篇文章:《一个困扰我122天的技术问题,我好像知道答案了。》
文章我给出了这样的一个示例:
public class VolatileExample {
private static boolean flag = false;
private static int i = 0;
public static void main(String[] args) {
new Thread(() -> {
try {
TimeUnit.MILLISECONDS.sleep(100);
flag = true;
System.out.println("flag 被修改成 true");
} catch (InterruptedException e) {
e.printStackTrace();
}
}).start();
while (!flag) {
i++;
}
System.out.println("程序结束,i=" + i);
}
}
上面这个程序是不会正常结束的,因为变量 flag 没有被 volatile 修饰。
而在子线程休眠的 100ms 中, while 循环的 flag 一直为 false,循环到一定次数后,触发了 jvm 的即时编译功能(JIT),进行循环表达式外提(Loop Expression Hoisting),导致形成死循环。
而如果加了 volatile 去修饰 flag 变量,保证了 flag 的可见性,则不会进行提升。
验证方案就是关闭 JIT 功能,对应的命令是 -Xint 或者 -Djava.compiler=NONE。
这都不是重点,重点是我接下来有几处小改动,代码的运行结果也是各不相同。
文章中的最后一节我是这样说的:

而图片里面提到的“关于Integer”的问题,就是文章说提到的“玄学”:

是的,我回来填坑了。
再次探索
其实让我再次探索这个问题的起因是因为四月份的时候有人私信我,问我关于 Integer 的玄学问题是否有了结论。
我只能说:
但是,后来我想到了这篇文章里面的一个留言:

由于当时公众号没有留言功能,用的第三方小程序,所以我没有太注意到留言提醒。
这位大佬留言之后,我隔了很长时间才看到,我还在留言后面回复了一个:
谢谢大佬分析,有时间的时候我按照这个思路去分析分析。
但是后来我也搁置了,因为我感觉好像继续在这里面深究下去收益已经不大了。
没想到,时隔这么长时间,又有读者来问了。
于是在五一期间我按照留言的说法,修改了一下程序,并进行了一波基于搜索引擎的研究。
嘿,你猜怎么着?
我还真的研究出了一点有意思的东西。
先说结论:final 关键字影响了程序的结果。
在上面这个案例中,final 关键字在哪呢?
当我们把程序里面的 int 修改为 Integer 后,i++ 操作涉及到装箱、拆箱的操作,这个过程中对应的源码是这里:
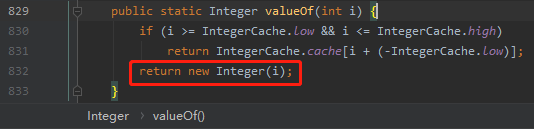
而这里的 new Interger(i) 里面的 value 是 final,
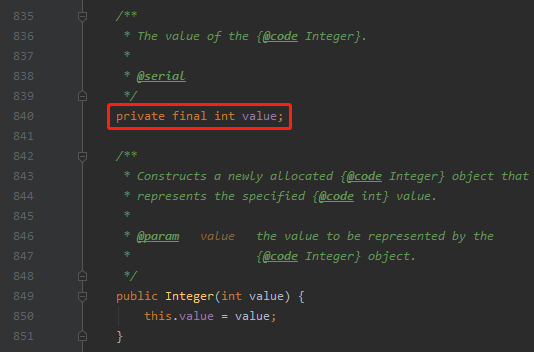
程序能正常结束,确实是 final 关键字影响了程序的结果。
那么final 到底是怎么影响的呢?
这个地方我经过探索之后,发现和留言中说的有一定的偏差。
留言中说的是因为有 storestore 屏障加上 Happens-Before 关系得出 flag 会被刷到主内存中。
而我基于搜索引擎的帮助,探索出来的结论是加上 final 和不加 final,生成的是两套机器码,导致运行结果不一致。
但是我这里得加上一个前提:处理器是 x86 架构。
得出这个结论基于的测试案例如下,也是按照留言给的思路写出来的:
Class 里面包含一个 final 的属性,在构造方法里面给属性赋值。然后在 while 循环里面不断 new 该对象:
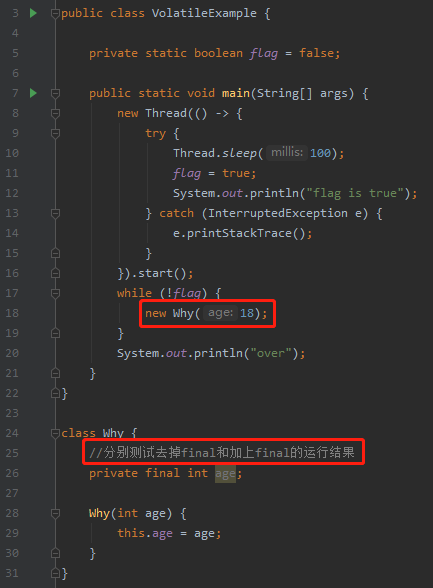
我的运行环境是:
jdk1.8.0_271 win10 IntelliJ IDEA 2019.3.4
运行结果是:
如果 age 属性加上 final 修饰,程序则可以正常退出。 如果 age 属性去掉 final 修饰,程序则无限循环,不能退出。
动图如下:
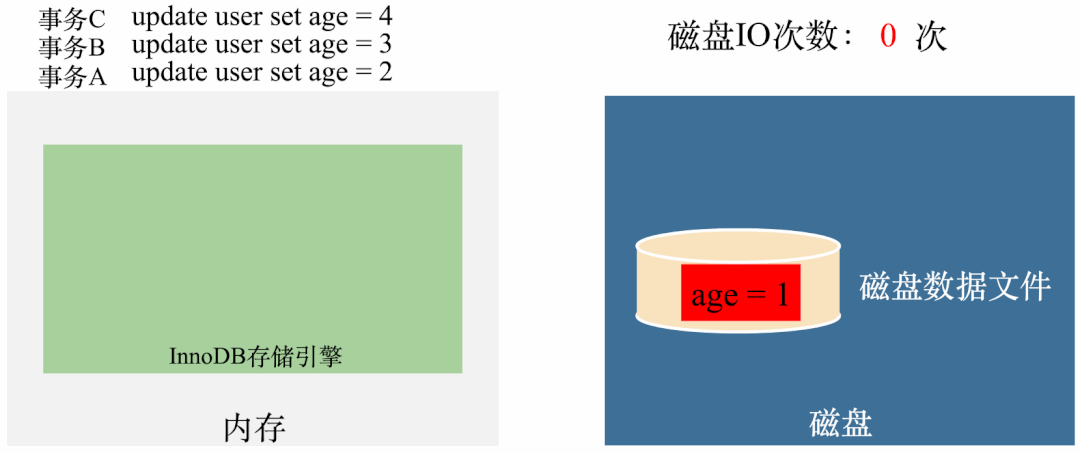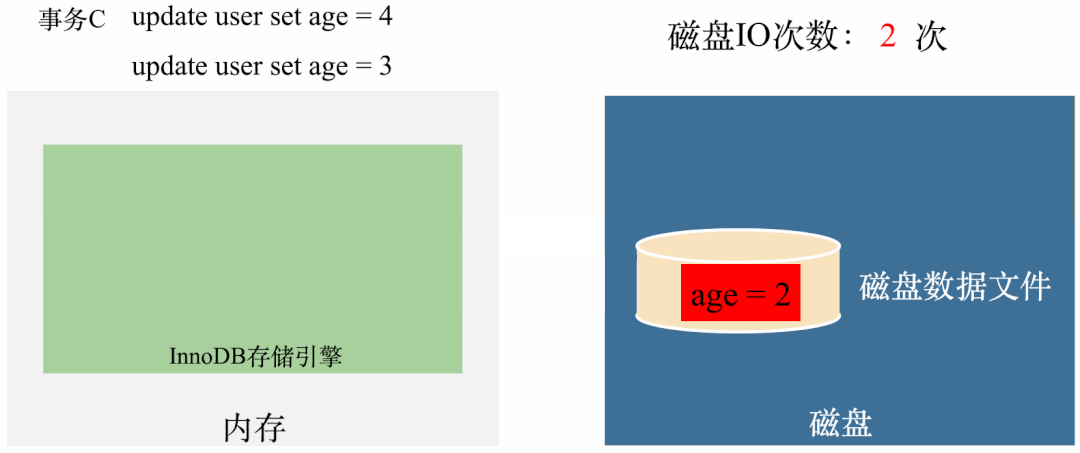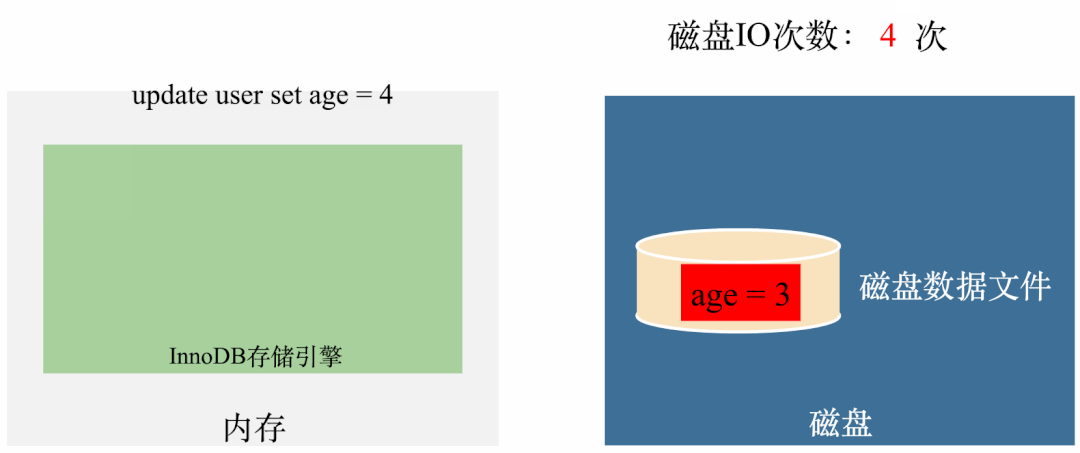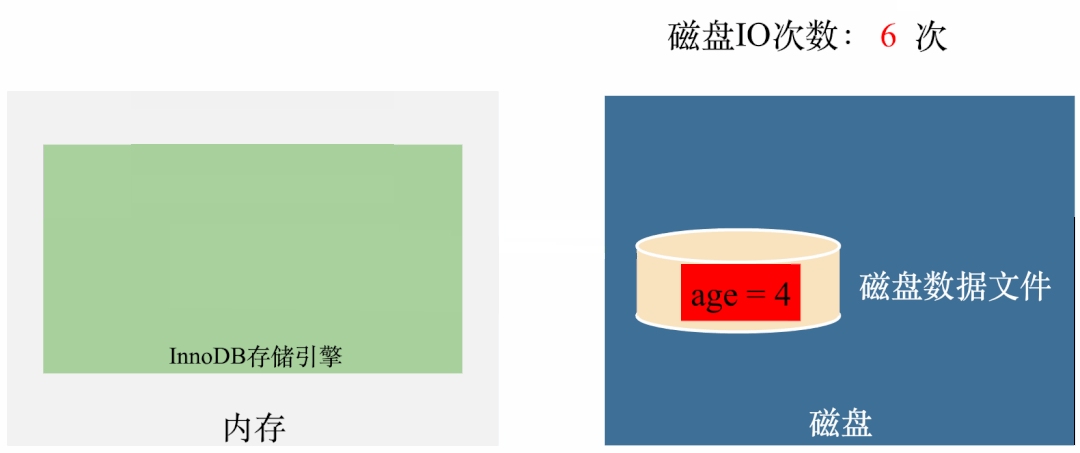
你也可以把我上面给的代码粘出来,跑一跑,看看是否和我说的运行结果一致。
说说 final
当我把程序改造成上面这个样子之后,其实结论已经很明显了,final 关键字影响了程序的运行。
其实当时我得出这个结论的时候非常兴奋,一个困扰我长达一年多的问题终于要被我亲手解开神秘面纱了。
结论都有了,寻找推理过程还不是轻而易举的事情?
而且我知道去哪里找答案,答案就藏在我桌子上的一本书里面。
于是我翻开了《Java并发编程的艺术》,其中有一小节专门讲到了 final 域的内存语义:
.png)
这一小节我印象可是太深刻了,因为 3.6.5 小节的“溢出”应该是“逸出”才对,早年间还基于此,写了这篇文章:
所以我只要在这一个小节里面找到证据,来证明留言里面的“storestore 屏障加上 Happens-Before 关系得出 flag 会被刷到主内存中”这个论点就行了。
但是,事情远远没有我想的这么简单,因为我发现,我在书里面没有找到能证明论点的证据,反而找到了推翻论点的证据。
书里面的一大段内容我就不搬运过来了,仅仅关注 3.6.6 final语义在处理器中的实现这一小节的内容:

注意画了下划线这一句话:在 X86 处理器中,final 域的读/写不会插入任何内存屏障。
由于没有任何内存屏障的存在,即“storestore 屏障”也是省略掉了。因此在 X86 处理器的前提下,final 域的内存语义带来的 flag 刷新是不存在的。
所以前面的论点是不正确的。
那么这本书里面的“在 X86 处理器中,final 域的读/写不会插入任何内存屏障”这个结论又是从哪里来的呢?
这个说来就巧了,是我们的老朋友 Doug Lee 告诉作者的。
你看 3.6.7 小节提到了 JSR-133。而关于 JSR-133,老爷子写过这样的一篇文章:《The JSR-133 Cookbook for Compiler Writers》,直译过来就是《编译器编写者的JSR-133食谱》
http://gee.cs.oswego.edu/dl/jmm/cookbook.html
在这篇食谱里面,有这样的一个表格:
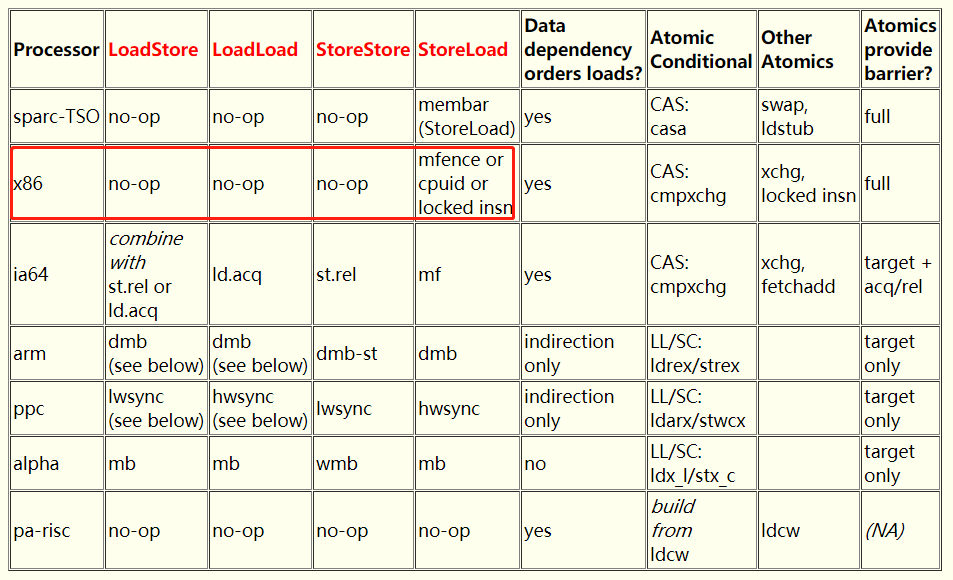
可以看到,在 x86 处理器中,LoadStore、LoadLoad、StoreStore 都是 no-op,即无任何操作。
On x86, any lock-prefixed instruction can be used as a StoreLoad barrier. (The form used in linux kernels is the no-op lock; addl $0,0(%%esp).) Versions supporting the "SSE2" extensions (Pentium4 and later) support the mfence instruction which seems preferable unless a lock-prefixed instruction like CAS is needed anyway. The cpuid instruction also works but is slower.
翻译过来就是:在 x86 上,任何带 lock 前缀的指令都可以用作一个 StoreLoad 屏障。 (在 Linux 内核中使用的形式是 no-op lock; addl $0,0(%%esp)。) 支持 "SSE2" 扩展的版本(Pentium4 和更高版本)支持 mfence 指令, 该指令似乎是更好的,除非无论如何都需要像 CAS 这样的带 lock 前缀的指令。cpuid 指令也可以,但是速度较慢。
查到这里的时候我都快懵逼了,好不容易整理出来的一点点思路就这样再次被堵死了。
我给你捋一下啊。
我们是不是已经可以非常明确 final 带来的屏障(StoreStore)在 X86 处理器中是空操作,并不能对内存可见性产生任何影响。
那么为什么程序加上 final 之后,停下来了?
程序停下来了,说明主线程一定是观测到了 flag 的变化了?
那么为什么程序去掉 final 后,停不下来了?
程序没有停了,说明主线程一定沒有观测到 flag 的变化?
也就是说停不停下来,和有没有 final 有直接的关系。
但是 final 域带来的屏障在 X86 处理器中是空操作。
这特么是玄学吧?
绕了一圈,怎么又回去了啊。
这波,说真的,激怒我了,我花了这么多时间,绕了一圈又回来了?
干它。
stackoverflow
经过前面的分析,留言中提到的结论是验证不下去了。
但是我已经可以非常明确的知道,肯定是 final 关键字在作怪。
于是,我准备去 stackoverflow 上找一圈,看看会不会有意外发现。
果然,皇天不负有心人,我大概翻了几百个帖子,就在准备放弃的边缘,我翻到了一个让我虎躯一震的帖子。
虎躯一震之后,又是倒吸一口凉气:我的个娘,这是 JVM 的一个 BUG!?
这事先按下不表,我先说说我是怎么在 stackoverflow 里面搜索问题的。
首先,当前的这个情况下,我能确定的关键字就是 Java,final 这两个。
但是我拿着这两个关键字去查的时候,查询出来的结果太多了,翻了几个之后我就发现这无疑是大海捞针。
于是我改变了策略,stackoverflow 上搜索是有 tag 即标签功能的:
如果让我把这个问题划分一个标签,标签无非就是 Java,JVM,JMM,JIT。
于是,我在 java-memory-model 即 JMM 下挖到了一个宝藏:
就是这个宝藏问题,推动了接下来的剧情发展:
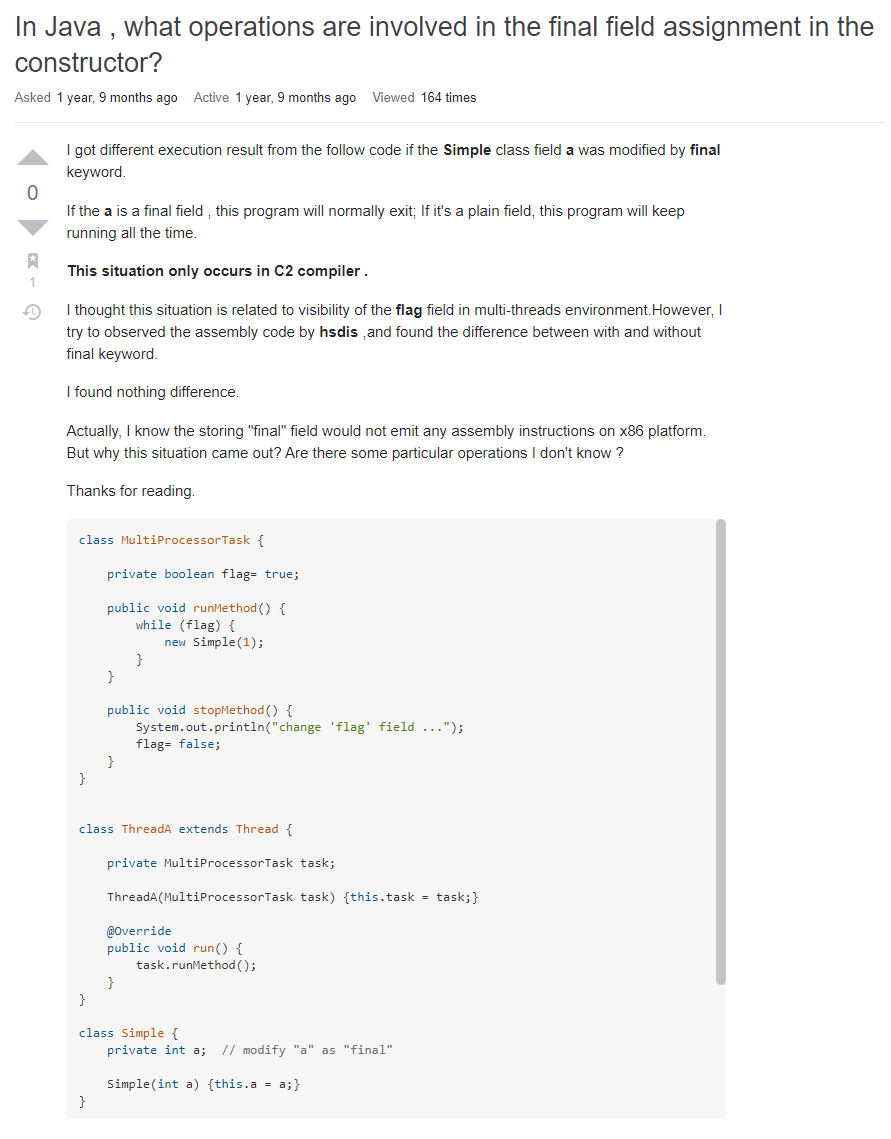
https://stackoverflow.com/questions/57427531/in-java-what-operations-are-involved-in-the-final-field-assignment-in-the-cons
我知道你看到这里的时候内心毫无波澜,听到我虎躯一震,甚至还想笑。
但是我看到这个问题的时候,不夸张的说:手都在抖。
因为我知道,在这里,就能解决这个玄学问题了。
而我倒吸一口凉气的原因是:这个问题里面的示例代码竟然和我的代码如出一辙,他代码里面的 Simple 就是对应着我代码里面的 Why。想要验证的问题,那就更是一模一样了。
问题里面的描述是这样说的:
Actually, I know the storing "final" field would not emit any assembly instructions on x86 platform. But why this situation came out? Are there some particular operations I don't know ?
实际上,我知道“final”字段不会在 x86 处理器上发出任何汇编指令。但为什么会出现这种情况?有什么特别的操作我不知道吗?
真相
上面提到的 stackoverflow 问题下面有这样的一个回答,这里面就是玄学背后的科学:

我翻译一下给你看:
老哥,我看到你问题里面的截图了,你查问题的姿势没对。
截图是什么呢?
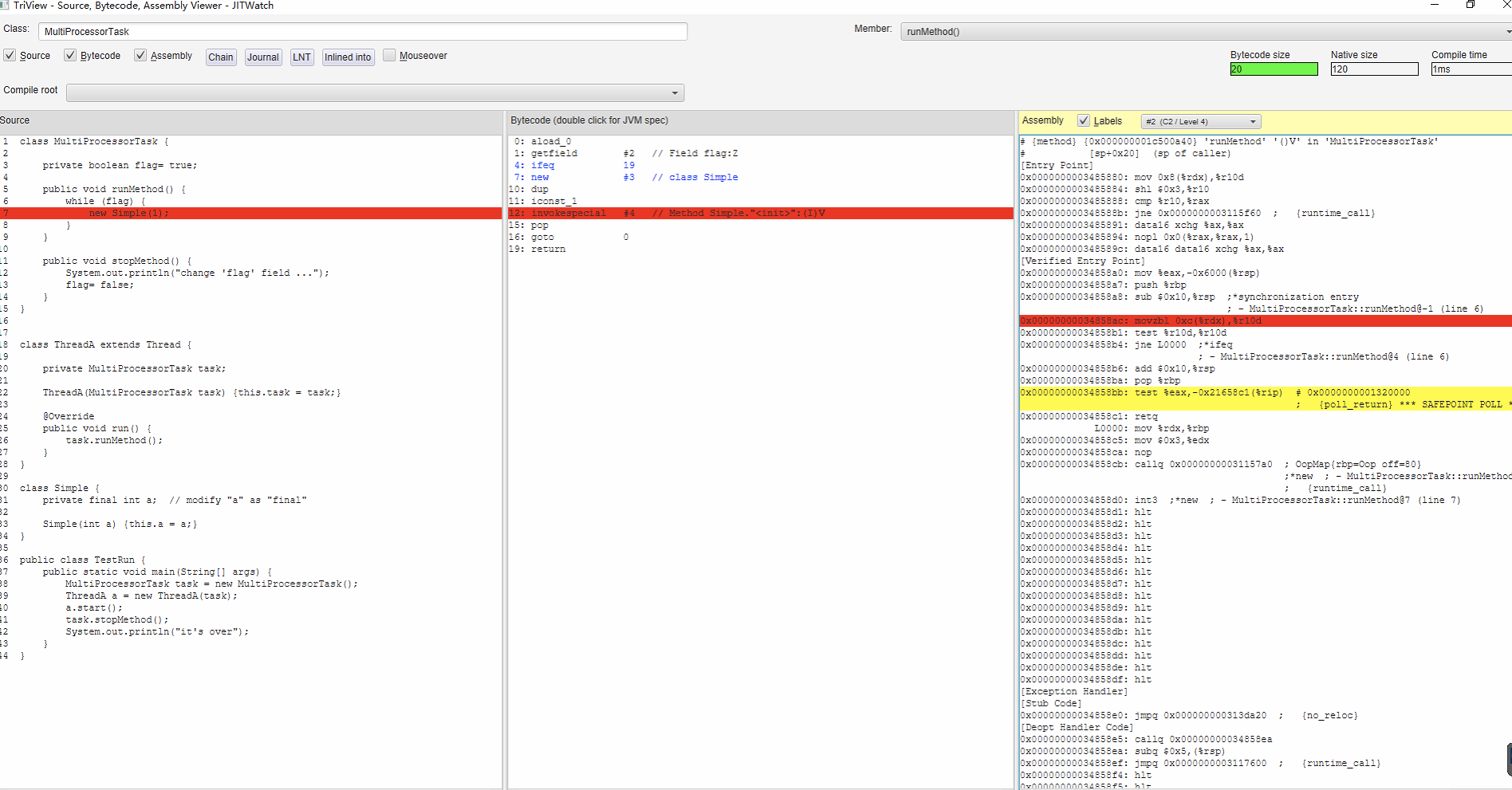
就是提问者附在问题里面的两个截图:

其中 final case 的截图是这样的:
non-final case 的截图是这样的:
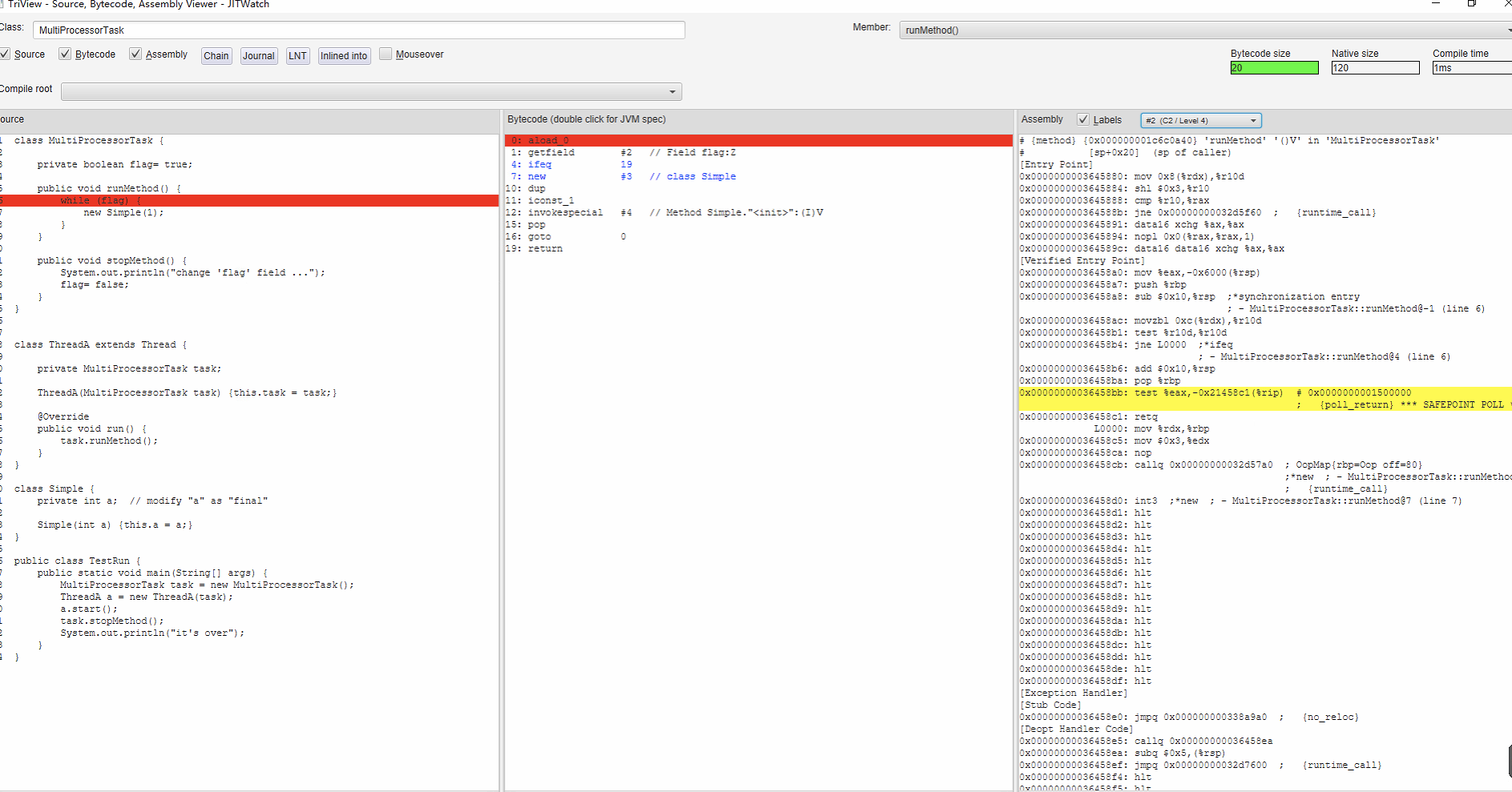
顺道说一句题外话,截图来源就是 JITWatch 工具,一个很强大的工具。
从你的截图来看,虽然 runMethod 都被编译过了,但是并没有被真正的执行过。你需要注意的是汇编输出中有 % 标记的地方,它代表着 OSR(on-stack replacement)栈上替换。
如果你不清楚啥是 OSR 也先别着急,一会说。
对于加和不加 final,最终得出的汇编代码是不一样的,我编译之后,仅保留相关部分如下:
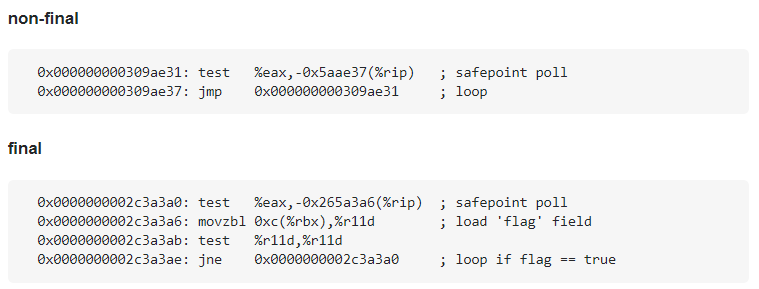
从截图中可以看出,没有加 final 的时候,汇编代码其实就是一个死循环。而加上 final 之后,每次都会去加载 flag 字段。
但是你看,这两种情况,都没有对 Simple 类进行实例分配,也没有字段的分配。
所以,这不是编译器 final 字段赋值的问题,而是编译器的一种优化手段。
整个过程中完全没有 Simple 类的事儿,也就更加没有 final 字段的事儿了。但是加上 final 之后确实影响了程序的结果。
这个问题在比较新的 JVM 版本中得到了修复(言外之意就是一个 BUG?)。
所以,如果你在 JDK 11 版本上运行相同的代码,无论加不加 final,程序都不会正常退出。
好了,上面说了这么多,其实原因已经很清楚了。
根本原因是因为加不加 final 在我的示例环境中生成的是两套不同的机器码。
深层次的原因是 OSR 机制导致的。
验证
经过前面的分析,现在新的排查方向又出来了。
我现在得去验证一下回答问题这个哥们是不是在胡说。
于是我先去验证了他的这句话:
If you run the same example on JDK 11, there will be an infinite loop in both cases, regardless of the final modifier.
用高版本的 JDK 分别运行加了 final 和不加 final 修饰符的情况。
程序确实是都陷入了死循环。
动图如下,可以看到我的 JDK 版本是 15.0.1:
第一个点验证完成。同样的代码,JDK8 和 JDK15 运行起来结果不一致(其实JDK9运行就不一致了)。
我有理由相信,也许这是 JVM 的一个,不能说 BUG,应该说是缺陷吧。(等等...缺陷不就是 BUG 吗?)
第二个验证的点是他的这句话:
Instead, execution jumps from the interpreter to the OSR stub.
用 JDK8 跑出来结果不一样是因为有栈上替换在捣鬼,那么我可以用下面这个命令,把栈上替换给关闭了:
-XX:-UseOnStackReplacement
去掉 final 后,再次运行程序,程序停止了。
第二个点验证完成。
第三个验证的点是他的这个地方:

我也把我的汇编搞出来看看,有没有类似这样的地方。
怎么搞汇编出来呢?
用下面这个命令:
-XX:+UnlockDiagnosticVMOptions -XX:+PrintAssembly -XX:+LogCompilation -XX:LogFile=jit.log
同时你还需要一个 hsdis 的 dll 文件,网上有很多,一搜就能找到,我相信如果你也想亲自验证,那么找这个文件难不倒你。
没有加 final 字段的时候,汇编是这样的:
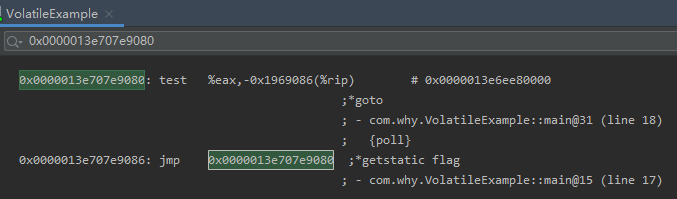
jmp 指令是干啥的?
无条件跳转。
所以,这里就是个死循环。
加上 final 字段后,汇编是这样的:
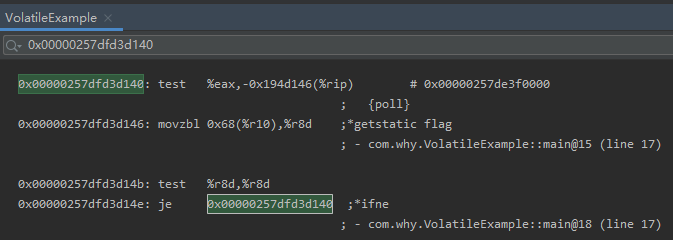
首先跳转用的是 je 了,而不是 jmp 了。
je 的跳转是有条件的,代表的是“等于则跳转”。
而在 je 指令之前,还有 movzbl 指令,该操作就是在读取 flag 变量的值。
所以,加了 final 语句之后,每次都会去读取 flag 变量的值,因此 flag 值的变化能及时被主线程看到。
同时我也有 JITWatch 看了一下,对于循环中的 new Why(18) 语句,编译器分析出来这句话并没有什么卵用,于是被优化掉了:
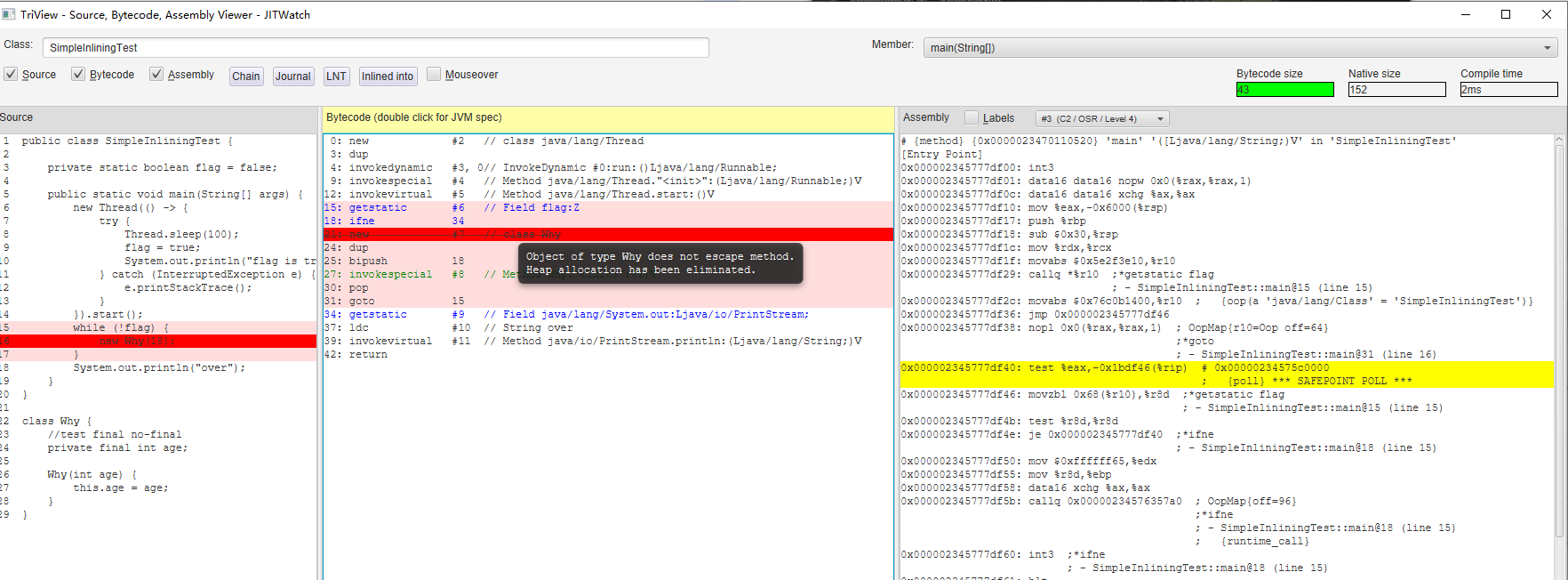
所以我们在汇编中没有看到对 Why 对象进行分配的相关指令,也就是验证了他的这句话:
You see, in both cases there is no Simple instance allocation at all, and no field assignment either.
自此,玄学问题得到了科学的解释。
如果你坚持看到了这里,那么恭喜你,又学到了一个没啥卵用的知识点。
如果你想要学点和本文相关的、有用的东西,那么我建议看看这几个地方:
《Java并发编程的艺术》的3.6小节-final域的内存语义。 《深入理解Java虚拟机》的第四部分-程序编译与代码优化。 《深入解析Java虚拟机HotSpot》的第7章-编译概述,第8章-C1编译器,第9章-C2编译器。 《Java性能优化实践》的第10章-理解即时编译
看完上面这些之后,你至少会比较清楚的了解到 Java 程序从源码编译成字节码,再从字节码编译成本地机器码的这两个过程。
能够了解 JVM 的热点代码探测方案、HotSpot 的即时编译、编译触发条件,以及如何从 JVM 外部观察和分析即使编译的数据和结果。
还有会了解到一些编译器的优化技术,比如:方法内联、分层编译、栈上替换、分支预测、逃逸分析、锁消除、锁膨胀...等等,这些基本上用不上,但是你知道了又显得高大上的知识点。
另外,强推R大的这个专栏:
https://www.zhihu.com/column/hllvm
专栏里面的这篇文章,宝藏:
https://zhuanlan.zhihu.com/p/25042028

比如本文涉及到的栈上替换(OSR),R大就回答过:

直言,OSR 对于跑分很有用,对于正常程序来说,用不上:

其中提到了这样的一段话:

JIT 对代码做了非常激进的优化。
其实回到我们的文章中,final 关键字的加上与否,表象上看是生成了两套不同的机器码,而本质上还是 final 关键字阻止了 JIT 进行激进的优化。

标签:...,里面,留言,程序,414,flag,天前,Java,final 来源: https://www.cnblogs.com/thisiswhy/p/14750596.html