[golang]golang 汇编
作者:互联网
https://lrita.github.io/2017/12/12/golang-asm/#why
在某些场景下,我们需要进行一些特殊优化,因此我们可能需要用到golang汇编,golang汇编源于plan9,此方面的 介绍很多,就不进行展开了。我们WHY和HOW开始讲起。
golang汇编相关的内容还是很少的,而且多数都语焉不详,而且缺乏细节。对于之前没有汇编经验的人来说,是很难 理解的。而且很多资料都过时了,包括官方文档的一些细节也未及时更新。因此需要掌握该知识的人需要仔细揣摩, 反复实验。
WHY
我们为什么需要用到golang的汇编,基本出于以下场景。
- 算法加速,golang编译器生成的机器码基本上都是通用代码,而且 优化程度一般,远比不上C/C++的
gcc/clang生成的优化程度高,毕竟时间沉淀在那里。因此通常我们需要用到特 殊优化逻辑、特殊的CPU指令让我们的算法运行速度更快,如sse4_2/avx/avx2/avx-512等。 - 摆脱golang编译器的一些约束,如通过汇编调用其他package的私有函数。
- 进行一些hack的事,如通过汇编适配其他语言的ABI来直接调用其他语言的函数。
- 利用
//go:noescape进行内存分配优化,golang编译器拥有逃逸分析,用于决定每一个变量是分配在堆内存上 还是函数栈上。但是有时逃逸分析的结果并不是总让人满意,一些变量完全可以分配在函数栈上,但是逃逸分析将其 移动到堆上,因此我们需要使用golang编译器的go:noescape将其转换,强制分配在函数栈上。当然也可以强制让对象分配在堆上,可以参见这段实现。
HOW
使用到golang会汇编时,golang的对象类型、buildin对象、语法糖还有一些特殊机制就都不见了,全部底层实现 暴露在我们面前,就像你拆开一台电脑,暴露在你面前的是一堆PCB、电阻、电容等元器件。因此我们必须掌握一些 go ABI的机制才能进行golang汇编编程。
go汇编简介
这部分内容可以参考:
寄存器
go 汇编中有4个核心的伪寄存器,这4个寄存器是编译器用来维护上下文、特殊标识等作用的:
- FP(Frame pointer): arguments and locals
- PC(Program counter): jumps and branches
- SB(Static base pointer): global symbols
- SP(Stack pointer): top of stack
所有用户空间的数据都可以通过FP(局部数据、输入参数、返回值)或SB(全局数据)访问。 通常情况下,不会对SB/FP寄存器进行运算操作,通常情况以会以SB/FP作为基准地址,进行偏移解引用 等操作。
SB
而且在某些情况下SB更像一些声明标识,其标识语句的作用。例如:
TEXT runtime·_divu(SB), NOSPLIT, $16-0在这种情况下,TEXT、·、SB共同作用声明了一个函数runtime._divu,这种情况下,不能对SB进行解引用。GLOBL fast_udiv_tab<>(SB), RODATA, $64在这种情况下,GLOBL、fast_udiv_tab、SB共同作用, 在RODATA段声明了一个私有全局变量fast_udiv_tab,大小为64byte,此时可以对SB进行偏移、解引用。CALL runtime·callbackasm1(SB)在这种情况下,CALL、runtime·callbackasm1、SB共同标识, 标识调用了一个函数runtime·callbackasm1。MOVW $fast_udiv_tab<>-64(SB), RM在这种情况下,与2类似,但不是声明,是解引用全局变量fast_udiv_tab。
FB
FP伪寄存器用来标识函数参数、返回值。其通过symbol+offset(FP)的方式进行使用。例如arg0+0(FP)表示第函数第一个参数其实的位置(amd64平台),arg1+8(FP)表示函数参数偏移8byte的另一个参数。arg0/arg1用于助记,但是必须存在,否则 无法通过编译。至于这两个参数是输入参数还是返回值,得对应其函数声明的函数个数、位置才能知道。 如果操作命令是MOVQ arg+8(FP), AX的话,MOVQ表示对8byte长的内存进行移动,其实位置是函数参数偏移8byte 的位置,目的是寄存器AX,因此此命令为将一个参数赋值给寄存器AX,参数长度是8byte,可能是一个uint64,FP 前面的arg+是标记。至于FP的偏移怎么计算,会在后面的go函数调用中进行表述。同时我们 还可以在命令中对FP的解引用进行标记,例如first_arg+0(FP)将FP的起始标记为参数first_arg,但是 first_arg只是一个标记,在汇编中first_arg是不存在的。
PC
实际上就是在体系结构的知识中常见的pc寄存器,在x86平台下对应ip寄存器,amd64上则是rip。除了个别跳转 之外,手写代码与PC寄存器打交道的情况较少。
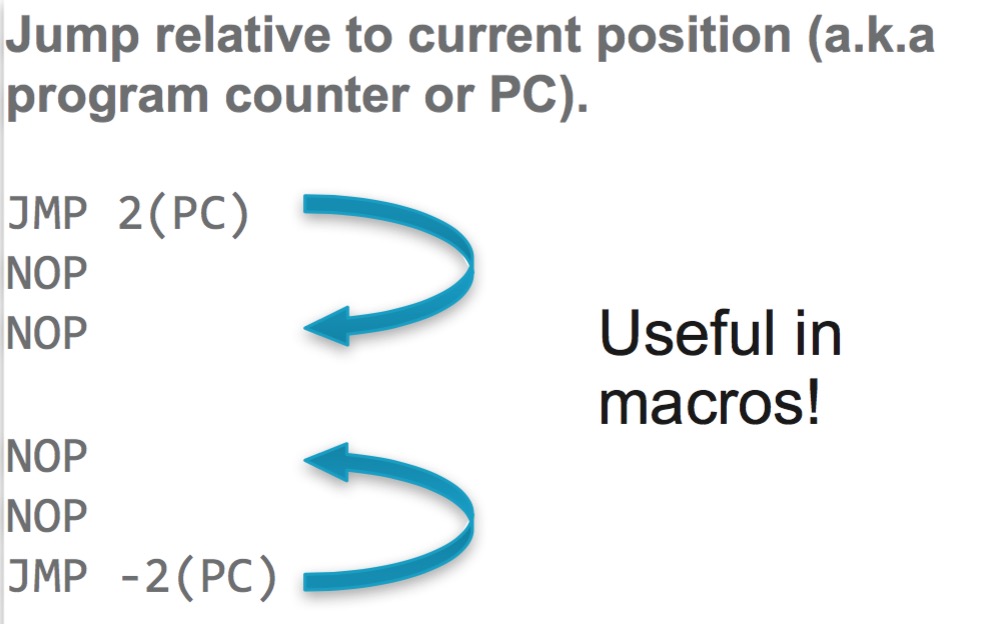
SP
SP是栈指针寄存器,指向当前函数栈的栈顶,通过symbol+offset(SP)的方式使用。offset 的合法取值是 [-framesize, 0),注意是个左闭右开的区间。假如局部变量都是8字节,那么第一个局部变量就可以用localvar0-8(SP) 来表示。
但是硬件寄存器中也有一个SP。在用户手写的汇编代码中,如果操作SP寄存器时没有带symbol前缀,则操作的是 硬件寄存器SP。在实际情况中硬件寄存器SP与伪寄存器SP并不指向同一地址,具体硬件寄存器SP指向哪里与函 数
但是:
对于编译输出(go tool compile -S / go tool objdump)的代码来讲,目前所有的SP都是硬件寄存器SP,无论 是否带 symbol。
我们这里对容易混淆的几点简单进行说明:
- 伪
SP和硬件SP不是一回事,在手写代码时,伪SP和硬件SP的区分方法是看该SP前是否有symbol。如果有symbol,那么即为伪寄存器,如果没有,那么说明是硬件SP寄存器。 - 伪
SP和FP的相对位置是会变的,所以不应该尝试用伪SP寄存器去找那些用FP+offset来引用的值,例如函数的 入参和返回值。 - 官方文档中说的伪
SP指向stack的top,是有问题的。其指向的局部变量位置实际上是整个栈的栈底(除caller BP 之外),所以说bottom更合适一些。 - 在
go tool objdump/go tool compile -S输出的代码中,是没有伪SP和FP寄存器的,我们上面说的区分伪SP和硬件SP寄存器的方法,对于上述两个命令的输出结果是没法使用的。在编译和反汇编的结果中,只有真实的SP寄 存器。 FP和Go的官方源代码里的framepointer不是一回事,源代码里的framepointer指的是caller BP寄存器的值, 在这里和caller的伪SP是值是相等的。
注: 如何理解伪寄存器FP和SP呢?其实伪寄存器FP和SP相当于plan9伪汇编中的一个助记符,他们是根据当前函数栈空间计算出来的一个相对于物理寄存器SP的一个偏移量坐标。当在一个函数中,如果用户手动修改了物理寄存器SP的偏移,则伪寄存器FP和SP也随之发生对应的偏移。例如
// func checking()(before uintptr, after uintptr)
TEXT ·checking(SB),$4112-16
LEAQ x-0(SP), DI //
MOVQ DI, before+0(FP) // 将原伪寄存器SP偏移量存入返回值before
MOVQ SP, BP // 存储物理SP偏移量到BP寄存器
ADDQ $4096, SP // 将物理SP偏移增加4K
LEAQ x-0(SP), SI
MOVQ BP, SP // 恢复物理SP,因为修改物理SP后,伪寄存器FP/SP随之改变,
// 为了正确访问FP,先恢复物理SP
MOVQ SI, cpu+8(FP) // 将偏移后的伪寄存器SP偏移量存入返回值after
RET
// 从输出的after-before来看,正好相差4K
通用寄存器
在plan9汇编里还可以直接使用的amd64的通用寄存器,应用代码层面会用到的通用寄存器主要是: rax, rbx, rcx, rdx, rdi, rsi, r8~r15这14个寄存器,虽然rbp和rsp也可以用,不过bp和sp会被用来管 理栈顶和栈底,最好不要拿来进行运算。plan9中使用寄存器不需要带r或e的前缀,例如rax,只要写AX即可:
MOVQ $101, AX = mov rax, 101下面是通用通用寄存器的名字在 IA64 和 plan9 中的对应关系:
| X86_64 | rax | rbx | rcx | rdx | rdi | rsi | rbp | rsp | r8 | r9 | r10 | r11 | r12 | r13 | r14 | rip |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Plan9 | AX | BX | CX | DX | DI | SI | BP | SP | R8 | R9 | R10 | R11 | R12 | R13 | R14 | PC |
控制流
对于函数控制流的跳转,是用label来实现的,label只在函数内可见,类似goto语句:
next:
MOVW $0, R1
JMP next
指令
使用汇编就意味着丧失了跨平台的特性。因此使用对应平台的汇编指令。这个需要自行去了解,也可以参考GoFunctionsInAssembly 其中有各个平台汇编指令速览和对照。
文件命名
使用到汇编时,即表明了所写的代码不能够跨平台使用,因此需要针对不同的平台使用不同的汇编 代码。go编译器采用文件名中加入平台名后缀进行区分。
比如sqrt_386.s sqrt_amd64p32.s sqrt_amd64.s sqrt_arm.s
或者使用+build tag也可以,详情可以参考go/build。
函数声明
首先我们先需要对go汇编代码有一个抽象的认识,因此我们可以先看一段go汇编代码:
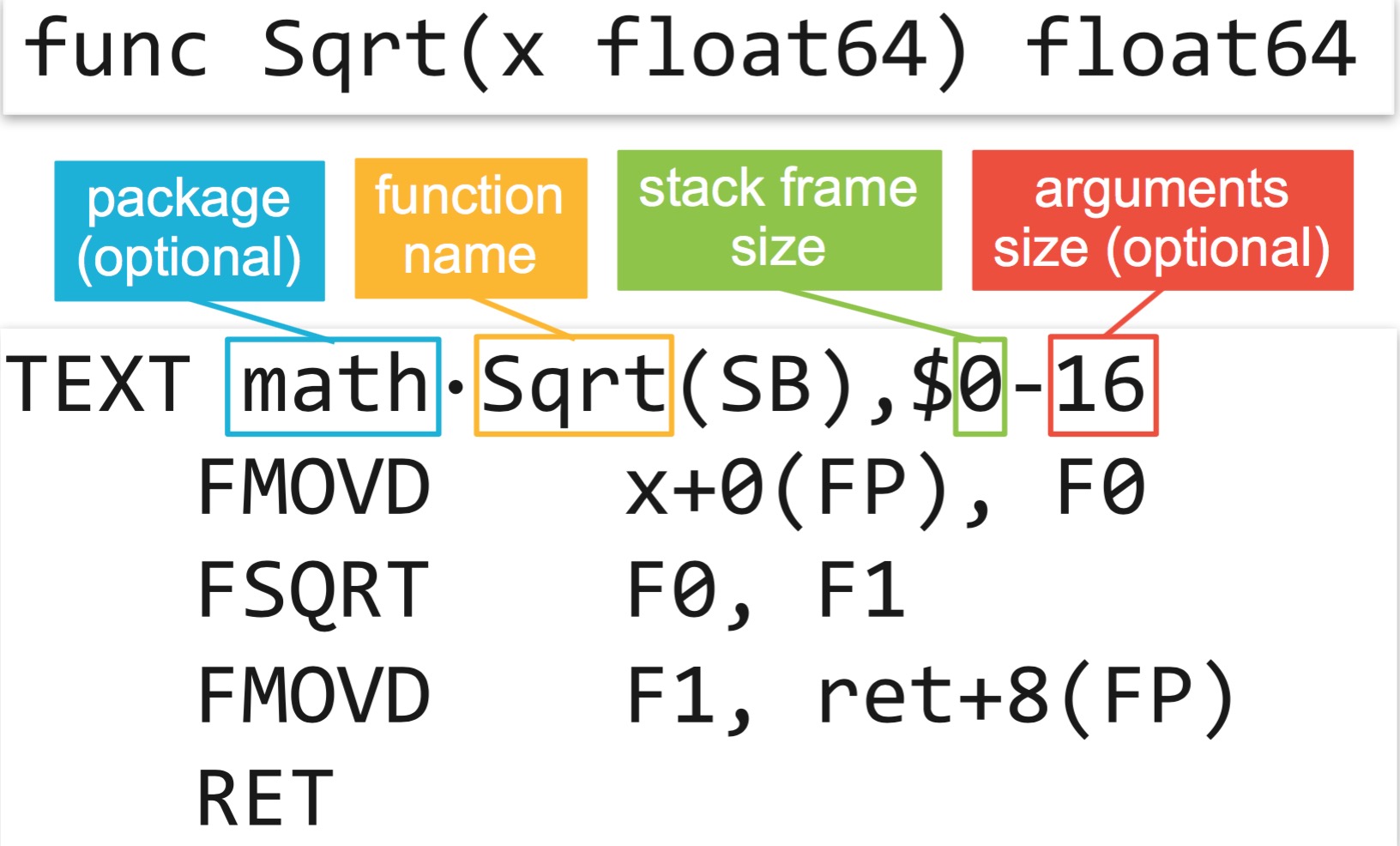
TEXT runtime·profileloop(SB),NOSPLIT,$8-16
MOVQ $runtime·profileloop1(SB), CX
MOVQ CX, 0(SP)
CALL runtime·externalthreadhandler(SB)
RET
此处声明了一个函数profileloop,函数的声明以TEXT标识开头,以${package}·${function}为函数名。 如何函数属于本package时,通常可以不写${package},只留·${function}即可。·在mac上可以用shift+option+9 打出。$8表示该函数栈大小为8byte,计算栈大小时,需要考虑局部变量和本函数内调用其他函数时,需要传参的空间,不含函数返回地址和CALLER BP(这2个后面会讲到)。 $16表示该函数入参和返回值一共有16byte。当有NOSPLIT标识时,可以不写输入参数、返回值占用的大小。
那我们再看一个函数:
TEXT ·add(SB),$0-24
MOVQ x+0(FP), BX
MOVQ y+8(FP), BP
ADDQ BP, BX
MOVQ BX, ret+16(FP)
RET
该函数等同于:
func add(x, y int64) int64 {
return x + y
}该函数没有局部变量,故$后第一个数为0,但其有2个输入参数,1个返回值,每个值占8byte,则第二个数为24(3*8byte)。
全局变量声明
以下就是一个私有全局变量的声明,<>表示该变量只在该文件内全局可见。 全局变量的数据部分采用DATA symbol+offset(SB)/width, value格式进行声明。
DATA divtab<>+0x00(SB)/4, $0xf4f8fcff // divtab的前4个byte为0xf4f8fcff
DATA divtab<>+0x04(SB)/4, $0xe6eaedf0 // divtab的4-7个byte为0xe6eaedf0
...
DATA divtab<>+0x3c(SB)/4, $0x81828384 // divtab的最后4个byte为0x81828384
GLOBL divtab<>(SB), RODATA, $64 // 全局变量名声明,以及数据所在的段"RODATA",数据的长度64byte
GLOBL runtime·tlsoffset(SB), NOPTR, $4 // 声明一个全局变量tlsoffset,4byte,没有DATA部分,因其值为0。
// NOPTR 表示这个变量数据中不存在指针,GC不需要扫描。
类似RODATA/NOPTR的特殊声明还有:
- NOPROF = 1 (For TEXT items.) Don’t profile the marked function. This flag is deprecated.
- DUPOK = 2 It is legal to have multiple instances of this symbol in a single binary. The linker will choose one of the duplicates to use.
- NOSPLIT = 4 (For TEXT items.) Don’t insert the preamble to check if the stack must be split. The frame for the routine, plus anything it calls, must fit in the spare space at the top of the stack segment. Used to protect routines such as the stack splitting code itself.
- RODATA = 8 (For DATA and GLOBL items.) Put this data in a read-only section.
- NOPTR = 16 (For DATA and GLOBL items.) This data contains no pointers and therefore does not need to be scanned by the garbage collector.
- WRAPPER = 32 (For TEXT items.) This is a wrapper function and should not count as disabling recover.
- NEEDCTXT = 64 (For TEXT items.) This function is a closure so it uses its incoming context register.
局部变量声明
局部变量存储在函数栈上,因此不需要额外进行声明,在函数栈上预留出空间,使用命令操作这些内存即可。因此这些 局部变量没有标识,操作时,牢记局部变量的分布、内存偏移即可。
宏
在汇编文件中可以定义、引用宏。通过#define get_tls(r) MOVQ TLS, r类似语句来定义一个宏,语法结构与C语言类似;通过#include "textflag.h"类似语句来引用一个外部宏定义文件。
go编译器为了方便汇编中访问struct的指定字段,会在编译过程中自动生成一个go_asm.h文件,可以通过#include "go_asm.h"语言来引用,该文件中会生成该包内全部struct的每个字段的偏移量宏定义与结构体大小的宏定义,比如:
type vdsoVersionKey struct {
version string
verHash uint32
}会生成宏定义:
#define vdsoVersionKey__size 24
#define vdsoVersionKey_version 0
#define vdsoVersionKey_verHash 16
在汇编代码中,我们就可以直接使用这些宏:
MOVQ vdsoVersionKey_version(DX) AX
MOVQ (vdsoVersionKey_version+vdsoVersionKey_verHash)(DX) AX
比如我们在runtime包中经常会看见一些代码就是如此:
MOVQ DX, m_vdsoPC(BX)
LEAQ ret+0(SP), DX
MOVQ DX, m_vdsoSP(BX)
我们可以通过命令go tool compile -S -asmhdr dump.h *.go来导出相关文件编译过程中会生成的宏定义。
地址运算
字段部分引用自《plan9-assembly-完全解析》:
地址运算也是用 lea 指令,英文原意为
Load Effective Address,amd64 平台地址都是8个字节,所以直接就用LEAQ就好:
LEAQ (BX)(AX*8), CX
// 上面代码中的 8 代表 scale
// scale 只能是 0、2、4、8
// 如果写成其它值:
// LEAQ (BX)(AX*3), CX
// ./a.s:6: bad scale: 3
// 整个表达式含义是 CX = BX + (AX * 8)
// 如果要表示3倍的乘法可以表示为:
LEAQ (AX)(AX*2), CX // => CX = AX + (AX * 2) = AX * 3
// 用 LEAQ 的话,即使是两个寄存器值直接相加,也必须提供 scale
// 下面这样是不行的
// LEAQ (BX)(AX), CX
// asm: asmidx: bad address 0/2064/2067
// 正确的写法是
LEAQ (BX)(AX*1), CX
// 在寄存器运算的基础上,可以加上额外的 offset
LEAQ 16(BX)(AX*1), CX
// 整个表达式含义是 CX = 16 + BX + (AX * 8)
// 三个寄存器做运算,还是别想了
// LEAQ DX(BX)(AX*8), CX
// ./a.s:13: expected end of operand, found (
其余MOVQ等表达式的区别是,在寄存器加偏移的情况下MOVQ会对地址进行解引用:
MOVQ (AX), BX // => BX = *AX 将AX指向的内存区域8byte赋值给BX
MOVQ 16(AX), BX // => BX = *(AX + 16)
MOVQ AX, BX // => BX = AX 将AX中存储的内容赋值给BX,注意区别
buildin类型
在golang汇编中,没有struct/slice/string/map/chan/interface{}等类型,有的只是寄存器、内存。因此我们需要了解这些 类型对象在汇编中是如何表达的。
(u)int??/float??
uint32就是32bit长的一段内存,float64就是64bit长的一段内存,其他相似类型可以以此类推。
int/unsafe.Pointer/unint
在32bit系统中int等同于int32,uintptr等同于uint32,unsafe.Pointer长度32bit。
在64bit系统中int等同于int64,uintptr等同于uint64,unsafe.Pointer长度64bit。
byte等同于uint8。rune等同于int32。
string底层是StringHeader 这样一个结构体,slice底层是SliceHeader 这样一个结构体。
map
map是指向hmap 的一个unsafe.Pointer
chan
chan是指向hchan 的一个unsafe.Pointer
interface{}
interface{}是eface 这样一个结构体。详细可以参考深入解析GO
go函数调用
通常函数会有输入输出,我们要进行编程就需要掌握其ABI,了解其如何传递输入参数、返回值、调用函数。
go汇编使用的是caller-save模式,因此被调用函数的参数、返回值、栈位置都需要由调用者维护、准备。因此 当你需要调用一个函数时,需要先将这些工作准备好,方能调用下一个函数,另外这些都需要进行内存对其,对其 的大小是sizeof(uintptr)。
我们将结合一些函数来进行说明:
无局部变量的函数
注意:其实go函数的栈布局在是否有局部变量时,是没有区别的。在没有局部变量时,只是少了局部变量那部分空间。在当时研究的时候,未能抽象其共同部分,导致拆成2部分写了。
对于手写汇编来说,所有参数通过栈来传递,通过伪寄存器FP偏移进行访问。函数的返回值跟随在输入参数 后面,并且对其到指针大小。amd64平台上指针大小为8byte。如果输入参数为20byte。则返回值会在从24byte其, 中间跳过4byte用以对其。
func xxx(a, b, c int) (e, f, g int) {
e, f, g = a, b, c
return
}该函数有3个输入参数、3个返回值,假设我们使用x86_64平台,因此一个int占用8byte。则其函数栈空间为:
高地址位
┼───────────┼
│ 返回值g │
┼───────────┼
│ 返回值f │
┼───────────┼
│ 返回值e │
┼───────────┼
│ 参数之c │
┼───────────┼
│ 参数之b │
┼───────────┼
│ 参数之a │
┼───────────┼ <-- 伪FP
│ 函数返回地址│
┼───────────┼ <-- 伪SP 和 硬件SP
低地址位
各个输入参数和返回值将以倒序的方式从高地址位分布于栈空间上,由于没有局部变量,则xxx的函数栈空间为 0,根据前面的描述,该函数应该为:
#include "textflag.h"
TEXT ·xxx(SB),NOSPLIT,$0-48
MOVQ a+0(FP), AX // FP+0 为参数a,将其值拷贝到寄存器AX中
MOVQ AX, e+24(FP) // FP+24 为返回值e,将寄存器AX赋值给返回值e
MOVQ b+8(FP), AX // FP+8 为参数b
MOVQ AX, f+32(FP) // FP+24 为返回值f
MOVQ c+16(FP), AX // FP+16 为参数c
MOVQ AX, g+40(FP) // FP+24 为返回值g
RET // return
然后在一个go源文件(.go)中声明该函数即可
func xxx(a, b, c int) (e, f, g int)有局部变量的函数
当函数中有局部变量时,函数的栈空间就应该留出足够的空间:
func zzz(a, b, c int) [3]int{
var d [3]int
d[0], d[1], d[2] = a, b, c
return d
}当函数中有局部变量时,我们就需要移动函数栈帧来进行栈内存分配,因此我们就需要了解相关平台计算机体系 的一些设计问题,在此我们只讲解x86平台的相关要求,我们先需要参考:
其中讲到x86平台上BP寄存器,通常用来指示函数栈的起始位置,仅仅其一个指示作用,现代编译器生成的代码 通常不会用到BP寄存器,但是可能某些debug工具会用到该寄存器来寻找函数参数、局部变量等。因此我们写汇编 代码时,也最好将栈起始位置存储在BP寄存器中。因此在amd64平台上,会在函数返回值之后插入8byte来放置CALLER BP寄存器。
此外需要注意的是,CALLER BP是在编译期由编译器插入的,用户手写代码时,计算framesize时是不包括这个 CALLER BP部分的,但是要计算函数返回值的8byte。是否插入CALLER BP的主要判断依据是:
- 函数的栈帧大小大于
0 - 下述函数返回
truefunc Framepointer_enabled(goos, goarch string) bool { return framepointer_enabled != 0 && goarch == "amd64" && goos != "nacl" }
此处需要注意,go编译器会将函数栈空间自动加8,用于存储BP寄存器,跳过这8字节后才是函数栈上局部变量的内存。 逻辑上的FP/SP位置就是我们在写汇编代码时,计算偏移量时,FP/SP的基准位置,因此局部变量的内存在逻辑SP的低地 址侧,因此我们访问时,需要向负方向偏移。
实际上,在该函数被调用后,编译器会添加SUBQ/LEAQ代码修改物理SP指向的位置。我们在反汇编的代码中能看到这部分操作,因此我们需要注意物理SP与伪SP指向位置的差别。
高地址位
┼───────────┼
│ 返回值g │
┼───────────┼
│ 返回值f │
┼───────────┼
│ 返回值e │
┼───────────┼
│ 参数之c │
┼───────────┼
│ 参数之b │
┼───────────┼
│ 参数之a │
┼───────────┼ <-- 伪FP
│ 函数返回地址│
┼───────────┼
│ CALLER BP │
┼───────────┼ <-- 伪SP
│ 变量之[2] │ <-- d0-8(SP)
┼───────────┼
│ 变量之[1] │ <-- d1-16(SP)
┼───────────┼
│ 变量之[0] │ <-- d2-24(SP)
┼───────────┼ <-- 硬件SP
低地址位
图中的函数返回地址使用的是调用者的栈空间,CALLER BP由编辑器“透明”插入,因此,不算在当前函数的栈空间内。我们实现该函数的汇编代码:
#include "textflag.h"
TEXT ·zzz(SB),NOSPLIT,$24-48 // $24值栈空间24byte,- 后面的48跟上面的含义一样,
// 在编译后,栈空间会被+8用于存储BP寄存器,这步骤由编译器自动添加
MOVQ $0, d-24(SP) // 初始化d[0]
MOVQ $0, d-16(SP) // 初始化d[1]
MOVQ $0, d-8(SP) // 初始化d[2]
MOVQ a+0(FP), AX // d[0] = a
MOVQ AX, d-24(SP) //
MOVQ b+8(FP), AX // d[1] = b
MOVQ AX, d-16(SP) //
MOVQ c+16(FP), AX // d[2] = c
MOVQ AX, d-8(SP) //
MOVQ d-24(SP), AX // d[0] = return [0]
MOVQ AX, r+24(FP) //
MOVQ d-16(SP), AX // d[1] = return [1]
MOVQ AX, r+32(FP) //
MOVQ d-8(SP), AX // d[2] = return [2]
MOVQ AX, r+40(FP) //
RET // return
然后我们go源码中声明该函数:
func zzz(a, b, c int) [3]int汇编中调用其他函数
在汇编中调用其他函数通常可以使用2中方式:
JMP含义为跳转,直接跳转时,与函数栈空间相关的几个寄存器SP/FP不会发生变化,可以理解为被调用函数 复用调用者的栈空间,此时,参数传递采用寄存器传递,调用者和被调用者协商好使用那些寄存传递参数,调用者将 参数写入这些寄存器,然后跳转到被调用者,被调用者从相关寄存器读出参数。具体实践可以参考1。CALL通过CALL命令来调用其他函数时,栈空间会发生响应的变化(寄存器SP/FP随之发生变化),传递参数时,我们需要输入参数、返回值按之前将的栈布局安排在调用者的栈顶(低地址段),然后再调用CALL命令来调用其函数,调用CALL命令后,SP寄存器会下移一个WORD(x86_64上是8byte),然后进入新函数的栈空间运行。下图中return addr(函数返回地址)不需要用户手动维护,CALL指令会自动维护。
下面演示一个CALL方法调用的例子:
func yyy(a, b, c int) [3]int {
return zzz(a, b, c)
}该函数使用汇编实现就是:
TEXT ·yyy0(SB), $48-48
MOVQ a+0(FP), AX
MOVQ AX, ia-48(SP)
MOVQ b+8(FP), AX
MOVQ AX, ib-40(SP)
MOVQ c+16(FP), AX
MOVQ AX, ic-32(SP)
CALL ·zzz(SB)
MOVQ z2-24(SP), AX
MOVQ AX, r2+24(FP)
MOVQ z1-16(SP), AX
MOVQ AX, r1+32(FP)
MOVQ z1-8(SP), AX
MOVQ AX, r2+40(FP)
RET
然后在go文件中声明yyy0,并且在main函数中调用:
func yyy0(a, b, c int) [3]int
//go:noinline
func yyy1(a, b, c int) [3]int {
return zzz(a, b, c)
}
func main() {
y0 := yyy0(1, 2, 3)
y1 := yyy1(1, 2, 3)
println("yyy0", y0[0], y0[1], y0[2])
println("yyy1", y1[0], y1[1], y1[2])
}在函数yyy0的栈空间分布为:
高地址位
┼───────────┼
│ 返回值[2] │ <-- r2+40(FP)
┼───────────┼
│ 返回值[1] │ <-- r1+32(FP)
┼───────────┼
│ 返回值[0] │ <-- r2+24(FP)
┼───────────┼
│ 参数之c │ <-- c+16(FP)
┼───────────┼
│ 参数之b │ <-- b+8(FP)
┼───────────┼
│ 参数之a │ <-- a+0(FP)
┼───────────┼ <-- 伪FP
│ 函数返回地址│ <-- yyy0函数返回值
┼───────────┼
│ CALLER BP │
┼───────────┼ <-- 伪SP
│ 返回值[2] │ <-- z1-8(SP)
┼───────────┼
│ 返回值[1] │ <-- z1-16(SP)
┼───────────┼
│ 返回值[0] │ <-- z2-24(SP)
┼───────────┼
│ 参数之c │ <-- ic-32(SP)
┼───────────┼
│ 参数之b │ <-- ib-40(SP)
┼───────────┼
│ 参数之a │ <-- ia-48(SP)
┼───────────┼ <-- 硬件SP
低地址位
其调用者和被调用者的栈关系为(该图来自plan9 assembly 完全解析):
caller
+------------------+
| |
+----------------------> --------------------
| | |
| | caller parent BP |
| BP(pseudo SP) --------------------
| | |
| | Local Var0 |
| --------------------
| | |
| | ....... |
| --------------------
| | |
| | Local VarN |
--------------------
caller stack frame | |
| callee arg2 |
| |------------------|
| | |
| | callee arg1 |
| |------------------|
| | |
| | callee arg0 |
| SP(Real Register) ----------------------------------------------+ FP(virtual register)
| | | |
| | return addr | parent return address |
+----------------------> +------------------+--------------------------- <-------------------------------+
| caller BP | |
| (caller frame pointer) | |
BP(pseudo SP) ---------------------------- |
| | |
| Local Var0 | |
---------------------------- |
| |
| Local Var1 |
---------------------------- callee stack frame
| |
| ..... |
---------------------------- |
| | |
| Local VarN | |
SP(Real Register) ---------------------------- |
| | |
| | |
| | |
| | |
| | |
+--------------------------+ <-------------------------------+
callee
此外我们还可以做一些优化,其中中间的临时变量,让zzz的输入参数、返回值复用yyy的输入参数、返回值 这部分空间,其代码为:
TEXT ·yyy(SB),NOSPLIT,$0-48
MOVQ pc+0(SP), AX // 将PC寄存器中的值暂时保存在最后一个返回值的位置,因为在
// 调用zzz时,该位置不会参与计算
MOVQ AX, ret_2+40(FP) //
MOVQ a+0(FP), AX // 将输入参数a,放置在栈顶
MOVQ AX, z_a+0(SP) //
MOVQ b+8(FP), AX // 将输入参数b,放置在栈顶+8
MOVQ AX, z_b+8(SP) //
MOVQ c+16(FP), AX // 将输入参数c,放置在栈顶+16
MOVQ AX, z_c+16(SP) //
CALL ·zzz(SB) // 调用函数zzz
MOVQ ret_2+40(FP), AX // 将PC寄存器恢复
MOVQ AX, pc+0(SP) //
MOVQ z_ret_2+40(SP), AX // 将zzz的返回值[2]防止在yyy返回值[2]的位置
MOVQ AX, ret_2+40(FP) //
MOVQ z_ret_1+32(SP), AX // 将zzz的返回值[1]防止在yyy返回值[1]的位置
MOVQ AX, ret_1+32(FP) //
MOVQ z_ret_0+24(SP), AX // 将zzz的返回值[0]防止在yyy返回值[0]的位置
MOVQ AX, ret_0+24(FP) //
RET // return
整个函数调用过程为:
高地址位
┼───────────┼ ┼────────────┼ ┼────────────┼
│ 返回值[2] │ │ 函数返回值 │ │ PC │
┼───────────┼ ┼────────────┼ ┼────────────┼
│ 返回值[1] │ │zzz返回值[2] │ │zzz返回值[2] │
┼───────────┼ ┼────────────┼ ┼────────────┼
│ 返回值[0] │ │zzz返回值[1] │ │zzz返回值[1] │
┼───────────┼ =调整后=> ┼────────────┼ =调用后=> ┼────────────┼
│ 参数之c │ │zzz返回值[0] │ │zzz返回值[0] │
┼───────────┼ ┼────────────┼ ┼────────────┼
│ 参数之b │ │ 参数之c │ │ 参数之c │
┼───────────┼ ┼────────────┼ ┼────────────┼
│ 参数之a │ <-- FP │ 参数之b │ <-- FP │ 参数之b │
┼───────────┼ ┼────────────┼ ┼────────────┼
│ 函数返回值 │ <-- SP │ 参数之a │ <-- SP │ 参数之a │ <--FP
┼───────────┼ ┼────────────┼ ┼────────────┼
│ 函数返回值 │ <--SP zzz函数栈空间
┼────────────┼
│ CALLER BP │
┼────────────┼
│ zzz变量之2 │
┼────────────┼
│ zzz变量之1 │
┼────────────┼
│ zzz变量之0 │
┼────────────┼
低地址位
然后我们可以使用反汇编来对比我们自己实现的汇编代码版本和go源码版本生成的汇编代码的区别:
我们自己汇编的版本:
TEXT main.yyy(SB) go/asm/xx.s
xx.s:31 0x104f6b0 488b0424 MOVQ 0(SP), AX
xx.s:32 0x104f6b4 4889442430 MOVQ AX, 0x30(SP)
xx.s:33 0x104f6b9 488b442408 MOVQ 0x8(SP), AX
xx.s:34 0x104f6be 48890424 MOVQ AX, 0(SP)
xx.s:35 0x104f6c2 488b442410 MOVQ 0x10(SP), AX
xx.s:36 0x104f6c7 4889442408 MOVQ AX, 0x8(SP)
xx.s:37 0x104f6cc 488b442418 MOVQ 0x18(SP), AX
xx.s:38 0x104f6d1 4889442410 MOVQ AX, 0x10(SP)
xx.s:39 0x104f6d6 e865ffffff CALL main.zzz(SB)
xx.s:40 0x104f6db 488b442430 MOVQ 0x30(SP), AX
xx.s:41 0x104f6e0 48890424 MOVQ AX, 0(SP)
xx.s:42 0x104f6e4 488b442428 MOVQ 0x28(SP), AX
xx.s:43 0x104f6e9 4889442430 MOVQ AX, 0x30(SP)
xx.s:44 0x104f6ee 488b442420 MOVQ 0x20(SP), AX
xx.s:45 0x104f6f3 4889442428 MOVQ AX, 0x28(SP)
xx.s:46 0x104f6f8 488b442418 MOVQ 0x18(SP), AX
xx.s:47 0x104f6fd 4889442420 MOVQ AX, 0x20(SP)
xx.s:48 0x104f702 c3 RET
go源码版本生成的汇编:
TEXT main.yyy(SB) go/asm/main.go
main.go:20 0x104f360 4883ec50 SUBQ $0x50, SP
main.go:20 0x104f364 48896c2448 MOVQ BP, 0x48(SP)
main.go:20 0x104f369 488d6c2448 LEAQ 0x48(SP), BP
main.go:20 0x104f36e 48c744247000000000 MOVQ $0x0, 0x70(SP)
main.go:20 0x104f377 48c744247800000000 MOVQ $0x0, 0x78(SP)
main.go:20 0x104f380 48c784248000000000000000 MOVQ $0x0, 0x80(SP)
main.go:20 0x104f38c 488b442458 MOVQ 0x58(SP), AX
main.go:21 0x104f391 48890424 MOVQ AX, 0(SP)
main.go:20 0x104f395 488b442460 MOVQ 0x60(SP), AX
main.go:21 0x104f39a 4889442408 MOVQ AX, 0x8(SP)
main.go:20 0x104f39f 488b442468 MOVQ 0x68(SP), AX
main.go:21 0x104f3a4 4889442410 MOVQ AX, 0x10(SP)
main.go:21 0x104f3a9 e892020000 CALL main.zzz(SB)
main.go:21 0x104f3ae 488b442418 MOVQ 0x18(SP), AX
main.go:21 0x104f3b3 4889442430 MOVQ AX, 0x30(SP)
main.go:21 0x104f3b8 0f10442420 MOVUPS 0x20(SP), X0
main.go:21 0x104f3bd 0f11442438 MOVUPS X0, 0x38(SP)
main.go:22 0x104f3c2 488b442430 MOVQ 0x30(SP), AX
main.go:22 0x104f3c7 4889442470 MOVQ AX, 0x70(SP)
main.go:22 0x104f3cc 0f10442438 MOVUPS 0x38(SP), X0
main.go:22 0x104f3d1 0f11442478 MOVUPS X0, 0x78(SP)
main.go:22 0x104f3d6 488b6c2448 MOVQ 0x48(SP), BP
main.go:22 0x104f3db 4883c450 ADDQ $0x50, SP
main.go:22 0x104f3df c3 RET
经过对比可以看出我们的优点:
- 没有额外分配栈空间
- 没有中间变量,减少了拷贝次数
- 没有中间变量的初始化,节省操作
go源码版本的优点:
- 对于连续内存使用了
MOVUPS命令优化,(此处不一定是优化,有时还会劣化,因为X86_64不同 指令集混用时,会产生额外开销)
我们可以运行一下go benchmark来比较一下两个版本,可以看出自己的汇编版本速度上明显快于go源码版本。
go test -bench=. -v -count=3
goos: darwin
goarch: amd64
BenchmarkYyyGoVersion-4 100000000 16.9 ns/op
BenchmarkYyyGoVersion-4 100000000 17.0 ns/op
BenchmarkYyyGoVersion-4 100000000 17.1 ns/op
BenchmarkYyyAsmVersion-4 200000000 10.1 ns/op
BenchmarkYyyAsmVersion-4 200000000 7.90 ns/op
BenchmarkYyyAsmVersion-4 200000000 8.01 ns/op
PASS
ok go/asm 13.005s
回调函数/闭包
var num int
func call(fn func(), n int) {
fn()
num += n
}
func basecall() {
call(func() {
num += 5
}, 1)
}如上面所示,当函数(call)参数中包含回调函数(fn)时,回调函数的指针通过一种简介方式传入,之所以采用这种设计也是为了照顾闭包调用的实现。接下来简单介绍一下这种传参。当一个函数的参数为一个函数时,其调用者与被调用者之间的关系如下图所示:
caller
+------------------+
| |
+----------------------> --------------------
| | |
| | caller parent BP |
| BP(pseudo SP) --------------------
| | |
| | Local Var0 |
| --------------------
| | |
| | ....... |
| --------------------
caller stack frame | |
| | Local VarN | ┼────────────┼
| |------------------| │ .... │ 如果是闭包时,可
| | | ┼────────────┼ 以扩展该区域存储
| | callee arg1(n) | │ .... │ 闭包中的变量。
| |------------------| ┼────────────┼
| | | ---->│ fn pointer │ 间接临时区域
| | callee arg0 | ┼────────────┼
| SP(Real Register) ----------------------------------------------+ FP(virtual register)
| | | |
| | return addr | parent return address |
+----------------------> +------------------+--------------------------- <-------------------------------+
| caller BP | |
| (caller frame pointer) | |
BP(pseudo SP) ---------------------------- |
| | |
| Local Var0 | |
---------------------------- |
| |
| Local Var1 |
---------------------------- callee stack frame
| |
| ..... |
---------------------------- |
| | |
| Local VarN | |
SP(Real Register) ---------------------------- |
| | |
| | |
+--------------------------+ <-------------------------------+
callee
在golang的ABI中,关于回调函数、闭包的上下文由调用者(caller-basecall)来维护,被调用者(callee-call)直接按照规定的格式来使用即可。
- 调用者需要申请一段临时内存区域来存储函数(
func() { num+=5 })的指针,当传递参数是闭包时,该临时内存区域开可以进行扩充,用于存储闭包中捕获的变量,通常编译器将该内存区域定义成型为struct { F uintptr; a *int }的结构。该临时内存区域可以分配在栈上,也可以分配在堆上,还可以分配在寄存器上。到底分配在哪里,需要编译器根据逃逸分析的结果来决定; - 将临时内存区域的地址存储于对应被调用函数入参的对应位置上;其他参数按照上面的常规方法放置;
- 使用
CALL执行调用被调用函数(callee-call); - 在被调用函数(
callee-call)中从对应参数位置中取出临时内存区域的指针存储于指定寄存器DX(仅针对amd64平台) - 然后从
DX指向的临时内存区域的首部取出函数(func() { num+=5 })指针,存储于AX(此处寄存器可以任意指定) - 然后在执行
CALL AX指令来调用传入的回调函数。 - 当回调函数是闭包时,需要使用捕获的变量时,直接通过集群器
DX加对应偏移量来获取。
下面结合几个例子来理解:
例一
func callback() {
println("xxx")
}
func call(fn func()) {
fn()
}
func call1() {
call(callback)
}
func call0()其中call0函数可以用汇编实现为:
TEXT ·call0(SB), $16-0 # 分配栈空间16字节,8字节为call函数的入参,8字节为间接传参的'临时内存区域'
LEAQ ·callback(SB), AX # 取·callback函数地址存储于'临时内存区域'
MOVQ AX, fn-8(SP) #
LEAQ fn-8(SP), AX # 取'临时内存区域'地址存储于call入参位置
MOVQ AX, fn-16(SP) #
CALL ·call(SB) # 调用call函数
RET
注意:如果我们使用go tool compile -l -N -S来获取call1的实现,可以的得到:
TEXT "".call1(SB), ABIInternal, $16-0
MOVQ (TLS), CX
CMPQ SP, 16(CX)
JLS 55
SUBQ $16, SP
MOVQ BP, 8(SP)
LEAQ 8(SP), BP
FUNCDATA $0, gclocals·33cdeccccebe80329f1fdbee7f5874cb(SB)
FUNCDATA $1, gclocals·33cdeccccebe80329f1fdbee7f5874cb(SB)
FUNCDATA $3, gclocals·9fb7f0986f647f17cb53dda1484e0f7a(SB)
PCDATA $2, $1
PCDATA $0, $0 # 以上是函数编译器生成的栈管理,不用理会
LEAQ "".callback·f(SB), AX # 这部分,貌似没有分配'临时内存区域'进行中转,
PCDATA $2, $0 # 而是直接将函数地址赋值给call的参数。然后按
MOVQ AX, (SP) # 照这样写,会出现SIGBUS错误。对比之下,其猫
CALL "".call(SB) # 腻可能出现在`callback·f`上,此处可能包含
MOVQ 8(SP), BP # 一些隐藏信息,因为手写汇编采用这种格式是会
ADDQ $16, SP # 编译错误的。
RET
例二
func call(fn func(), n int) {
fn()
}
func testing() {
var n int
call(func() {
n++
}, 1)
_ = n
}其生成的汇编为:
TEXT testing.func1(SB), NOSPLIT|NEEDCTXT, $16-0 # NEEDCTXT标识闭包
MOVQ 8(DX), AX # 从DX+8偏移出取出捕获参数n的指针
INCQ (AX) # 对参数n指针指向的内存执行++操作,n++
RET
TEXT testing(SB), NOSPLIT, $56-0
MOVQ $0, n+16(SP) # 初始化栈上临时变量n
XORPS X0, X0 # 清空寄存器X0
MOVUPS X0, autotmp_2+32(SP) # 用X0寄存器初始化栈上临时空间,该空间是分配给闭包的临时内存区域
LEAQ autotmp_2+32(SP), AX # 取临时内存区域指针到AX
MOVQ AX, autotmp_3+24(SP) # 不知道此步有何用意,liveness?
TESTB AL, (AX)
LEAQ testing.func1(SB), CX # 将闭包函数指针存储于临时内存区域首部
MOVQ CX, autotmp_2+32(SP)
TESTB AL, (AX)
LEAQ n+16(SP), CX # 将临时变量n的地址存储于临时内存区域尾部
MOVQ CX, autotmp_2+40(SP)
MOVQ AX, (SP) # 将临时内存区域地址赋值给call函数入参1
MOVQ $1, 8(SP) # 将立即数1赋值给call函数入参2
CALL call(SB) # 调用call函数
RET
# func call(fn func(), n int)
TEXT call(SB), NOSPLIT, $8-16
MOVQ "".fn+16(SP), DX # 取出临时区域的地址到DX
MOVQ (DX), AX # 对首部解引用获取函数指针,存储到AX
CALL AX # 调用闭包函数
RET
直接调用C函数(FFI)
我们都知道CGO is not Go,在go中调用C函数存在着巨大额外开销,而一些短小精悍的C函数,我们可以考虑绕过CGO机制,直接调用,比如runtime包中vDSO的调用、fastcgo、rustgo等。要直接调用C函数,就要遵循C的ABI。
amd64 C ABI
在调用C函数时,主流有2种ABI:
Windows x64 C and C++ ABI主要适用于各Windows平台System V ABI主要适用于Solaris, Linux, FreeBSD, macOS等。
在ABI规定中,涉及内容繁多,下面简单介绍一下System V ABI中参数传递的协议:
- 当参数都是整数时,参数少于7个时, 参数从左到右放入寄存器:
rdi,rsi,rdx,rcx,r8,r9 - 当参数都是整数时,参数为7个以上时, 前6个与前面一样, 但后面的依次从
右向左放入栈中,即和32位汇编一样H(a, b, c, d, e, f, g, h);
=>
a->%rdi, b->%rsi, c->%rdx, d->%rcx, e->%r8, f->%r9
h->8(%esp)
g->(%esp)
CALL H - 如果参数中包含浮点数时,会利用xmm寄存器传递浮点数,其他参数的位置按顺序排列

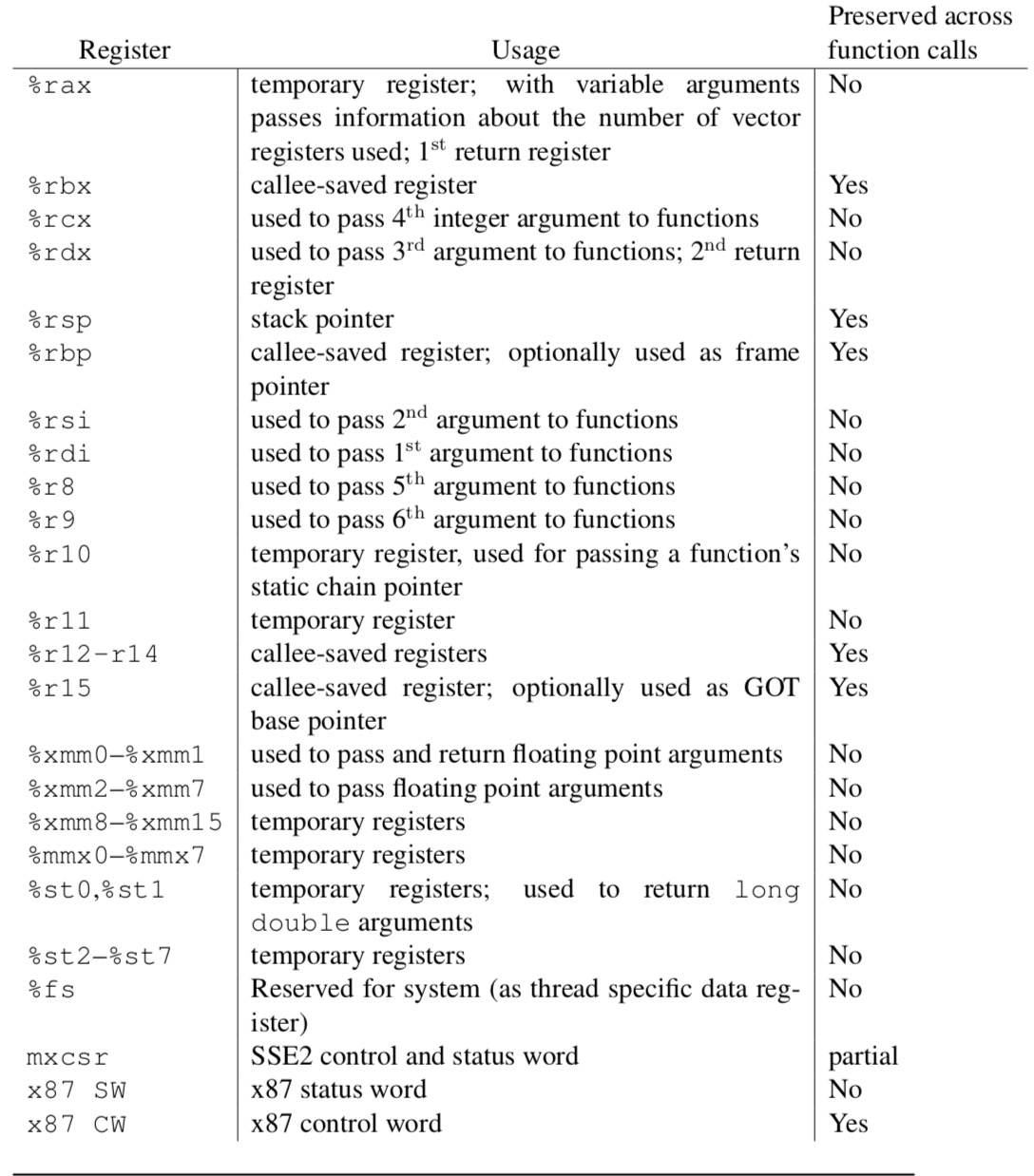
- 常用寄存器有16个,分为x86通用寄存器以及r8-r15寄存器
- 通用寄存器中,函数执行前后必须保持原始的寄存器有3个:是rbx、rbp、rsp
- rx寄存器中,最后4个必须保持原值:r12、r13、r14、r15(保持原值的意义是为了让当前函数有可信任的寄存器,减小在函数调用过程中的保存/恢复操作。除了rbp、rsp用于特定用途外,其余5个寄存器可随意使用。)

由于该issue的存在,通常goroutine的栈空间很小,很可能产生栈溢出的错误。解决的方法有:
- 直接切换到
g0栈,g0栈是系统原生线程的栈,通常比较大而且与C兼容性更好,切换g0栈的方式可以参考fastcgo中的实现,但是这有着强烈的版本依赖,不是很推荐; - 调用函数自身声明一个很大的栈空间,迫使goroutine栈扩张。具体参考方法可以参考rustgo,该方法不能确定每一个C函数具体的栈空间需求,只能根据猜测分配一个足够大的,同时也会造成比较大的浪费,也不推荐;
- 使用
runtime·systemstack切换到g0栈,同时摆脱了版本依赖。具体方法可以参考numa。
编译/反编译
因为go汇编的资料很少,所以我们需要通过编译、反汇编来学习。
// 编译
go build -gcflags="-S"
go tool compile -S hello.go
go tool compile -l -N -S hello.go // 禁止内联 禁止优化
// 反编译
go tool objdump <binary>
总结
了解go汇编并不是一定要去手写它,因为汇编总是不可移植和难懂的。但是它能够帮助我们了解go的一些底层机制, 了解计算机结构体系,同时我们需要做一些hack的事时可以用得到。
比如,我们可以使用go:noescape来减少内存的分配:
很多时候,我们可以使函数内计算过程使用栈上的空间做缓存,这样可以减少对内存的使用,并且是计算速度更快:
func xxx() int{
var buf [1024]byte
data := buf[:]
// do something in data
}
但是,很多时候,go编译器的逃逸分析并不让人满意,经常会使buf移动到堆内存上,造成不必要的内存分配。 这是我们可以使用sync.Pool,但是总让人不爽。因此我们使用汇编完成一个noescape函数,绕过go编译器的 逃逸检测,使buf不会移动到堆内存上。
// asm_amd64.s
#include "textflag.h"
TEXT ·noescape(SB),NOSPLIT,$0-48
MOVQ d_base+0(FP), AX
MOVQ AX, b_base+24(FP)
MOVQ d_len+8(FP), AX
MOVQ AX, b_len+32(FP)
MOVQ d_cap+16(FP),AX
MOVQ AX, b_cap+40(FP)
RET
//此处使用go编译器的指示
//go:noescape
func noescape(d []byte) (b []byte)
func xxx() int {
var buf [1024]byte
data := noescape(buf[:])
// do something in data
// 这样可以确保buf一定分配在xxx的函数栈上
}c2goasm
当我们需要做一些密集的数列运算或实现其他算法时,我们可以使用先进CPU的向量扩展指令集进行加速,如sse4_2/avx/avx2/avx-512等。有些人觉得通常可以遇不见这样的场景,其实能够用到这些的场景还是很多的。比如,我们常用的监控采集go-metrics库,其中就有很多可以优化的地方,如SampleSum、SampleMax、SampleMin这些函数都可以进行加速。
但是,虽然这些方法很简单,但是对于汇编基础很弱的人来说,手写这些sse4_2/avx/avx2/avx-512指令代码,仍然是很困难的。但是,我们可以利用clang/gcc这些深度优化过的C语言编译器来帮我们生成对于的汇编代码。
所幸,这项工作已经有人帮我们很好的完成了,那就是c2goasm。c2goasm可以将C/C++编译器生成的汇编代码转换为golang汇编代码。在这里,我们可以学习该工具如何使用。它可以帮助我们在代码利用上sse4_2/avx/avx2/avx-512等这些先进指令。但是这些执行需要得到CPU的支持。因此我们先要判断使用的CPU代码是否支持。
注意c2goasm中其中有很多默认规则需要我们去遵守:
- 我们先需要使用
clang将c源文件编译成汇编代码clang_c.s(该文件名随意); - 然后我们可以使用
c2goasm将汇编代码clang_c.s转换成go汇编源码xxx.s; - 我们每使用
c2goasm生成一个go汇编文件xxx.s之前,我们先添加一个对应的xxx.go的源码文件,其中需要包含xxx.s中函数的声明。 - 当c源码或者
clang_c.s源码中函数名称为func_xxx时,经过c2goasm转成的汇编函数会增加_前缀,变成_func_xxx,因此在xxx.go中的函数声明为_func_xxx。要求声明的_func_xxx函数的入参个数与原来C源码中的入参个数相等,且为每个64bit大小。此时go声明函数中需要需要使用slice/map时,需要进行额外的转化。如果函数有返回值,则声明对应的go函数时,返回值必须为named return,即返回值需要由()包裹,否则会报错:Badly formatted return argument .... - 如果我们需要生成多种指令的go汇编实现时,我们需要实现对应的多个c函数,因此我们可以使用c的宏辅助我们声明对应的c函数,避免重复的书写。
在linux上,我们可以使用命令cat /proc/cpuinfo |grep flags来查看CPU支持的指令集。但是在工作环境中,我们的代码需要在多个环境中运行,比如开发环境、和生产环境,这些环境之间可能会有很大差别,因此我们希望我们的代码可以动态支持不同的CPU环境。这里,我们可以用到intel-go/cpuid,我们可以实现多个指令版本的代码,然后根据运行环境中CPU的支持情况,选择实际实行哪一段逻辑:
package main
import (
"fmt"
"github.com/intel-go/cpuid"
)
func main() {
fmt.Println("EnabledAVX", cpuid.EnabledAVX)
fmt.Println("EnabledAVX512", cpuid.EnabledAVX512)
fmt.Println("SSE4_1", cpuid.HasFeature(cpuid.SSE4_1))
fmt.Println("SSE4_2", cpuid.HasFeature(cpuid.SSE4_2))
fmt.Println("AVX", cpuid.HasFeature(cpuid.AVX))
fmt.Println("AVX2", cpuid.HasExtendedFeature(cpuid.AVX2))
}然后,我们可以先使用C来实现这3个函数:
#include <stdint.h>
/* 我们要实现3中指令的汇编实现,因此我们需要生成3个版本的C代码,此处使用宏来辅助添加后缀,避免生成的函数名冲突 */
#if defined ENABLE_AVX2
#define NAME(x) x##_avx2
#elif defined ENABLE_AVX
#define NAME(x) x##_avx
#elif defined ENABLE_SSE4_2
#define NAME(x) x##_sse4_2
#endif
int64_t NAME(sample_sum)(int64_t *beg, int64_t len) {
int64_t sum = 0;
int64_t *end = beg + len;
while (beg < end) {
sum += *beg++;
}
return sum;
}
int64_t NAME(sample_max)(int64_t *beg, int64_t len) {
int64_t max = 0x8000000000000000;
int64_t *end = beg + len;
if (len == 0) {
return 0;
}
while (beg < end) {
if (*beg > max) {
max = *beg;
}
beg++;
}
return max;
}
int64_t NAME(sample_min)(int64_t *beg, int64_t len) {
if (len == 0) {
return 0;
}
int64_t min = 0x7FFFFFFFFFFFFFFF;
int64_t *end = beg + len;
while (beg < end) {
if (*beg < min) {
min = *beg;
}
beg++;
}
return min;
}
然后使用clang生成三中指令的汇编代码:
clang -S -DENABLE_SSE4_2 -target x86_64-unknown-none -masm=intel -mno-red-zone -mstackrealign -mllvm -inline-threshold=1000 -fno-asynchronous-unwind-tables -fno-exceptions -fno-rtti -O3 -fno-builtin -ffast-math -msse4 lib/sample.c -o lib/sample_sse4.s
clang -S -DENABLE_AVX -target x86_64-unknown-none -masm=intel -mno-red-zone -mstackrealign -mllvm -inline-threshold=1000 -fno-asynchronous-unwind-tables -fno-exceptions -fno-rtti -O3 -fno-builtin -ffast-math -mavx lib/sample.c -o lib/sample_avx.s
clang -S -DENABLE_AVX2 -target x86_64-unknown-none -masm=intel -mno-red-zone -mstackrealign -mllvm -inline-threshold=1000 -fno-asynchronous-unwind-tables -fno-exceptions -fno-rtti -O3 -fno-builtin -ffast-math -mavx2 lib/sample.c -o lib/sample_avx2.s
注意:此处目前有一个待解决的问题issues8,如果谁指定如何解决,请帮助我一下。使用clang生成的AVX2汇编代码,其中局部变量0x8000000000000000/0x7FFFFFFFFFFFFFFF会被分片到RODATA段,并且使用32byte对其。使用c2goasm转换时,会生成一个很大的全局变量(几个G…,此处会运行很久)。目前的解决方式是,将生成
.LCPI1_0:
.quad -9223372036854775808 # 0x8000000000000000
.section .rodata,"a",@progbits
.align 32
.LCPI1_1:
.long 0 # 0x0
.long 2 # 0x2
.long 4 # 0x4
.long 6 # 0x6
.zero 4
.zero 4
.zero 4
.zero 4
.text
.globl sample_max_avx2
改为:
.LCPI1_0:
.quad -9223372036854775808 # 0x8000000000000000
.quad -9223372036854775808 # 0x8000000000000000
.quad -9223372036854775808 # 0x8000000000000000
.quad -9223372036854775808 # 0x8000000000000000
.section .rodata,"a",@progbits
.LCPI1_1:
.long 0 # 0x0
.long 2 # 0x2
.long 4 # 0x4
.long 6 # 0x6
.zero 4
.zero 4
.zero 4
.zero 4
.text
.globl sample_max_avx2
.align 16, 0x90
.type sample_max_avx2,@function
另一处同理,具体修改后的结果为:sample_avx2.s
回归正题,添加对应的go函数声明,我们要生成的三个go汇编文件为:sample_sse4_amd64.s,sample_avx_amd64.s和sample_avx2_amd64.s,因此对应的三个go文件为:sample_sse4_amd64.go,sample_avx_amd64.go和sample_avx2_amd64.go。 其中声明的go函数为下面,我们挑其中一个文件说,其他两个类似:
package sample
import "unsafe"
// 声明的go汇编函数,不支持go buildin 数据类型,参数个数要与c实现的参数个数相等,最多支持14个。
//go:noescape
func _sample_sum_sse4_2(addr unsafe.Pointer, len int64) (x int64)
//go:noescape
func _sample_max_sse4_2(addr unsafe.Pointer, len int64) (x int64)
//go:noescape
func _sample_min_sse4_2(addr unsafe.Pointer, len int64) (x int64)
// 因为我们希望输入参数为一个slice,则我们在下面进行3个封装。
func sample_sum_sse4_2(v []int64) int64 {
x := (*slice)(unsafe.Pointer(&v))
return _sample_sum_sse4_2(x.addr, x.len)
}
func sample_max_sse4_2(v []int64) int64 {
x := (*slice)(unsafe.Pointer(&v))
return _sample_max_sse4_2(x.addr, x.len)
}
func sample_min_sse4_2(v []int64) int64 {
x := (*slice)(unsafe.Pointer(&v))
return _sample_min_sse4_2(x.addr, x.len)
}有了这些函数声明,我们就可以使用c2goasm进行转换了:
c2goasm -a -f lib/sample_sse4.s sample_sse4_amd64.s
c2goasm -a -f lib/sample_avx.s sample_avx_amd64.s
c2goasm -a -f lib/sample_avx2.s sample_avx2_amd64.s
然后我们添加一段初始化逻辑,根据CPU支持的指令集来选择使用对应的实现:
import (
"math"
"unsafe"
"github.com/intel-go/cpuid"
)
var (
// SampleSum returns the sum of the slice of int64.
SampleSum func(values []int64) int64
// SampleMax returns the maximum value of the slice of int64.
SampleMax func(values []int64) int64
// SampleMin returns the minimum value of the slice of int64.
SampleMin func(values []int64) int64
)
func init() {
switch {
case cpuid.EnabledAVX && cpuid.HasExtendedFeature(cpuid.AVX2):
SampleSum = sample_sum_avx2
SampleMax = sample_max_avx2
SampleMin = sample_min_avx2
case cpuid.EnabledAVX && cpuid.HasFeature(cpuid.AVX):
SampleSum = sample_sum_avx
SampleMax = sample_max_avx
SampleMin = sample_min_avx
case cpuid.HasFeature(cpuid.SSE4_2):
SampleSum = sample_sum_sse4_2
SampleMax = sample_max_sse4_2
SampleMin = sample_min_sse4_2
default:
// 纯go实现
SampleSum = sampleSum
SampleMax = sampleMax
SampleMin = sampleMin
}
}此时我们的工作就完成了,我们可以使用go test的benchmark来进行比较,看看跟之前的纯go实现,性能提升了多少:
name old time/op new time/op delta
SampleSum-4 519ns ± 1% 53ns ± 2% -89.72% (p=0.000 n=10+9)
SampleMax-4 676ns ± 2% 183ns ± 2% -73.00% (p=0.000 n=10+10)
SampleMin-4 627ns ± 1% 180ns ± 1% -71.27% (p=0.000 n=10+9)
我们可以看出,sum方法得到10倍的提升,max/min得到了3倍多的提升,可能是因为max/min方法中每次循环中都有一次分支判断的原因,导致其提升效果不如sum方法那么多。
完整的实现在lrita/c2goasm-example
RDTSC精确计时
在x86架构的CPU上,每个CPU上有一个单调递增的时间戳寄存器,可以帮助我们精确计算每一段逻辑的精确耗时,其调用代价和计时精度远远优于time.Now(),在runtime中有着广泛应用,可以参考runtime·cputicks的实现。在但是对于指令比较复杂的函数逻辑并不适用于此方法,因为该寄存器时与CPU核心绑定,每个CPU核心上的寄存器可能并不一致,如果被测量的函数比较长,在运行过程中很可能发生CPU核心/线程的调度,使该函数在执行的过程中被调度到不同的CPU核心上,这样测量前后取到的时间戳不是来自于同一个寄存器,从而造成比较大的误差。
还要注意的是RDTSC并不与其他指令串行,为了保证计时的准确性,需要在调用RDTSC前增加对应的内存屏障,保证其准确性。
参考
- A Quick Guide to Go’s Assembler
- 解析 Go 中的函数调用
- A Manual for the Plan 9 assembler
- Golang中的Plan9汇编器
- GoFunctionsInAssembly
- plan9 assembly 完全解析
- InfluxData is Building a Fast Implementation of Apache Arrow in Go Using c2goasm and SIMD
- RDTSC指令
标签:FP,汇编,函数,SP,golang,go,AX,MOVQ 来源: https://www.cnblogs.com/landv/p/11589074.html