python机器量化之十七:混淆矩阵(confusion_matrix)含义
作者:互联网
1.混淆矩阵是机器学习中总结分类模型预测结果的情形分析表,以矩阵形式将数据集中的记录按照真实的类别与分类模型预测的类别判断两个标准进行汇总
2.分类评估指标中定义的一些符号含义:
TP(True Positive) :将正类预测为正类数,真实为0,预测为0
FN(False Negative):将正类预测为负类数,真实为0,预测为1
FP(False Positive) :将负类预测为正类数,真实为1,预测为0
TN(True Negative) :将负类预测为负类数,真实为1,预测为1
3.矩阵表现形式:
(注:矩阵的行表示真实值,列表示预测值)
二分类:
| 混淆矩阵 | 预测值 | ||
| 0 | 1 | ||
| 真实值 | 0 | a | b |
| 1 | c | d | |
于是有: TP = a; FN = b; FP = c; TN = d.
$Precision$=$\frac{a}{a+c}$=$\frac{TP}{TP+FP}$,
$Recall$=$\frac{a}{a+b}$=$\frac{TP}{TP+FN}$,
$Accuracy$=$\frac{a+d}{a+b+c+d}$=$\frac{TP+TN}{TP+FN+FP+TN}$,
$F1$=$2*\frac{Recall*Accuracy}{Recall + Accuracy} $

知乎详细说明有兴趣的朋友可以看下:
我们假设某计算机学院有这么一个班级,班上有40人,全是男程序员。大一的时候大家全都是单身。他们的辅导员在班会上做了这么一个预测,“到了大二,班上的张三,李四,老王等5位同学会有女朋友! 剩下的狗剩,二蛋,大头等35个同学,可能还要再等几年。”
好的,这个时候我们可以把这位辅导员的预测写成下面这张表:


到了大二,大家把这张表拿出来一核对,在被预计有女朋友的人里,发现除了老王,其他人还真的有了女朋友;在预计没有女朋友的人里,发现狗剩跟二蛋因为代码写得好,竟然也有了女朋友。
这个时候,我们上面的表加工一下,可以得到下面这张表:


稍微解释一下上面这张表。
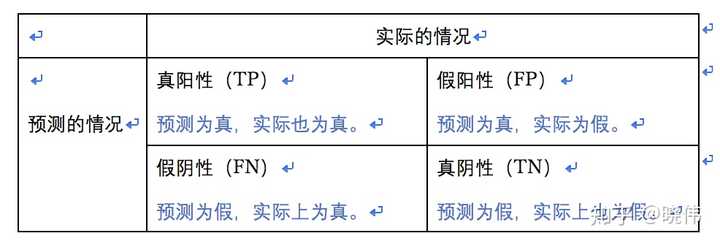
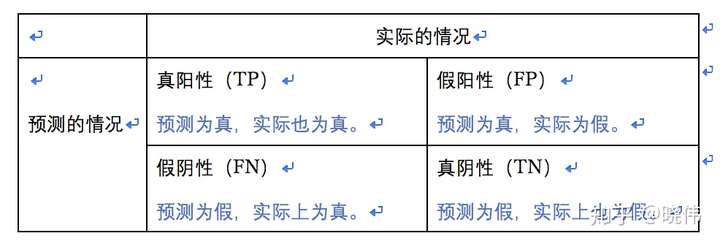
左上角的数据1表示“被辅导员预计有女朋友,并且实际上也有了女朋友的人数”,一共有4位。在数据分析中,我们一般把这部分的数据叫做真阳性(True Positive,简称TP),也就是预计为真,实际上也为真的数据。在数据分析里,我们常常把预计会发生的事件叫做阳,而把预计不会发生的事件叫做阴。
右上角的数据2表示“被辅导员预计有女朋友,但是实际上并没有的人数”,也就是老王一个人。在数据分析中,我们把这部分的数据叫做假阳性(False Positive, 简称FP),也就是预计为真,但实际上为假的数据。
左下角的数据3表示“被辅导员预计没有女朋友,但实际上找到了女朋友的人数”,这里有狗剩和二蛋两个人。在数据分析中,我们把这部分的数据叫做假阴性(False Negative, 简称FN), 也就是预计为假,但实际上为真的数据。
右下角的数据4表示“被辅导员预计没有女朋友,实际上也确实没有女朋友的人数”,这里有大头等33个人。在数据分析中,我们把这部分的数据叫做真阴性(True Negative, 简称TN),也就是预计为假,实际上也为假的数据。
我们可以把上面提到的表格简化成下面这个样子:
我们再做进一步地简化,把它写成矩阵的样子:


你看,这个能表示预测值和真实值之间的差距的矩阵,就是我们想要的混淆矩阵了。
作者:晓伟
链接:https://www.zhihu.com/question/36883196/answer/557746605
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
标签:辅导员,frac,matrix,python,confusion,矩阵,TP,女朋友,预测 来源: https://www.cnblogs.com/gzhbk/p/15774871.html