AI系统——梯度累积算法
作者:互联网
- 明天博士论文要答辩了,只有一张12G二手卡,今晚通宵要搞定10个模型实验
- 挖槽,突然想出一个T9开天霹雳模型,加载不进去我那张12G的二手卡,感觉要错过今年上台Best Paper领奖
 上面出现的问题主要是机器不够、内存不够用。在深度学习训练的时候,数据的batch size大小受到GPU内存限制,batch size大小会影响模型最终的准确性和训练过程的性能。在GPU内存不变的情况下,模型越来越大,那么这就意味着数据的batch size智能缩小,这个时候,梯度累积(Gradient Accumulation)可以作为一种简单的解决方案来解决这个问题。
下面这个图中橙色部分HERE就是梯度累积算法在AI系统中的大致位置,一般在AI框架/AI系统的表达层,跟算法结合比较紧密。
上面出现的问题主要是机器不够、内存不够用。在深度学习训练的时候,数据的batch size大小受到GPU内存限制,batch size大小会影响模型最终的准确性和训练过程的性能。在GPU内存不变的情况下,模型越来越大,那么这就意味着数据的batch size智能缩小,这个时候,梯度累积(Gradient Accumulation)可以作为一种简单的解决方案来解决这个问题。
下面这个图中橙色部分HERE就是梯度累积算法在AI系统中的大致位置,一般在AI框架/AI系统的表达层,跟算法结合比较紧密。
Batch size的作用
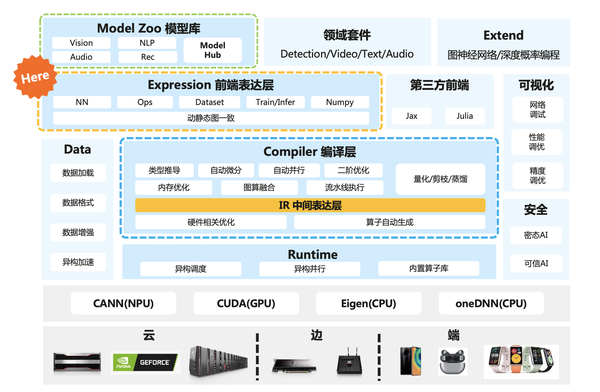
训练数据的Batch size大小对训练过程的收敛性,以及训练模型的最终准确性具有关键影响。通常,每个神经网络和数据集的Batch size大小都有一个最佳值或值范围。
不同的神经网络和不同的数据集可能有不同的最佳Batch size大小。选择Batch size的时候主要考虑两个问题: 泛化性:大的Batch size可能陷入局部最小值。陷入局部最小值则意味着神经网络将在训练集之外的样本上表现得很好,这个过程称为泛化。因此,泛化性一般表示过度拟合。 收敛速度:小的Batch size可能导致算法学习收敛速度慢。网络模型在每个Batch的更新将会确定下一次Batch的更新起点。每次Batch都会训练数据集中,随机抽取训练样本,因此所得到的梯度是基于部分数据噪声的估计。在单次Batch中使用的样本越少,梯度估计准确度越低。换句话说,较小的Batch size可能会使学习过程波动性更大,从本质上延长算法收敛所需要的时间。 考虑到上面两个主要的问题,所以在训练之前需要选择一个合适的Batch size。
Batch size对内存的影响
虽然传统计算机在CPU上面可以访问大量RAM,还可以利用SSD进行二级缓存或者虚拟缓存机制。但是如GPU等AI加速芯片上的内存要少得多。这个时候训练数据Batch size的大小对GPU的内存有很大影响。 为了进一步理解这一点,让我们首先检查训练时候AI芯片内存中内存的内容:- 模型参数:网络模型需要用到的权重参数和偏差。
- 优化器变量:优化器算法需要的变量,例如动量momentum。
- 中间计算变量:网络模型计算产生的中间值,这些值临时存储在AI加速芯片的内存中,例如,每层激活的输出。
- 工作区Workspace:AI加速芯片的内核实现是需要用到的局部变量,其产生的临时内存,例如算子D=A+B/C中B/C计算时产生的局部变量。
使用大Batch size的方法
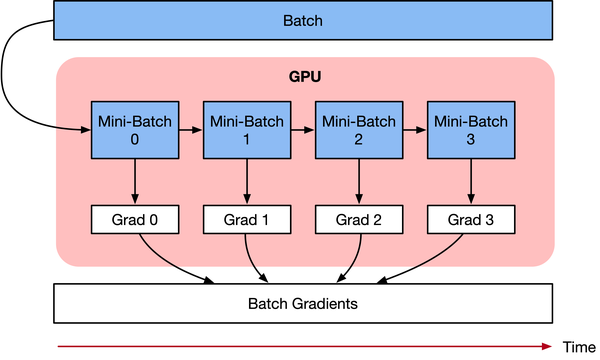
解决AI加速芯片内存限制,并运行大Batch size的一种方法是将数据Sample的Batch拆分为更小的Batch,叫做Mini-Batch。这些小Mini-Batch可以独立运行,并且在网络模型训练的时候,对梯度进行平均或者求和。主要实现有两种方式。 1)数据并行:使用多个AI加速芯片并行训练所有Mini-Batch,每份数据都在单个AI加速芯片上。累积所有Mini-Batch的梯度,结果用于在每个Epoch结束时求和更新网络参数。 2)梯度累积:按顺序执行Mini-Batch,同时对梯度进行累积,累积的结果在最后一个Mini-Batch计算后求平均更新模型变量。 虽然两种技术都挺像的,解决的问题都是内存无法执行更大的Batch size,但梯度累积可以使用单个AI加速芯片就可以完成啦,而数据并行则需要多块AI加速芯片,所以手头上只有一台12G二手卡的同学们赶紧把梯度累积用起来。梯度累积原理
梯度累积是一种训练神经网络的数据Sample样本按Batch拆分为几个小Batch的方式,然后按顺序计算。 在进一步讨论梯度累积之前,我们来看看神经网络的计算过程。 深度学习模型由许多相互连接的神经网络单元所组成,在所有神经网络层中,样本数据会不断向前传播。在通过所有层后,网络模型会输出样本的预测值,通过损失函数然后计算每个样本的损失值(误差)。神经网络通过反向传播,去计算损失值相对于模型参数的梯度。最后这些梯度信息用于对网络模型中的参数进行更新。 优化器用于对网络模型模型权重参数更新的数学公式。以一个简单随机梯度下降(SGD)算法为例。 假设Loss Function函数公式为:在构建模型时,优化器用于计算最小化损失的算法。这里SGD算法利用Loss函数来更新权重参数公式为:
其中theta是网络模型中的可训练参数(权重或偏差),lr是学习率,grad是相对于网络模型参数的损失。 梯度累积则是只计算神经网络模型,但是并不及时更新网络模型的参数,同时在计算的时候累积计算时候得到的梯度信息,最后统一使用累积的梯度来对参数进行更新。
在不更新模型变量的时候,实际上是把原来的数据Batch分成几个小的Mini-Batch,每个step中使用的样本实际上是更小的数据集。 在N个step内不更新变量,使所有Mini-Batch使用相同的模型变量来计算梯度,以确保计算出来得到相同的梯度和权重信息,算法上等价于使用原来没有切分的Batch size大小一样。即:
最终在上面步骤中累积梯度会产生与使用全局Batch size大小相同的梯度总和。
 当然在实际工程当中,关于调参和算法上有两点需要注意的:
当然在实际工程当中,关于调参和算法上有两点需要注意的:
学习率 learning rate:一定条件下,Batch size越大训练效果越好,梯度累积则模拟了batch size增大的效果,如果accumulation steps为4,则Batch size增大了4倍,根据ZOMI的经验,使用梯度累积的时候需要把学习率适当放大。 归一化 Batch Norm:accumulation steps为4时进行Batch size模拟放大效果,和真实Batch size相比,数据的分布其实并不完全相同,4倍Batch size的BN计算出来的均值和方差与实际数据均值和方差不太相同,因此有些实现中会使用Group Norm来代替Batch Norm。
梯度累积实现
正常训练一个batch的伪代码:for i, (images, labels) in enumerate(train_data):
# 1. forwared 前向计算
outputs = model(images)
loss = criterion(outputs, labels)
# 2. backward 反向传播计算梯度
optimizer.zero_grad()
loss.backward()
optimizer.step()
- model(images) 输入图像和标签,前向计算。
- criterion(outputs, labels) 通过前向计算得到预测值,计算损失函数。
- ptimizer.zero_grad() 清空历史的梯度信息。
- loss.backward() 进行反向传播,计算当前batch的梯度。
- optimizer.step() 根据反向传播得到的梯度,更新网络参数。
# 梯度累加参数
accumulation_steps = 4
for i, (images, labels) in enumerate(train_data):
# 1. forwared 前向计算
outputs = model(imgaes)
loss = criterion(outputs, labels)
# 2.1 loss regularization loss正则化
loss += loss / accumulation_steps
# 2.2 backward propagation 反向传播计算梯度
loss.backward()
# 3. update parameters of net
if ((i+1) % accumulation)==0:
# optimizer the net
optimizer.step()
optimizer.zero_grad() # reset grdient
- model(images) 输入图像和标签,前向计算。
- criterion(outputs, labels) 通过前向计算得到预测值,计算损失函数。
- loss / accumulation_steps loss每次更新,因此每次除以steps累积到原梯度上。
- loss.backward() 进行反向传播,计算当前batch的梯度。
- 多次循环伪代码步骤1-2,不清空梯度,使梯度累加在历史梯度上。
- optimizer.step() 梯度累加一定次数后,根据所累积的梯度更新网络参数。
- optimizer.zero_grad() 清空历史梯度,为下一次梯度累加做准备。
参考文献
- [1] Hermans, Joeri R., Gerasimos Spanakis, and Rico Möckel. "Accumulated gradient normalization." Asian Conference on Machine Learning. PMLR, 2017.
- [2] Lin, Yujun, et al. "Deep gradient compression: Reducing the communication bandwidth for distributed training." arXiv preprint arXiv:1712.01887 (2017).
- [3] how-to-break-gpu-memory-boundaries-even-with-large-batch-sizes
- [4] what-is-gradient-accumulation-in-deep-learning
标签:累积,AI,梯度,模型,Batch,算法,size 来源: https://www.cnblogs.com/ZOMI/p/15779676.html